In the world of empirical research, a “control” is the anchor of any experiment—the constant that remains unchanged to provide a baseline for comparison. Without it, the results of an experiment are merely observations without context. In the rapidly evolving landscape of technology, this scientific principle has been adapted into a cornerstone of software engineering, artificial intelligence training, and digital infrastructure management. Whether we are discussing A/B testing a new user interface or calibrating a generative AI model, the “control” serves as the standard of truth that ensures innovation is measurable, reliable, and secure.
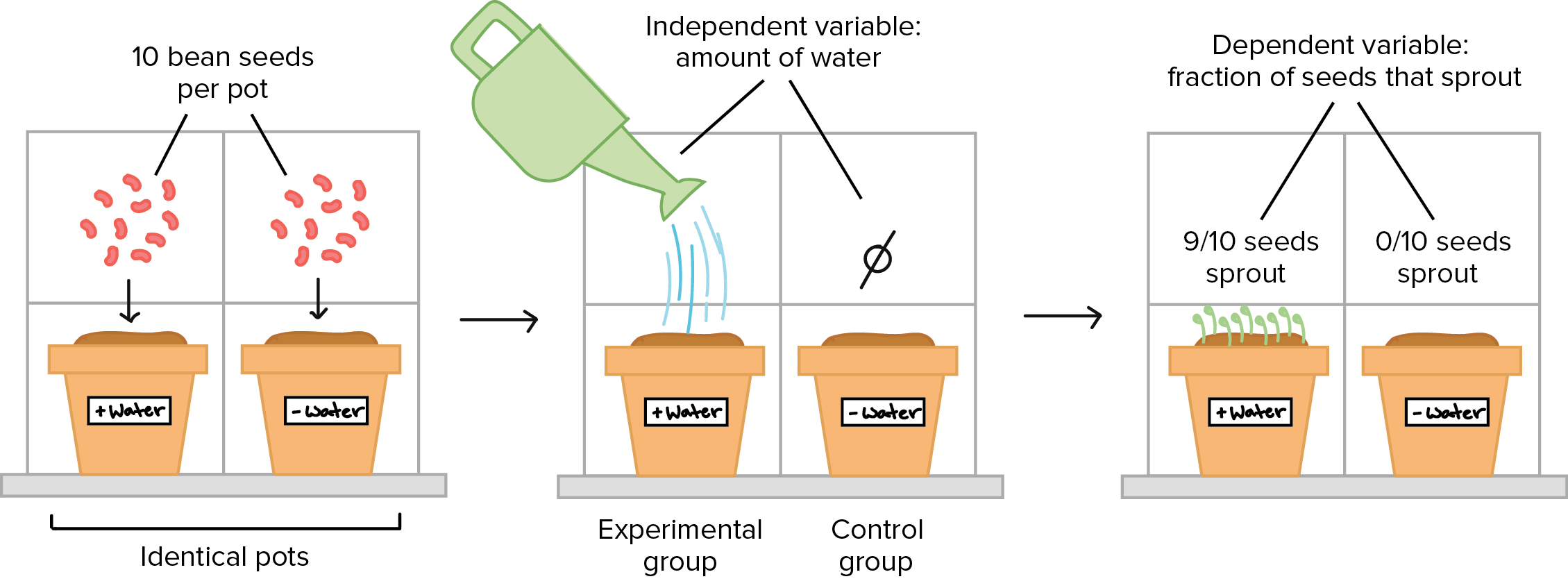
This article explores how the concept of a scientific control is applied across the tech industry to drive precision, maintain security, and optimize performance in an increasingly complex digital ecosystem.
Defining the “Control” in Software Development and AI Training
In a traditional science project, the control group receives no treatment, allowing researchers to see what happens naturally versus what happens under the influence of a variable. In the tech sector, this translates to maintaining a “steady state” against which new code, features, or algorithms are measured.
A/B Testing: The Digital Science Experiment
A/B testing is perhaps the most direct application of the “control” concept in the tech world. When a company like Netflix or Amazon wants to change a button color or an algorithm recommendation, they do not roll it out to all users at once. Instead, they divide their audience.
The “Control Group” (Group A) continues to use the existing version of the software. The “Experimental Group” (Group B) interacts with the new feature. By keeping all other variables constant—such as the time of day, user demographics, and device types—engineers can determine if a 5% increase in click-through rate was truly caused by the change or if it was merely a statistical fluke. Without this control, developers would be making blind decisions based on correlation rather than causation.
Training Data vs. Validation Sets in Machine Learning
In the realm of Artificial Intelligence, the “control” takes the form of benchmark datasets and validation sets. When training a Neural Network, engineers use a specific set of data to teach the model patterns. However, to understand if the model is actually learning or just “memorizing” (overfitting), they use a control set—data the model has never seen before.
