In biology, a heterotroph is an organism that cannot produce its own food and must instead consume organic substances from its environment to survive. In the modern technological landscape, we are witnessing the rise of “digital heterotrophs.” These are complex software systems, artificial intelligence models, and big data architectures that, unlike simple “autotrophic” scripts that generate predictable outputs from internal logic, rely entirely on the ingestion, processing, and “metabolism” of external data.
To understand how these digital entities function, we must examine the architectural processes they use to break down raw information into actionable insights. Just as a biological organism uses mechanical and chemical digestion, a technology stack uses ingestion pipelines, ETL (Extract, Transform, Load) processes, and machine learning inference to convert raw data—the “food”—into “energy” or strategic intelligence.

The Ingestion Phase: How Systems Consume External Data
Before a system can break down information, it must first consume it. In the tech world, this is known as data ingestion. Digital heterotrophs are constantly “hungry” for high-quality, high-velocity data from a variety of external sources, ranging from IoT sensors and social media feeds to legacy enterprise databases.
APIs as the Primary Consumption Mechanism
Application Programming Interfaces (APIs) serve as the “mouth” of the digital heterotroph. They are the standardized interfaces through which a system requests and receives data from the outside world. Whether it is a financial app pulling stock market prices or a weather platform receiving satellite updates, the API provides a structured way to bring external nutrients into the system’s internal environment. Modern tech stacks prioritize RESTful or GraphQL APIs to ensure that the data consumed is as clean and accessible as possible.
Streaming and Batch Processing
Not all consumption happens at the same speed. Digital heterotrophs use two primary methods for taking in data:
- Batch Processing: This is akin to a large meal. The system collects data over a period of time and processes it all at once (e.g., end-of-day bank reconciliations).
- Stream Processing: This is continuous consumption. Using tools like Apache Kafka or Amazon Kinesis, systems “sip” data in real-time, allowing them to react instantly to environmental changes. This is vital for fraud detection systems and autonomous vehicles that require a constant “metabolic” flow of information.
Dealing with Unstructured Raw Material
Just as a biological organism must deal with fiber and bone, a digital system often encounters unstructured data like images, audio files, and PDFs. These are the most difficult “nutrients” to break down. Modern tech architectures utilize Object Storage (like Amazon S3) to hold this raw material until it can be properly processed by specialized AI “enzymes” designed to extract meaning from the chaos.
The ETL Pipeline: Mechanical and Chemical Digestion of Information
Once data has been ingested, it must be broken down. In technology, this process is predominantly handled by the ETL (Extract, Transform, Load) pipeline. This is the core digestive tract of the digital heterotroph, where raw, unusable data is converted into a format that the system’s “cells” (algorithms) can actually use.
Data Cleaning: Filtering Out Toxins
The first step in breaking down data is removing “noise” or “garbage.” Incomplete records, duplicate entries, and corrupted packets are like toxins in a biological system. Data cleaning involves validation checks that ensure the information is accurate and relevant. If a digital heterotroph “eats” poor-quality data without this filtering process, it suffers from “Garbage In, Garbage Out,” leading to system failures or biased AI outputs.
Transformation: The Chemical Breakdown
This is where the actual “breaking down” occurs. During transformation, data is converted from its raw state into a standardized schema. This might involve:
- Normalization: Ensuring all dates, currencies, and units of measurement are identical.
- Aggregation: Summarizing large data sets into smaller, more manageable chunks.
- Parsing: Breaking down a complex string of text (like a JSON file or a log report) into individual fields that a database can index.
This transformation process is essentially the chemical digestion of the tech world, turning complex “macromolecules” of data into “simple sugars” that the system can easily absorb.
Loading into the Data Warehouse
The final stage of the ETL process is loading the transformed data into a data warehouse or data lake (such as Snowflake or Google BigQuery). This represents the absorption of nutrients into the bloodstream. Once stored here, the data is “bioavailable”—it is ready to be used by analysts, developers, and machine learning models to drive the organization forward.
