In the rapidly evolving landscape of global technology, the simplest words often present the most complex engineering challenges. For a software developer or a localization engineer, the word “tu” in Spanish is far more than a second-person singular pronoun. It represents a pivot point in user experience (UX), a hurdle for Natural Language Processing (NLP), and a critical variable in the architecture of modern AI-driven translation tools.
As technology companies expand into Latin American and Spanish markets, understanding “tu”—and its formal counterpart “usted”—is no longer just a linguistic necessity; it is a technical requirement for creating seamless, culturally resonant digital products. This article explores how modern tech stacks handle the nuances of Spanish address, the role of machine learning in decoding social context, and the future of localized software design.

The Engineering Behind the Informal: Why “Tu” Challenges AI
At first glance, translating “you” into Spanish seems straightforward. However, the binary choice between the informal tú and the formal usted creates a cascading effect across an entire software interface. This is what localization experts call the “T-V distinction” (from the Latin tu and vos), and for an algorithm, it is a nightmare of contextual ambiguity.
Tokenization and the Contextual Gap
In traditional Natural Language Processing, tokenization involves breaking down text into smaller units. When an AI processes the English “You,” it sees a single token. However, when generating a Spanish output, the system must choose between “tú,” “usted,” “vos,” and “vosotros.”
The challenge lies in the “context window.” Older machine translation models operated on a sentence-by-sentence basis, often defaulting to a formal tone to avoid offending users. Modern Large Language Models (LLMs), however, must look at the entire session history to determine the appropriate level of intimacy. If a fitness app begins its onboarding by using the informal “tu,” the entire backend logic must maintain that consistency. A single slip into “usted” in a push notification can break the user’s immersion and signal a lack of technical sophistication.
Semantic Mapping of Social Hierarchy
Tech companies are now building “social graphs” into their translation layers. These graphs attempt to map the relationship between the speaker (the software) and the listener (the user). For a gaming app, the “tu” form is almost universally preferred to foster a sense of community and excitement. Conversely, for a B2B fintech platform, the software might be hard-coded to favor “usted” to project a sense of security and professional distance. The technical implementation involves “attribute-based translation,” where a user’s profile settings or the app’s “persona” metadata dictates the pronoun selection across all API calls.
Localization Architecture: Automating the T-V Distinction
For global enterprises, manual translation of every string is impossible. The solution lies in sophisticated Localization Architecture that integrates Computer-Assisted Translation (CAT) tools with automated workflows.
Translation Memory (TM) and Variable Injection
The backbone of modern localization tech is the Translation Memory. This database stores segments of previously translated text. To handle the “tu” vs. “usted” problem, engineers use “variable injection” and “conditional strings.”
Instead of hard-coding “How are you?” as a static string, developers use placeholders like {greeting_subject_informal} or {greeting_subject_formal}. The localization management system (LMS) then pulls the correct variant based on the target locale’s cultural settings. This allows a single codebase to serve a teenager in Madrid (who expects “tú”) and a business executive in Mexico City (who might prefer “usted”) without redundant development work.
Quality Assurance (QA) through Automated LQA
Localization Quality Assurance (LQA) has traditionally been a human-centric process. However, new AI-driven LQA tools are now capable of scanning thousands of lines of code to identify “tone drift.” These tools use heuristic analysis to ensure that if a “tu” is used in the “Settings” menu, the “Terms of Service” don’t jarringly switch to a different register. By utilizing regex (regular expression) patterns and semantic analysis, these tools flag inconsistencies before they ever reach the production environment.
The LLM Revolution: Training Models on Cultural Context
The shift from Neural Machine Translation (NMT) to Large Language Models (LLMs) like GPT-4 or Claude 3 has fundamentally changed how the “tu” in Spanish is handled. We are moving away from rule-based systems toward models that understand “vibe” and cultural nuance.
