In the rapidly evolving landscape of technology, information is often compared to oil—a raw resource that drives the global economy. However, raw data, like crude oil, is virtually useless without refinement and structure. At the heart of this refinement process lies a fundamental concept known as “schemata” (the plural form of schema).
In the technical realm, a schema serves as the logical blueprint or the skeletal framework that defines how data is organized, stored, and related within a system. Whether you are navigating a complex relational database, optimizing a website for search engines, or training a sophisticated machine learning model, schemata provide the essential rules of engagement. Understanding schemata is critical for software engineers, data scientists, and IT architects who aim to build scalable, efficient, and interoperable digital ecosystems.
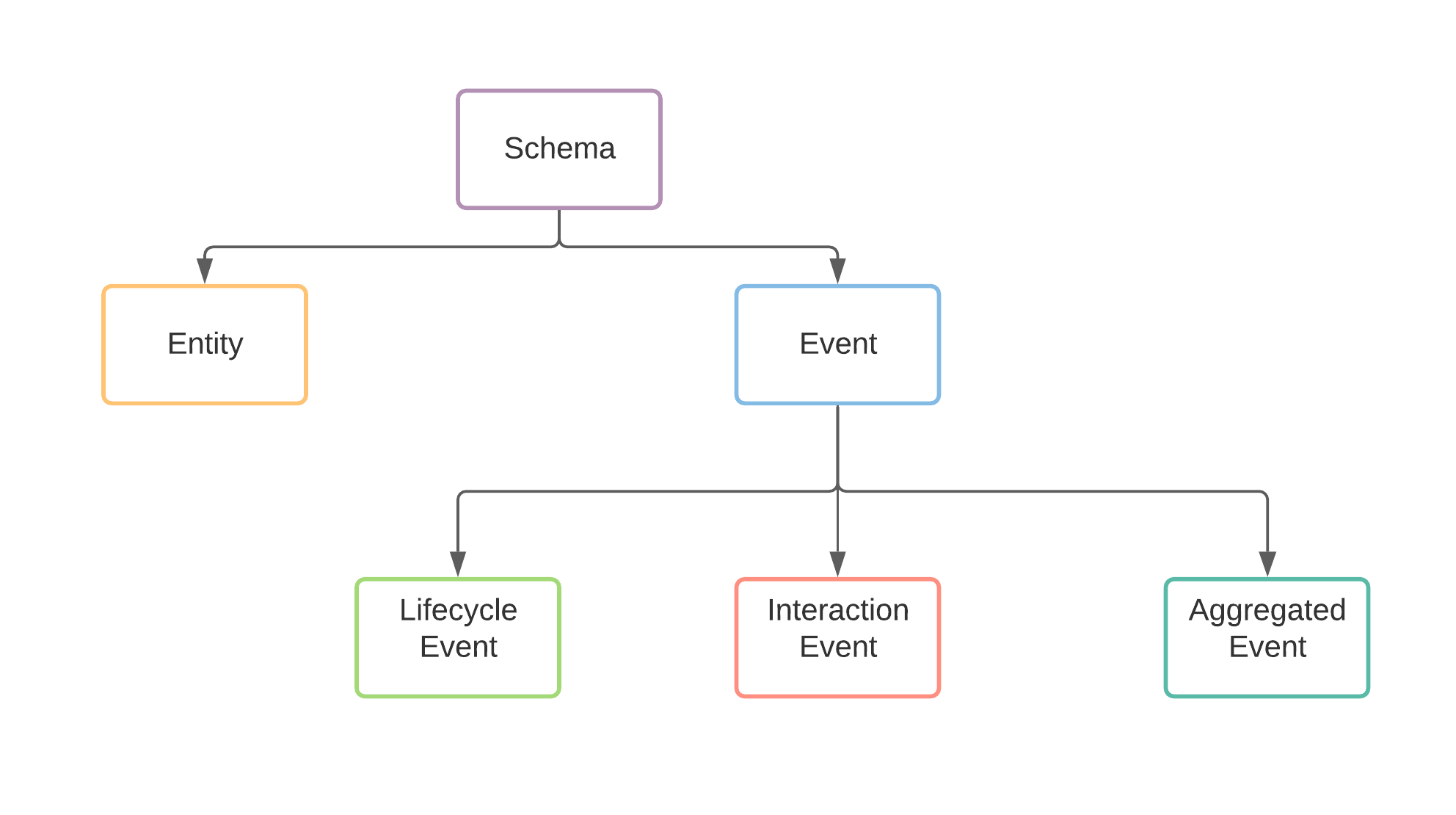
Defining the Concept: From Logic to Digital Infrastructure
To understand what a schema is in a technological context, one must first look at its purpose: to provide order to chaos. Without a schema, a computer system sees a vast sea of bits and bytes with no context. A schema provides that context by defining the “shape” of the data.
The Core Definition: What is a Schema?
In computer science and information technology, a schema is a formal description of the structure of a database or a set of data. It defines the entities (such as “Users,” “Orders,” or “Products”), the attributes of those entities (such as “Email Address” or “Price”), and the relationships between them.
Think of a schema as the architectural drawing of a building. The drawing isn’t the building itself, but it dictates exactly where the walls go, where the plumbing runs, and how the rooms connect. Similarly, a schema dictates how data points connect to one another, ensuring consistency and integrity across the entire application lifecycle.
