In the rapidly evolving landscape of the 21st century, the word “science” is often associated with laboratory beakers and celestial telescopes. However, the core engine of the modern digital revolution is not just raw computing power, but the rigorous application of the scientific method. From the development of sophisticated artificial intelligence models to the optimization of global cloud infrastructures, technology thrives on a specific, ordered sequence of inquiry.
The scientific method in technology is a structured process used to solve complex problems, validate new features, and push the boundaries of what is possible in software and hardware engineering. By following these steps in order, tech innovators transform vague ideas into reliable, scalable, and secure digital solutions.
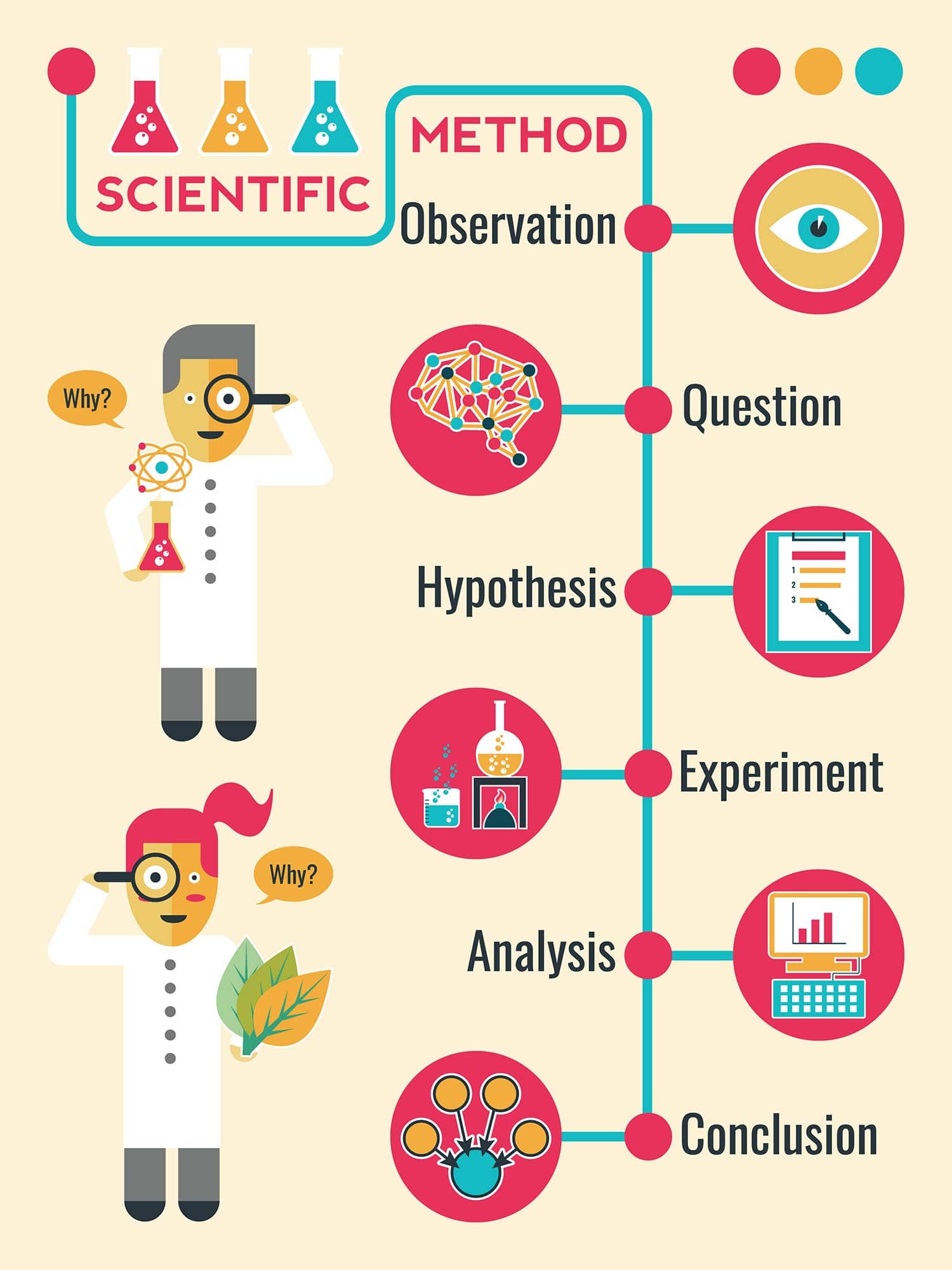
The Foundation of Discovery: Observation and Defining the Technical Problem
The first step in any scientific endeavor is observation. In the tech world, this translates to the meticulous gathering of data regarding user behavior, system performance, or market gaps. Technology does not exist in a vacuum; it is a response to a perceived need or a failure in current systems.
Leveraging Big Data and Telemetry
Modern technology provides an unprecedented “telescope” through which we can observe the digital universe: telemetry. Whether it is a software engineer monitoring server latency or a product manager analyzing user drop-off rates in a mobile app, observation is fueled by data. By using tools like Google Analytics, Datadog, or AWS CloudWatch, tech professionals identify patterns that suggest a problem exists. For example, a sudden spike in memory usage during a specific user action is an observation that demands scientific investigation.