Furthermore, “Control Models” are used to measure the efficacy of new architectures. If a data scientist develops a new Large Language Model (LLM), they must test its performance against a “Baseline Model” (the control) using standardized benchmarks like MMLU (Massive Multitask Language Understanding). If the new model doesn’t outperform the control under identical conditions, the technological “variable” has failed.
Quality Control (QC) and Assurance in Modern Engineering
As software systems grow in complexity, the “control” shifts from a research tool to a protective barrier. Quality Control (QC) in tech refers to the set of procedures intended to ensure that a manufactured product or performed service adheres to a defined set of quality criteria or meets the requirements of the client.
Continuous Integration/Continuous Deployment (CI/CD) as a Control Mechanism
In modern DevOps, the CI/CD pipeline acts as an automated laboratory. Every time a developer submits a “Pull Request” to change the code, the system automatically compares the new code against the “Main Branch”—which serves as the operational control.
Automated testing suites act as the control parameters. If the new code causes a “regression” (a failure in previously working features), the “control” has been violated, and the deployment is halted. This ensures that the production environment remains stable, providing a consistent experience for the end-user while allowing for rapid innovation.
Regression Testing: Maintaining the Functional Baseline
Regression testing is the tech equivalent of a scientist re-checking their control group to ensure no external factors have contaminated the experiment. Whenever a system is updated or a bug is fixed, engineers run regression tests to ensure that the fundamental baseline of the software remains intact.
In this context, the “control” is the expected output of the system. If you change the payment gateway of an e-commerce app, the “control” expectation is that the user’s cart should still calculate taxes correctly. By strictly defining these control behaviors, tech firms avoid the “cascading failure” effect, where a small change in one area destroys the functionality of another.

Controls in Digital Security and Cybersecurity Infrastructure
In cybersecurity, a “control” isn’t just a comparison point; it is a defensive measure. Security controls are the safeguards or countermeasures avoided by an organization to minimize risk and protect the integrity of data.
Zero Trust Architecture: The Ultimate Access Control
The “Zero Trust” model is a technological philosophy that treats every entry point as a variable that must be validated against a strict control policy. In traditional networking, once you were inside the perimeter, you were trusted. In a Zero Trust environment, the “Control Plane” manages all identities and permissions.
The control here is the “Policy of Least Privilege.” By setting a baseline where no user has access to anything by default, security teams can measure deviations from normal behavior. If an employee who typically accesses marketing files suddenly attempts to download encrypted financial databases, the system identifies this as a deviation from the control behavior and triggers an alert.
Behavioral Baselines in Threat Detection
Modern cybersecurity tools use AI to establish a “Behavioral Control” for every user and device on a network. By monitoring a system for several weeks, the software learns what “normal” looks like—what time a user logs in, what files they access, and how much data they upload.
Once this control baseline is established, any anomaly—such as a login from a different country or at an unusual hour—is flagged. This application of the scientific control allows companies to detect “Zero-Day” exploits and insider threats that traditional antivirus software might miss because it isn’t looking for a deviation from a baseline, but rather a known signature of a virus.
The Future of Controlled Environments in Quantum Computing and Edge Tech
As we push the boundaries of technology into quantum computing and edge networks, the necessity for hyper-precise controls becomes even more critical. In these fields, the “science project” and the “tech product” are virtually indistinguishable.
Stabilizing Variables in Quantum Bits (Qubits)
Quantum computing is perhaps the most sensitive “experiment” in the tech world today. Qubits, the basic units of quantum information, are incredibly volatile and prone to “decoherence” caused by heat, electromagnetic interference, or even cosmic rays.
To make a quantum computer functional, engineers must create a “Controlled Environment” that is colder than outer space. In this niche, the control is the environmental stability. Without maintaining absolute control over the temperature and vibration variables, the “experiment” (the calculation) fails instantly. The progress of the entire tech sector in quantum supremacy relies on our ability to refine these physical and digital controls.
Standardization across IoT Ecosystems
The Internet of Things (IoT) represents a chaotic variable in the digital world. With billions of devices—from smart fridges to industrial sensors—operating on different protocols, the “control” is found in standardization.
Tech consortia are currently working to establish “Control Protocols” like Matter, which allow different devices to communicate through a shared language. In this scenario, the standard serves as the control. It ensures that regardless of the “variable” (the manufacturer of the device), the outcome (connectivity and security) remains constant and predictable.

Conclusion: Why the “Control” is the Most Important Variable in Tech
While the word “variable” often gets the most attention in tech—representing the new, the disruptive, and the innovative—it is the “control” that makes technology useful. A science project without a control is just a demonstration; a technology product without a control is a liability.
By applying the scientific rigor of control groups to A/B testing, machine learning, and cybersecurity, the tech industry ensures that progress is not just fast, but directional. It allows us to distinguish between a genuine breakthrough and a random fluctuation. As we move into an era defined by AI and quantum leaps, the ability to define, maintain, and measure against a baseline control will be the defining factor of the world’s most successful technology brands. In tech, as in science, you cannot know how far you have traveled unless you know exactly where you started.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.