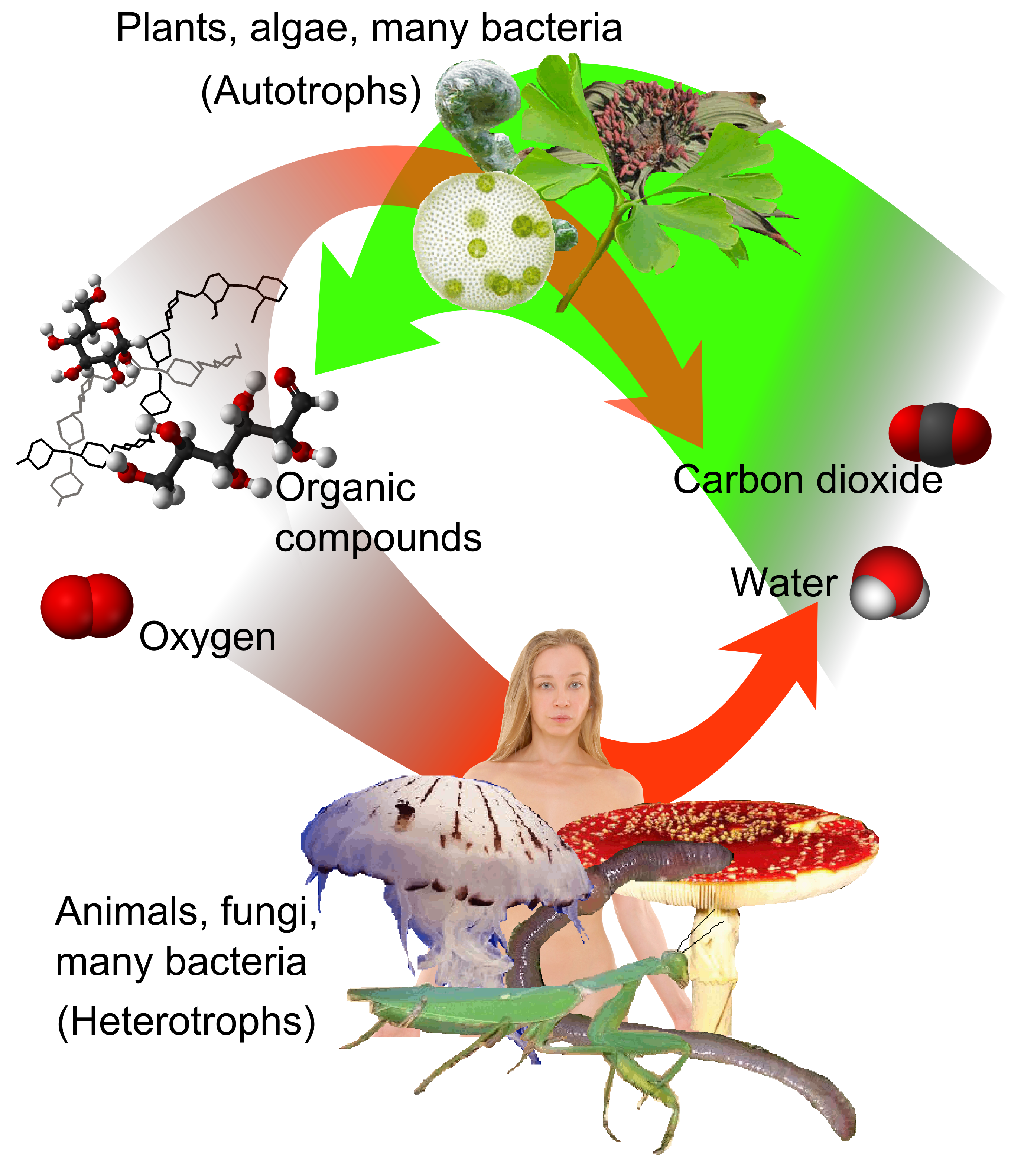
Neural Metabolism: How AI Converts Data into Intelligence
For advanced digital heterotrophs, such as Large Language Models (LLMs) and predictive analytics engines, simply storing data is not enough. They must convert that data into “energy”—which, in the tech niche, equates to intelligence and predictive power. This process is analogous to cellular respiration.
Feature Engineering: Extracting the Essence
In machine learning, “feature engineering” is the process of selecting the most important parts of the data to feed into a model. Just as an organism extracts specific vitamins from food, an AI model extracts “features” (specific variables) from a data set. For a credit scoring AI, these features might be payment history and debt-to-income ratio. By breaking down the massive data set into these essential features, the model can operate efficiently without being overwhelmed by irrelevant information.
Model Inference: The Expenditure of Energy
The “breaking down” process culminates in inference. This is when the system uses its digested data to make a decision or a prediction. When you ask an AI a question, it “metabolizes” your prompt, compares it against the massive “food stores” of data it has previously ingested, and produces an output. This requires significant computational power, which is the literal electricity that fuels the digital organism’s metabolic processes.
Continuous Learning Loops
A healthy digital heterotroph never stops digesting. Through “reinforcement learning,” systems take the results of their own actions, treat them as new data (feedback), and break them down to improve future performance. This creates a circular metabolism where the system grows smarter and more efficient the more it “eats.”
Cybersecurity and System Maintenance: Protecting the Metabolic Flow
No organism can survive if its digestive tract is compromised or if it is attacked by pathogens. In the technology sector, the process of breaking down data must be protected by robust security protocols and maintenance schedules.
Data Governance and the Immune System
Data governance acts as the immune system for a digital heterotroph. It sets the rules for what data can be “eaten” and who is allowed to “digest” it. With regulations like GDPR and CCPA, systems must be careful not to ingest “forbidden” data (private user information without consent). An immune response—in the form of automated compliance alerts—prevents the system from processing data that could lead to legal or ethical “sickness.”
Encryption: Protecting Nutrients in Transit
Just as nutrients must be protected as they travel through an organism, data must be encrypted while “in transit” and “at rest.” This ensures that even if a malicious actor intercepts the data during the ingestion or transformation phase, they cannot “digest” it themselves. Encryption turns the data into an unbreakable substance for anyone without the correct cryptographic “enzyme” (the key).
Latency Optimization: Ensuring Metabolic Speed
If a heterotroph takes too long to break down its food, it becomes sluggish and vulnerable. In tech, this is the problem of latency. Engineers optimize the “digestive” process by using edge computing—moving the processing closer to the data source. By breaking down data at the “edge” (on a smartphone or an IoT device), the system avoids the slow “transit time” to a central server, allowing for near-instant metabolism.

The Future of Autonomous Data Metabolism
As we move toward a world of more advanced AI and autonomous systems, the way digital heterotrophs break down their food is becoming increasingly sophisticated. We are moving away from manual ETL processes toward “AutoML” and self-healing data pipelines.
In the future, digital heterotrophs will likely possess the ability to “forage” for their own data, identifying new sources of information and automatically developing the “enzymes” (code) required to break them down. These self-optimizing systems will represent the pinnacle of technological evolution, creating a world where software doesn’t just process data—it lives off it, growing and evolving in real-time.
By understanding the processes of ingestion, transformation, and inference, we gain a clearer picture of the digital heterotroph. These systems are not just tools; they are complex entities that require a constant, well-processed diet of data to provide the intelligence that drives our modern world. Whether through the “mouth” of an API or the “stomach” of a data warehouse, the process of breaking down data remains the most critical function of any modern technology stack.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.