In the realm of Natural Language Processing (NLP) and Computational Linguistics, the distinction between the imperfect and the preterite tenses is far more than a mere grammatical hurdle for students. It represents one of the most complex challenges in data labeling, semantic analysis, and machine learning. As developers and AI engineers strive to create more human-like communication interfaces, understanding the “aspectual” difference between these two ways of viewing the past is critical.
While a human speaker intuitively understands when an action is a finished event versus an ongoing state, a machine must rely on context windows, tokenization, and deep learning architectures to decipher the intent. This article explores the technical differences between the imperfect and preterite tenses through the lens of modern software engineering, AI training, and the evolution of EdTech.
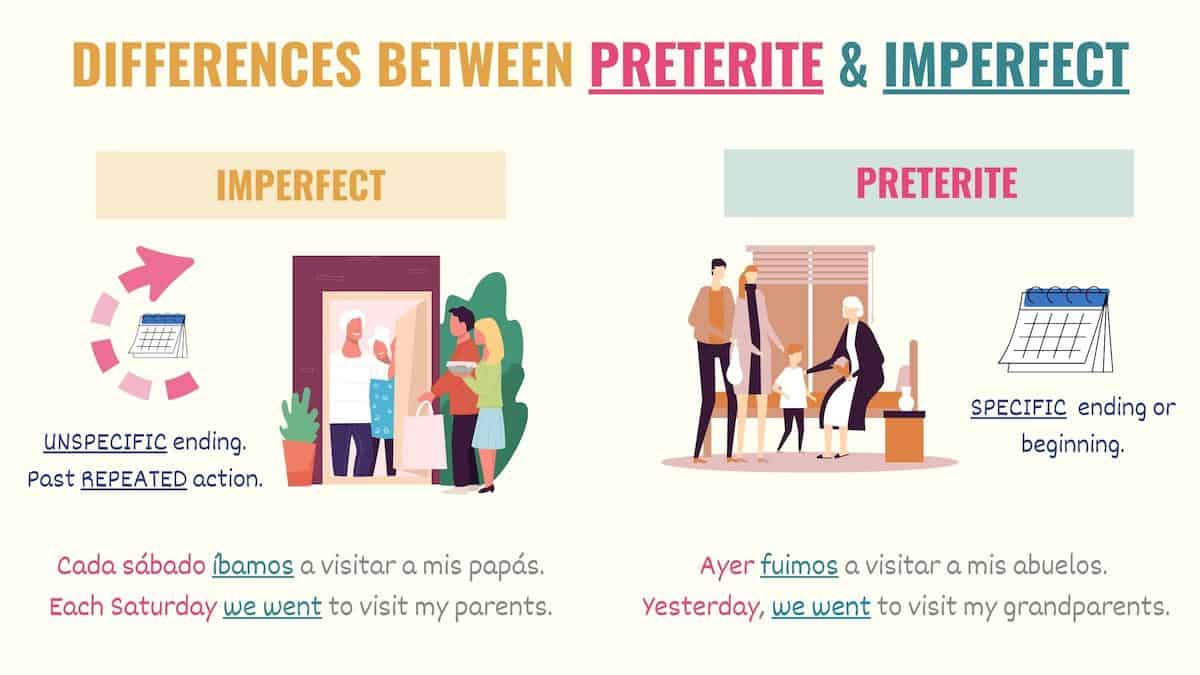
The Linguistic Architecture: Why Tense Logic Matters in Digital Communication
To a software program, language is essentially a series of tokens that must be mapped to a logical timeline. The difference between the imperfect and the preterite is often defined in linguistics as “aspect.” While “tense” tells us when something happened, “aspect” tells us how that action relates to the flow of time. For developers building translation engines or chatbots, this is a fundamental data point.
Defining the Preterite in Data Structures
In the world of data, the preterite is analogous to a discrete event or a “commit” in a version control system like Git. It represents a completed action with a clear beginning and a definitive end. When an AI processes the preterite, it interprets the event as a single point on a timeline.
In programming terms, if we were to model the preterite, it would look like a function that has successfully returned a value and terminated. For example, “I bought a computer” is a singular event. In technical documentation and automated summary tools, identifying preterite actions is essential for creating chronological logs and milestone reports.
Mapping the Imperfect: The Fluidity of Continuous States
The imperfect tense, by contrast, functions more like a background process or a “while” loop in coding. It describes ongoing actions, habitual behaviors, or states of being in the past where the end point is not defined. “I was writing code” suggests a state that was interrupted or provided context for another event.
From a technical perspective, the imperfect is much harder for AI to map because it lacks “boundaries.” It creates a temporal “atmosphere” rather than a specific data point. In sentiment analysis and digital security—specifically in forensic linguistics—identifying the imperfect allows software to distinguish between a specific action (a security breach) and a general state (a system vulnerability that existed over time).