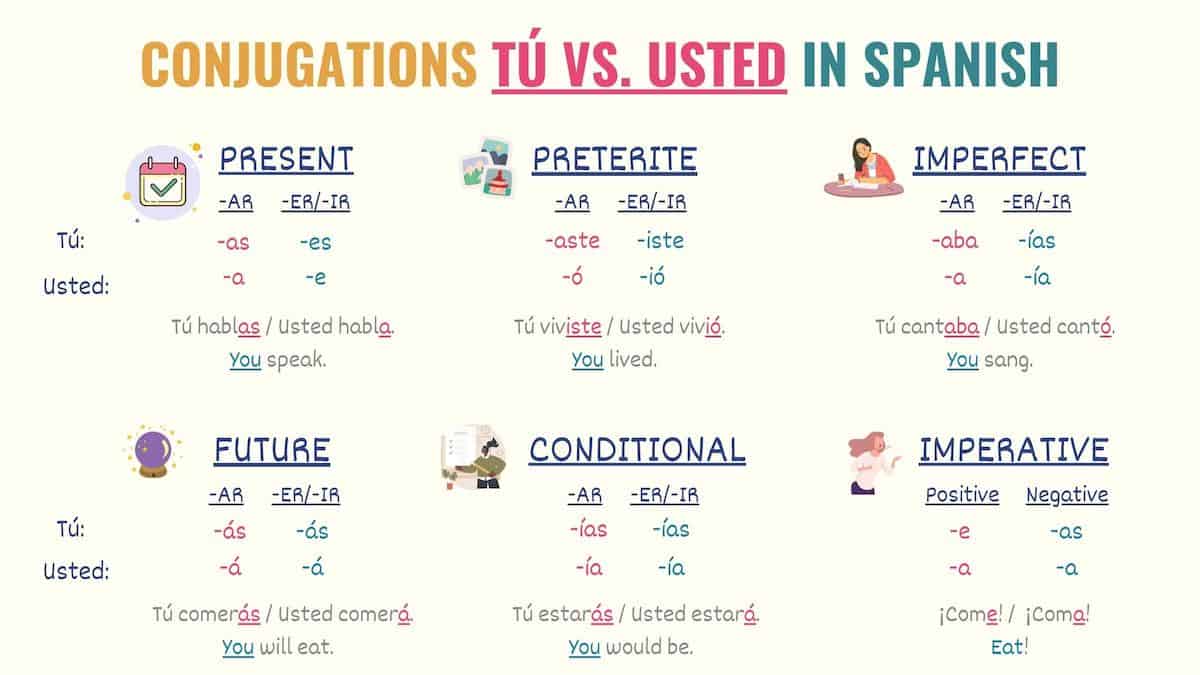
Fine-Tuning for Regional Dialects
The word “tu” is not the only way to be informal in Spanish. In regions like Argentina, Uruguay, and parts of Colombia, the “voseo” (using vos instead of tú) is the standard. For a tech company like Spotify or Netflix, getting this wrong is a major UX failure.
Engineers are now “fine-tuning” base LLMs with region-specific datasets. By feeding the model millions of lines of localized dialogue, the AI learns that a “tu” in Spain might require different verb conjugations than a “tu” in Chile. This level of granular personalization is achieved through “LoRA” (Low-Rank Adaptation), a technique that allows developers to add a small, specialized layer of knowledge onto a massive model without the cost of retraining the entire system.
The Role of Prompt Engineering in Persona Development
When developers build chatbots or AI assistants, they use “system prompts” to define the bot’s personality. A system prompt might look like this: “You are a friendly, upbeat assistant for a Spanish-speaking audience. Use the ‘tu’ form and avoid overly formal language.”
The tech behind this involves “weighting” certain tokens. The model is mathematically discouraged from selecting formal verb endings. This ensures that the “tu” isn’t just a word Choice, but a consistent linguistic behavior. This is the difference between a bot that sounds like a robot and a bot that sounds like a local.
Practical Applications in UX/UI Design for Global Software
The choice of using “tu” in Spanish has immediate implications for User Interface (UI) and User Experience (UX) design. It is not just about the words; it is about the “real estate” on the screen.
String Expansion and Layout Reflow
In Spanish, informal “tu” conjugations are often shorter or longer than their formal counterparts. For example, “Tell us” becomes “Cuéntanos” (informal) or “Cuéntenos” (formal). While the character difference is small, in a mobile app where every pixel counts, “string expansion” can break a button’s layout.
Modern UI frameworks like React Native or Flutter now integrate with localization APIs that allow for “dynamic reflow.” If the localized string for “tu” exceeds the button width, the UI automatically adjusts the font size or padding. This ensures that the technical integrity of the app is maintained regardless of the linguistic register chosen.
User Choice and Personalization Toggles
A growing trend in “Empathetic Tech” is allowing the user to choose their preferred level of formality. Some advanced SaaS platforms now include a “Tone” toggle in the user settings.
From a backend perspective, this requires a robust state-management system. When a user selects “Informal (Tú),” a global variable is updated across the application’s state. Every subsequent API request that involves text generation passes this variable to the localization engine. This represents the pinnacle of user-centric tech: giving the user agency over how the software speaks to them.
The Future: Real-Time Speech Translation and the “Tu” Factor
As we move toward a world of real-time voice translation—think “smart glasses” or instant earpiece translators—the “tu” problem becomes even more acute. In a live conversation, there is no time for a human editor to correct a formal error.
Latency vs. Accuracy in Neural Transduction
The technical challenge here is latency. To determine if someone should be addressed as “tu,” an AI needs to hear the beginning of the sentence and perhaps analyze the speaker’s tone, age, and social setting. This requires “Zero-shot” translation capabilities where the AI makes a split-second decision.
We are seeing the emergence of “Multi-modal AI” that uses both audio and visual data. If the AI’s camera sees two teenagers talking, it will prioritize the “tu” form in the translation. If it sees a boardroom meeting, it defaults to “usted.” This integration of computer vision and NLP is the next frontier in resolving the “tu” vs. “usted” debate.

Conclusion: More Than Just a Word
In the world of technology, “tu” is a symbol of the broader challenge of human-computer interaction. It reminds us that software does not exist in a vacuum; it exists within a cultural framework. By mastering the “tu” in Spanish through advanced NLP, localization architecture, and LLM fine-tuning, tech companies can move beyond mere functionality. They can build products that truly “speak the language” of their users, fostering trust and engagement in one of the world’s most vibrant digital markets. As AI continues to evolve, our machines are becoming less like calculators and more like cultural conduits, where even a two-letter word like “tu” is treated with the technical respect it deserves.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.