The digital revolution has transformed the global landscape, yet for decades, a significant barrier stood between the advancements of the West and the diverse linguistic heritage of the Horn of Africa. Ethiopia, a nation with over 110 million people and a rich history as one of the few African nations with its own indigenous writing system, presents a unique challenge and opportunity for the tech world. As we move further into the era of Artificial Intelligence (AI) and Natural Language Processing (NLP), the question of “what the Ethiopian language” means in a digital context has shifted from a matter of basic font support to a complex frontier of software engineering and machine learning.
The Ethiopian linguistic landscape is dominated by Amharic, Oromo, Tigrinya, and Somali, among dozens of others. However, it is the Ge’ez script—used primarily for Amharic and Tigrinya—that represents the most significant technical hurdle and triumph in African computing. This article explores the technological journey of Ethiopian languages, the rise of localized software, and the cutting-edge AI developments that are finally bringing these ancient scripts into the hyper-connected future.
The Linguistic Landscape and the Technical Challenges of Digitization
To understand the current state of Ethiopian tech, one must first understand the complexity of the Ge’ez script. Unlike the Latin alphabet, which uses a relatively small set of characters, Ge’ez is an abugida, where each symbol represents a consonant-vowel combination. With over 300 distinct characters (or fidels) in common usage, the transition from mechanical typewriters to digital screens was not a simple feat of mapping keys.
The Ge’ez Script vs. Unicode Standardization
In the early days of computing, Ethiopian languages were largely invisible to the digital world. Standard ASCII encoding, which was designed for English, had no room for the expansive Ge’ez character set. It wasn’t until the mid-1990s and the subsequent adoption of Unicode that a global standard for encoding Ge’ez was established. This was a pivotal moment in tech history for the region. Without Unicode, Ethiopian users were forced to use “hacked” fonts that replaced Latin characters with Amharic ones, making document sharing and web searching nearly impossible. The stabilization of Unicode for Ethiopic scripts allowed for interoperability, enabling the first generation of Ethiopian websites and digital archives to exist.
Overcoming the Keyboard and Input Method Obstacles
The sheer number of characters in the Ge’ez script made standard QWERTY keyboards physically inadequate. Software engineers had to develop sophisticated Input Method Editors (IMEs) to solve this. The “phonetic mapping” approach became the standard: a user types “b” and then “a” to produce the single character “ባ” (ba). Developing these algorithms required a deep understanding of both linguistics and user experience (UX) design. Today, the evolution of mobile keyboards with predictive text and “fidel” suggestions has dramatically lowered the barrier to entry for digital communication in Ethiopia, allowing millions to transition from oral tradition to digital literacy.
AI and Natural Language Processing (NLP) for Amharic and Beyond
In the current tech climate, the focus has shifted from basic character display to “understanding” the language. For years, Ethiopian languages were classified by big tech companies as “low-resource languages.” This means there was a lack of large-scale, high-quality digital text data available to train the machine learning models that power tools like Google Translate, Alexa, or ChatGPT.
The Rise of Large Language Models (LLMs) in the Horn of Africa
The emergence of Large Language Models has sparked a new wave of innovation focused on the Ethiopian market. While models like GPT-4 are primarily trained on Western data, specialized researchers and local startups are working on “fine-tuning” these models for Amharic and Oromo. The technical challenge here lies in “tokenization”—the way an AI breaks down sentences. Because Ethiopian languages are morphologically rich (a single word can contain the meaning of an entire English sentence), standard Western tokenizers often fail. Tech teams are now developing custom tokenizers that respect the grammatical structure of Semitic and Cushitic languages, leading to more accurate translations and more coherent AI-generated content.
Overcoming the Data Scarcity Barrier through Crowdsourcing
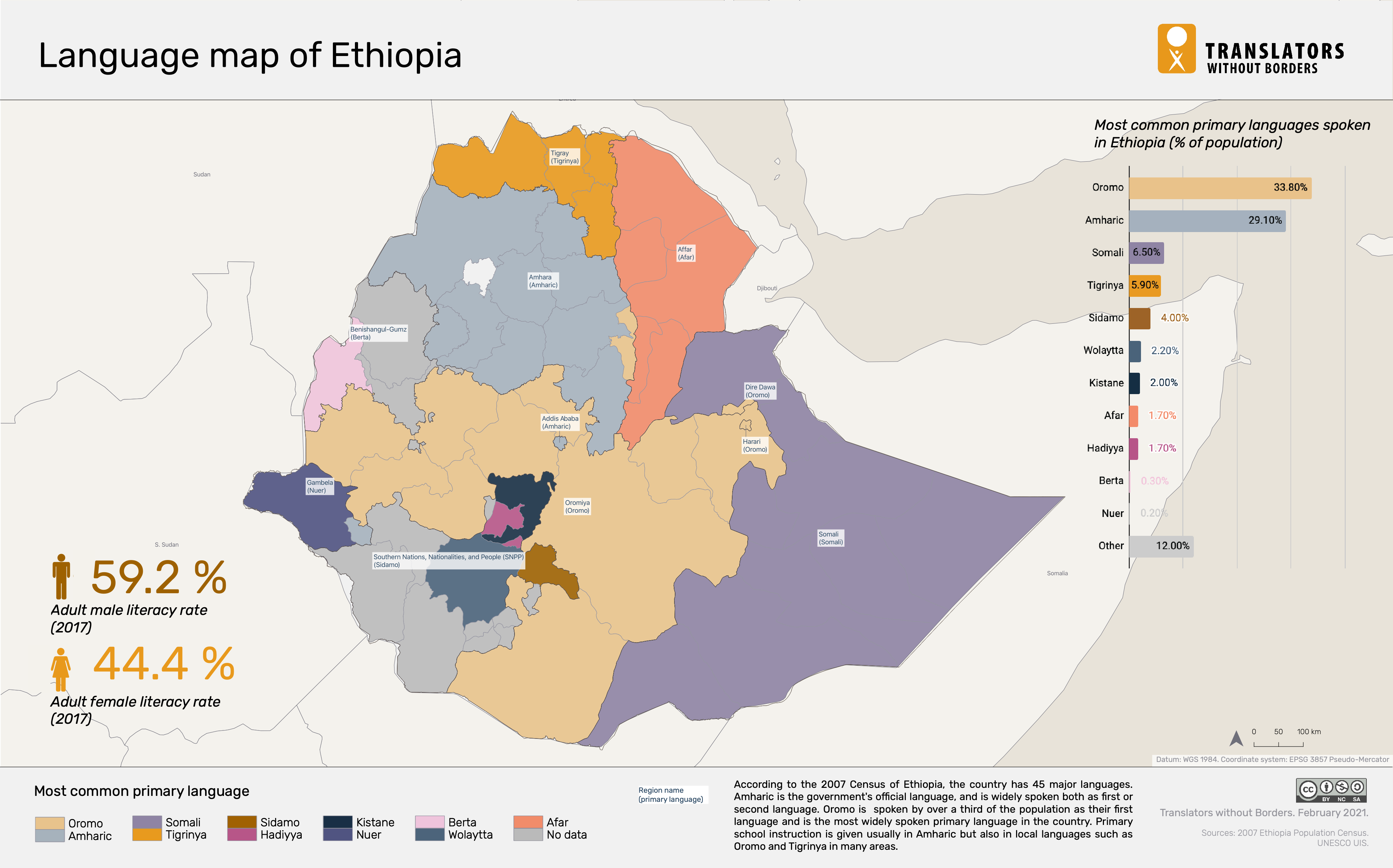