Identifying Gaps in Current Software Architectures
Observation also involves a macro-level view of the industry. Tech leaders observe the limitations of current paradigms—such as the transition from monolithic architectures to microservices. When developers noticed that large, single-unit applications were becoming too cumbersome to update, they observed a “pain point.” This stage is critical because a poorly defined problem leads to a useless solution. In this phase, the goal is to ask: “What is the specific bottleneck, and why does it exist?”
Formulating High-Impact Hypotheses: From Logic to Algorithmic Theory
Once a problem is identified through observation, the next step in the order of the scientific method is the formation of a hypothesis. In technology, a hypothesis is a proposed explanation or a “testable guess” about how a specific change will impact a system.
The Role of Predictive Modeling
In the realm of Artificial Intelligence and Machine Learning, hypothesis formation is often mathematical. A data scientist might hypothesize that a specific neural network architecture (like a Transformer model) will process natural language more efficiently than a Recurrent Neural Network (RNN). This isn’t a random guess; it is an educated prediction based on previous technical literature and computational logic. The hypothesis must be specific: “By implementing an attention mechanism, we will reduce error rates in translation by 15%.”
Designing the “Minimum Viable Hypothesis” (MVH)
In software development and startup culture, this is often referred to as the Minimum Viable Product (MVP) stage, but it begins with a Minimum Viable Hypothesis. Developers propose that “If we add a biometric login feature, user retention will increase because of the reduced friction.” This hypothesis provides a clear roadmap for the next stage: experimentation. Without a clear hypothesis, tech development becomes a series of “shots in the dark,” wasting expensive engineering hours and computational resources.
Controlled Experimentation: The Mechanics of Software Testing and Prototyping

Experimentation is where the hypothesis meets reality. In technology, this is the most resource-intensive phase, involving the creation of prototypes, the writing of code, and the deployment of test environments. The order of the scientific method requires that experiments be controlled and repeatable.
A/B Testing and User Experience (UX) Research
One of the most common forms of experimentation in the tech industry is A/B testing (or split testing). When a company like Netflix or Amazon wants to change their interface, they don’t roll it out to everyone at once. They create a controlled experiment where Group A sees the original version and Group B sees the new version. By measuring specific variables—such as click-through rates or time spent on the page—they can scientifically prove whether their hypothesis was correct.
Sandbox Environments and Virtual Simulations
For hardware engineering and cybersecurity, experimentation often happens in a “sandbox”—an isolated environment where code can be executed without risking the entire system. When security researchers test a new encryption algorithm or a patch for a zero-day vulnerability, they simulate attacks in these controlled environments. This allows for the collection of empirical data on how the technology performs under stress, providing the “proof” required to move to the next phase.
Data Analysis and Technical Validation: Turning Metrics into Insights
After the experiment is conducted, the resulting data must be analyzed. This step is the “make or break” moment in the scientific method. In tech, analysis is not just about looking at a graph; it is about statistical significance and root-cause analysis.
Statistical Significance in Performance Metrics
If a new software update makes an app load 0.1 seconds faster, is that a success or just statistical noise? Tech professionals use data analysis to determine if the results of their experiment are meaningful. Using tools like Python’s Pandas library or R, engineers analyze “Big Data” sets to see if the changes are consistent across different devices, operating systems, and network conditions. This prevents “false positives,” where a company might deploy a feature that only works well under ideal conditions.
Debugging as a Form of Scientific Inquiry
Debugging is perhaps the most frequent application of the scientific method in a programmer’s daily life. When a bug occurs, the developer observes the crash (Observation), guesses the faulty line of code (Hypothesis), changes the code (Experiment), and checks the logs to see if the crash still occurs (Analysis). If the bug persists, the cycle repeats. This iterative analysis ensures that the final technical solution is robust and reliable.
Iteration and Peer Review: The Continuous Integration of Knowledge
The final step in the scientific method is reporting results and, most importantly, iteration. In technology, a solution is rarely “finished.” Instead, it is part of a continuous cycle of improvement, often facilitated by the global tech community.
Open Source Collaboration as Global Peer Review
In traditional science, peer review happens in academic journals. In tech, peer review happens on platforms like GitHub and GitLab. When an engineer submits a “Pull Request,” other experts review the code, looking for flaws, security risks, or inefficiencies. This collaborative environment ensures that the technology meets high standards before it is integrated into the “Master” branch. This is the scientific method scaled to a global level, where the collective intelligence of thousands of developers validates a single technical advancement.
Scaling Solutions through Systematic Refinement
The scientific method doesn’t end with a successful experiment. In the tech industry, success leads to “Scaling.” If a hypothesis about a new database structure is proven correct on a small scale, the next scientific challenge is to see if it holds up when serving millions of users. This leads back to the first step—Observation—as engineers watch how the system handles the increased load, starting the scientific cycle all over again.

Conclusion
The scientific method—Observation, Hypothesis, Experimentation, Analysis, and Iteration—is the invisible framework that supports the entire technology sector. It is the difference between a glitchy, unreliable app and a platform that changes the world. By adhering to this order, technology becomes more than just “coding”; it becomes a rigorous discipline capable of solving the world’s most complex problems. Whether you are a software developer, a data scientist, or a tech enthusiast, understanding this systematic approach is essential for navigating and contributing to the future of innovation.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.