In the rapidly evolving landscape of technology, we are often blinded by the brilliance of “hard numbers.” We obsess over objective data: server uptime, millisecond latency, conversion rates, and hardware benchmarks. These metrics provide a clear, indisputable snapshot of performance. However, as we move deeper into the era of Artificial Intelligence and human-centric design, a different kind of data has emerged as the true differentiator for successful tech products: subjective data.
In fields like nursing, subjective data refers to the information provided by the patient that cannot be measured by a tool—feelings, perceptions, and personal narratives. In the tech industry, the definition is strikingly similar. Subjective data represents the qualitative feedback, emotional responses, and perceived experiences of the user. It is the “why” behind the “what” of objective telemetry. Understanding and leveraging this data is no longer a luxury for UX researchers; it is a fundamental requirement for building the next generation of software, AI, and digital infrastructure.
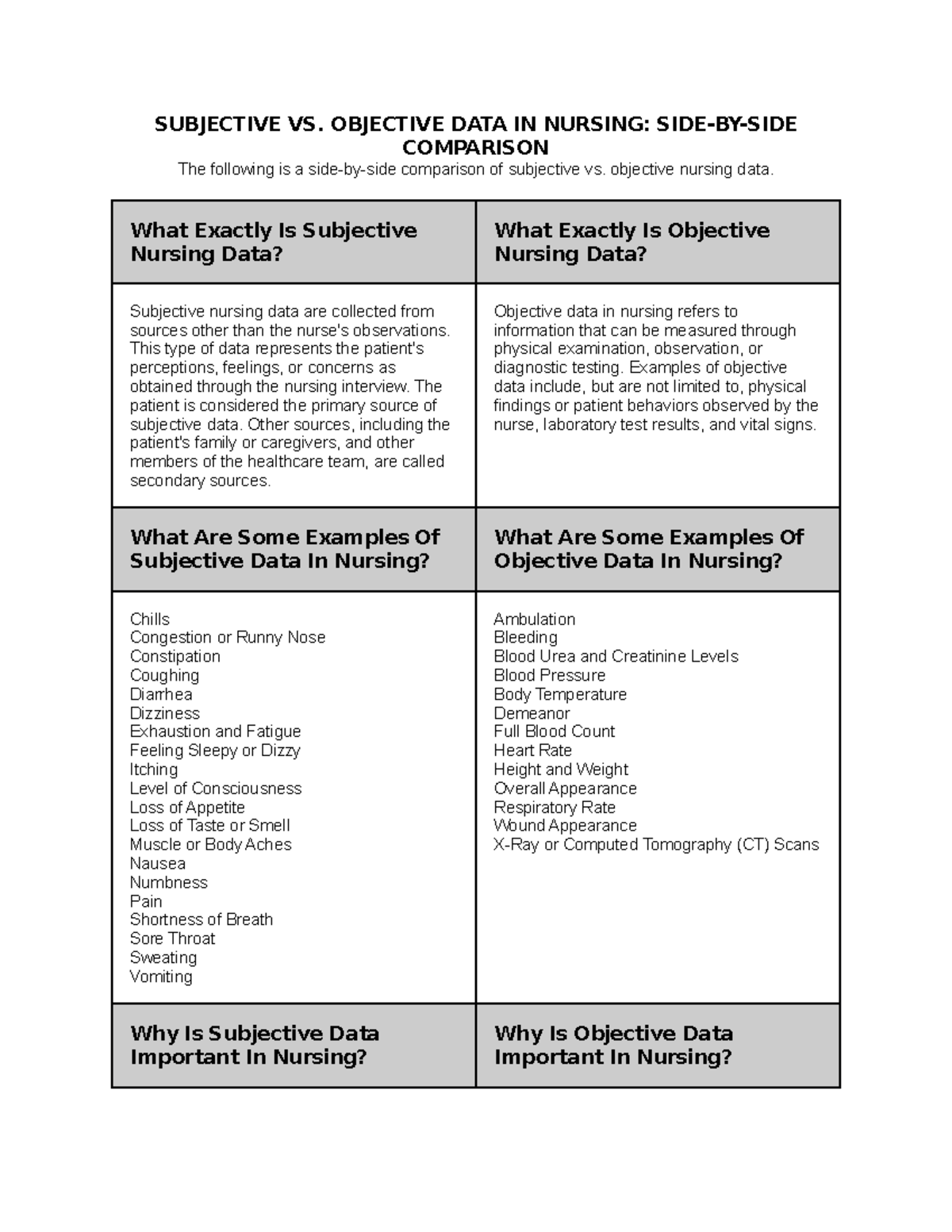
Understanding Subjective Data in the Digital Landscape
To build a comprehensive tech strategy, one must first distinguish between the data we measure and the data we feel. Objective data is the “vital signs” of a software system—CPU usage, bounce rates, and load times. Subjective data, conversely, is the “symptoms” reported by the user—frustration with a navigation menu, the sense of security felt when using a fintech app, or the delight found in a seamless animation.
Defining Subjective vs. Objective Data in Tech
Objective data is binary and empirical. It exists whether a human interprets it or not. For example, if a website takes 4.2 seconds to load, that is an objective fact. Subjective data, however, is filtered through the lens of human consciousness. To one user, a 4.2-second load time is “infuriatingly slow,” while to a user on a legacy network, it might feel “unexpectedly fast.” This variance highlights why tech companies cannot rely on logs alone. Without the subjective context, developers may optimize for the wrong metrics, solving technical problems while failing to solve human ones.