To solve the low-resource problem, the tech community has turned to innovative data collection methods. Projects like “Lesan AI” and various grassroots academic initiatives have utilized crowdsourcing to build massive datasets of translated and transcribed text. By gamifying the data entry process or using “transfer learning” (where a model learns from a high-resource language like Arabic and applies that logic to Amharic), engineers are closing the gap. This has direct implications for the digital economy; an AI that understands Amharic can power customer service bots for Ethiopian banks, provide automated agricultural advice to farmers, and improve accessibility for the visually impaired through text-to-speech technology.
The Rise of Localization: Apps and Software Tailored for Ethiopia
Technology is only effective if it is accessible, and in Ethiopia, accessibility is synonymous with localization. Localization goes beyond mere translation; it involves adapting the entire user interface (UI) and user experience (UX) to fit the cultural and linguistic nuances of the Ethiopian user base.
Mobile-First Solutions and Localized UX
Ethiopia’s digital leapfrog is happening primarily through mobile devices. Consequently, software developers are focusing on “lite” versions of apps that work on low-bandwidth connections and feature interfaces entirely in local languages. From the ride-hailing app “Ride” to the massive fintech platform “Telebirr,” the success of these tools is built on their ability to communicate with users in their native tongue. Tech firms have discovered that even bilingual users prefer conducting financial transactions or using government services in their primary language, as it builds trust and reduces the cognitive load of navigating complex menus.
Fintech and the Digitalization of Traditional Systems
The integration of Ethiopian languages into fintech has been a game-changer for financial inclusion. Before the digital push, banking was a brick-and-mortar affair often conducted in English or high-level Amharic. Today, mobile banking apps are localized into multiple regional languages, including Oromo and Somali, allowing rural populations to engage with the digital economy. The software architecture behind these apps must support multi-language toggles and Ge’ez font rendering on low-end smartphones, representing a significant technical feat in mobile optimization and database management.
Future Horizons: Voice Recognition and the Ethiopic Web
As we look toward the next decade, the frontier of Ethiopian language tech is moving into the realm of voice and ambient computing. Given that literacy rates vary across the region, voice-activated technology represents the ultimate tool for digital democratization.
Speech-to-Text and the Accessibility Revolution
Developing Speech-to-Text (STT) for Ethiopian languages is the current “holy grail” for local developers. The phonology of Amharic, with its unique “ejective” sounds, requires specialized acoustic models that differ from those used for English or French. Tech labs in Addis Ababa are currently working on deep learning architectures that can recognize regional accents and dialects. Once perfected, this technology will allow a farmer in a remote area to ask their phone for the current market price of teff in their native Oromo dialect and receive an instant, synthesized voice response.

Preserving Cultural Heritage through High Tech
Beyond commerce and utility, technology is playing a vital role in cultural preservation. The digitization of ancient Ge’ez manuscripts using Optical Character Recognition (OCR) is a major focus for tech-savvy historians. By training AI to recognize handwritten characters from centuries-old parchments, developers are creating searchable digital libraries that preserve Ethiopia’s history for the world. This intersection of “Deep Tech” and “Deep History” demonstrates that the digital evolution of Ethiopian languages is not just about modernization—it is about ensuring that one of the world’s oldest cultures has a permanent, prominent seat at the digital table.
In conclusion, the journey of bringing Ethiopian languages into the digital age is a testament to the power of localized innovation. From the early struggles of Ge’ez Unicode to the current breakthroughs in Amharic AI, the tech industry is proving that no language is too complex for the binary world. As these tools continue to evolve, they will not only empower the Ethiopian people but also provide a blueprint for how other “low-resource” languages across the globe can find their voice in the age of Artificial Intelligence.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.