Machine Learning and the Paradox of Aspectual Distinction
The transition from Rule-Based Machine Translation (RBMT) to Neural Machine Translation (NMT) has fundamentally changed how software handles the nuance of the past tense. Early software struggled with the “imperfect vs. preterite” divide because it looked for direct word-for-word correlations. Modern AI, however, uses complex neural networks to understand the broader context.
Training Models on Temporal Context
Machine learning models, such as GPT-4 or Claude, are trained on massive datasets where they learn to predict the most likely tense based on surrounding markers. Keywords act as “anchors” for the algorithm. For instance, words like “yesterday” or “suddenly” often trigger the preterite, while “always” or “used to” signal the imperfect.
The challenge for engineers is “disambiguation.” Many languages, particularly Romance languages like Spanish or French, use different verb endings for these tenses, but English often uses the same word or relies on auxiliary verbs. To teach a machine the difference, developers use “Supervised Learning,” where linguists label thousands of sentences to show the machine whether an action is “perfective” (completed) or “imperfective” (ongoing).
The Role of Transformer Models in Disambiguation
The introduction of Transformer models has been a game-changer for identifying tense nuances. Transformers use a mechanism called “self-attention,” which allows the model to weigh the importance of different words in a sentence regardless of their distance from each other.
If a sentence begins with a description of the weather (Imperfect: “The sun was shining…”) and ends with a sudden event (Preterite: “…when the server crashed”), the attention mechanism allows the AI to maintain the state of the first half while identifying the event of the second. This ability to maintain “state” across long strings of text is what allows modern AI to translate complex literature or technical manuals without losing the temporal flow.

EdTech Applications: How Apps Teach the Tense Divide
The multibillion-dollar Education Technology (EdTech) industry has turned the “imperfect vs. preterite” debate into a core component of user experience (UX) design. Apps like Duolingo, Babbel, and Rosetta Stone use specific algorithms to help learners master this distinction through adaptive learning paths.
Gamification of Grammar Logic
In modern language apps, the pedagogical challenge is to translate abstract grammar rules into interactive UI elements. Developers use “Spaced Repetition Systems” (SRS) to drill the difference between the two tenses.
For example, a user might be presented with a drag-and-drop interface where they must categorize verbs into “Snapshot” (Preterite) or “Background” (Imperfect). By gamifying the logic, the software helps the brain build the same pattern-recognition systems that a machine learning model uses. The tech behind this involves tracking “error rates” for specific grammatical categories, allowing the app to dynamically increase the difficulty of preterite-imperfect exercises if the user shows a weakness in that specific logic gate.
Real-time Feedback Loops in Language Software
Advanced EdTech platforms are now integrating Real-time Feedback Loops powered by AI. When a student writes an essay in a second language, the software doesn’t just check for spelling; it analyzes the temporal logic.
If a student uses the preterite to describe a habitual action, the software identifies the “logical mismatch.” This requires a deep-learning backend capable of semantic understanding. The “Grammarly” of the future won’t just suggest a better word; it will suggest a better aspect, explaining that the imperfect tense better reflects the “ongoing nature” of the user’s intent.
Future Horizons: Neural Machine Translation and the Nuance of Time
As we look toward the future of global communication, the precision of tense translation is becoming a cornerstone of specialized AI tools, particularly in legal and medical tech.
Overcoming Literal Translation Errors
Literal translation is the enemy of the preterite-imperfect distinction. In legal tech (LawTech), a “literal” translation of a witness statement could change the entire meaning of an event. For example, the difference between “He was signing the contract” (Imperfect – perhaps interrupted or not finalized) and “He signed the contract” (Preterite – a legal fact) is massive.
Future AI models are being developed with “Domain-Specific Training.” This involves feeding models legal archives where the distinction between an ongoing state and a completed action is clearly defined. By minimizing literal translation and maximizing “context-aware” translation, software can reduce the risk of multi-million dollar errors in international business contracts.
Context-Aware AI for Global Documentation
In the world of global software documentation and technical writing, consistency is king. Modern Content Management Systems (CMS) are beginning to integrate AI that ensures the “voice” of the documentation remains consistent in its use of tense.
If a manual is explaining a historical system update, the AI can audit the text to ensure the preterite is used for specific version releases, while the imperfect is used for describing the legacy system’s general behavior. This “Temporal Auditing” is a new frontier in AI-driven text editing, ensuring that as products evolve, the story of their development is told with grammatical and logical precision.

Conclusion: The Digital Synthesis of Time
The difference between the imperfect and the preterite is a microcosm of the larger challenge in artificial intelligence: capturing the nuance of human perception. For a human, time is felt; for a machine, time is measured. Bridging that gap requires sophisticated algorithms, massive datasets, and an elegant understanding of linguistic aspect.
As we continue to develop more advanced NLP tools, the “imperfect vs. preterite” distinction serves as a benchmark for AI maturity. When a machine can perfectly distinguish between the background noise of the past and the definitive strikes of history, it moves one step closer to truly understanding the human experience. Whether through the lens of a language learning app or a high-level translation engine, the mastery of these tenses is a testament to the incredible progress of modern technology.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.