The Role of Qualitative Insights in Product Development
The integration of subjective data usually occurs during the discovery and testing phases of product development. While A/B testing provides objective evidence of which version of a feature performs better, it rarely explains why. Qualitative insights—gathered through user interviews, open-ended surveys, and ethnographic studies—provide the narrative framework. This “thick data” allows product managers to understand the mental models of their users, ensuring that the software aligns with human intuition rather than just technical logic.
The Intersection of Subjective Data and Artificial Intelligence
The most significant frontier for subjective data is currently within the realm of Artificial Intelligence (AI). Large Language Models (LLMs) like GPT-4 or Claude are not just trained on objective facts; they are increasingly fine-tuned based on subjective human preferences.
Training LLMs on Human Sentiment
The process of Reinforcement Learning from Human Feedback (RLHF) is essentially the systematic collection of subjective data to train a machine. When a human trainer ranks one AI response as “more helpful” or “more polite” than another, they are providing subjective data. There is no objective mathematical formula for “politeness” or “helpfulness.” By quantifying these subjective human values, AI developers can align machine outputs with human expectations, making the technology feel more “natural” and less “robotic.”
Solving the Hallucination Problem through Human Feedback
One of the greatest challenges in AI is the “hallucination”—when a model confidently states a falsehood. While objective checks (cross-referencing databases) can flag some errors, subjective data is required to gauge the reliability and authority of a response. Users provide subjective ratings on the clarity and trustworthiness of AI outputs, which helps developers tweak the temperature and parameters of the model. This feedback loop creates a bridge between cold logic and human nuance, allowing AI to operate effectively in subjective fields like creative writing, legal analysis, and emotional support.
Optimizing User Experience (UX) through Subjective Analysis

In the world of UX design, the mantra has shifted from “Don’t Make Me Think” to “Make Me Feel.” Subjective data is the primary tool used to measure the emotional resonance of a digital product.
Sentiment Analysis and Emotional Mapping
Tech companies now employ sophisticated sentiment analysis tools to parse through millions of app store reviews, social media mentions, and support tickets. These tools use Natural Language Processing (NLP) to categorize subjective data into emotional categories: anger, joy, confusion, or satisfaction. By mapping these emotions to specific touchpoints in the user journey, companies can identify “friction points” that objective data might miss. For instance, a checkout process might have a high completion rate (objective success), but sentiment analysis reveals that users find the process “stressful” or “untrustworthy” (subjective failure).
The Limitations of Quantitative Metrics (The “Why” vs. The “What”)
Relying solely on quantitative metrics can lead to the “Vanity Metric Trap.” A high “Time on Page” metric might objectively look good, suggesting engagement. However, subjective data from user testing might reveal that people are spending a long time on the page because the UI is confusing and they cannot find the exit. Without subjective context, the tech team might continue to optimize for “engagement,” inadvertently making the product more frustrating. Subjective data acts as the “North Star” that ensures objective metrics are interpreted correctly.
Security and the Subjective Human Element
Digital security is often viewed as a fortress of firewalls and encryption—purely objective, mathematical barriers. However, the weakest link in any security chain is the human element, and managing that link requires a deep dive into subjective data.
Social Engineering and Subjective Vulnerabilities
Social engineering—the tactic used in the majority of modern cyberattacks—exploits subjective human traits like trust, urgency, and fear. To combat this, cybersecurity experts analyze subjective data regarding user behavior. How likely is an employee to click a link if the email “feels” like it’s from their CEO? By studying the subjective perceptions of “authority” and “urgency” within an organization, security teams can develop better training modules that go beyond technical “best practices” and address psychological vulnerabilities.
User Perception of Digital Trust
Trust is perhaps the most critical subjective data point in the tech industry. In an era of data breaches and privacy concerns, a brand’s survival depends on the subjective feeling of security a user has when interacting with an app. This “Digital Trust” is not just about having a SOC 2 certification (objective); it is about the transparency of the privacy policy, the clarity of the UI, and the brand’s historical reputation (subjective). Tech companies that prioritize the “feeling” of safety often see higher retention rates than those that offer better technical security but a “shady” user experience.
The Future of Subjective Data Integration
As we look toward the future of technology, the distinction between “data” and “humanity” will continue to blur. We are moving toward a world of “Hyper-Personalization,” where software adapts to the user’s subjective state in real-time.
Balancing Privacy with Personalization
The next generation of wearable tech and IoT devices will attempt to quantify subjective states like stress, fatigue, and focus. This raises a significant ethical and technical challenge: how do we collect and use this highly personal subjective data without violating privacy? The tech leaders of tomorrow will be those who can build systems that respect the “subjective self” while providing the benefits of a data-driven lifestyle.

Ethical Considerations in Data Interpretation
Finally, as tech companies rely more on subjective data, they must account for bias. Because subjective data is rooted in human experience, it carries the baggage of human prejudice. If an AI is trained on the subjective preferences of a non-diverse group of developers, the resulting product will reflect those biases. The future of tech requires a rigorous, ethical framework for the collection and interpretation of subjective data, ensuring that “human-centric” means all humans, not just a select demographic.
In conclusion, while objective data provides the skeleton of the technology industry, subjective data is the flesh, blood, and soul. By understanding the “why” behind the user’s actions—their feelings, perceptions, and narratives—tech companies can move beyond mere functionality and create products that truly resonate with the human experience. Whether it is in AI training, UX design, or cybersecurity, the most valuable data point in the room is often the one that cannot be measured by a computer, but only felt by a person.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.