Why Structure Matters in the Digital Age
As we move toward a world dominated by Big Data and Real-Time Analytics, the importance of schemata has only intensified. Modern organizations handle petabytes of information; without a predefined structure, retrieving a specific piece of information would be like looking for a needle in a haystack.
Schemata solve three primary problems:
- Data Integrity: By enforcing rules (such as “a phone number must contain only digits”), schemata prevent “garbage in, garbage out” scenarios.
- Scalability: A well-designed schema allows a system to grow. When you know exactly how data is stored, you can optimize queries to handle millions of requests per second.
- Interoperability: When different software systems need to talk to each other, they use shared schemata to ensure that the data sent by System A is understood by System B.
Types of Database Schemata: Organizing Information
The most common application of schemata is found in database management systems (DBMS). Depending on the needs of the application—whether it is a simple blog or a global banking system—the type of schema used will vary significantly.
Logical vs. Physical Schemas
In database design, we often distinguish between the logical and the physical layers.
- The Logical Schema describes the data in terms of its relationships and constraints. It focuses on what the data is and how it relates to other data, independent of how it is stored.
- The Physical Schema describes how the data is actually stored on the hardware (disks, SSDs, or cloud storage). It deals with memory allocation, file indices, and storage paths.
While developers spend most of their time interacting with the logical schema, the physical schema is what determines the performance and latency of a tech stack.
Relational vs. NoSQL Approaches
For decades, the Relational Schema (SQL) was the gold standard. In this model, data is organized into tables with fixed columns. Every entry in a table must follow the exact same schema. This is ideal for financial systems or inventory management where consistency is non-negotiable.
However, the rise of “unstructured” data (social media posts, sensor logs, images) led to the popularity of NoSQL or Schema-less designs. In these systems, the schema is often “flexible.” While we call them “schema-less,” they actually use “schema-on-read,” meaning the structure is applied when the data is pulled out, rather than when it is put in. This allows developers to iterate faster and store diverse types of information without migrating an entire database.
Star and Snowflake Schemas in Data Warehousing
In the world of Business Intelligence (BI), schemata take on specialized shapes. The Star Schema is perhaps the most famous. It consists of a central “fact table” (containing quantitative data like sales amounts) surrounded by “dimension tables” (containing descriptive data like dates, locations, and product names). The Snowflake Schema is a more complex version where dimension tables are further normalized into sub-dimensions. These structures are optimized specifically for fast data retrieval and complex analytical reporting.
Schema.org and the Semantic Web: How Search Engines Understand Data

The concept of schemata extends far beyond internal databases; it is also the language of the modern web. In 2011, Google, Bing, Yahoo!, and Yandex collaborated to create Schema.org, a standardized vocabulary for structured data on the internet.
The Evolution of Structured Data
In the early days of the web, search engines relied on “crawling” HTML text to guess what a page was about. If a page had the word “Apple,” the search engine had to guess if it meant the fruit, the tech company, or a record label.
Schema.org changed this by allowing web developers to use “markup” to explicitly tell the search engine what the content represents. By using a standardized schema, a developer can tag a piece of text as a <Product>, a <Recipe>, an <Event>, or a <Review>. This creates a “Semantic Web,” where machines don’t just see text, but understand the underlying concepts.
Enhancing SEO through Rich Snippets and JSON-LD
For tech-driven brands, implementing schemata is a vital part of Search Engine Optimization (SEO). When you search for a recipe and see a rating, a calorie count, and a cooking time directly in the search results, you are seeing the result of Rich Snippets. These snippets are powered by JSON-LD (JavaScript Object Notation for Linked Data), a format used to implement Schema.org vocabulary.
By providing search engines with a clear schema, websites increase their visibility and click-through rates. It bridges the gap between human-readable content and machine-readable data, making the internet more organized and intuitive.
Schemata in Artificial Intelligence and Machine Learning
As we enter the era of Generative AI and Large Language Models (LLMs), the role of schemata has shifted from simple data storage to complex knowledge representation.
Knowledge Graphs and Relationship Mapping
AI systems often rely on Knowledge Graphs, which are essentially massive, multi-dimensional schemata. A knowledge graph maps out entities and the nuances of their relationships. For instance, in a tech-focused knowledge graph, “Python” might be linked to “Programming Language,” which is linked to “Software Development,” which is linked to “Artificial Intelligence.”
This structured approach allows AI to perform “reasoning.” By following the nodes and edges of the schema, the AI can infer that because Python is a programming language used in AI, someone interested in AI might want to learn Python. This is how recommendation engines (like those on Netflix or Amazon) function at a high level.
Data Validation in Large Language Models (LLMs)
While LLMs like GPT-4 are trained on unstructured text, their practical application in enterprise tech often requires “schema enforcement.” For example, if a developer wants an AI to extract information from a legal contract and turn it into a JSON object for a database, they use a schema to define what the output should look like.
Without a schema to guide the AI’s output, the data might be hallucinated or formatted inconsistently. By applying a schema, developers can ensure that AI-generated data is “valid” and ready for use in traditional software applications.
The Future of Dynamic Schemata and Schema-less Design
The tech industry is currently navigating a tension between the rigid reliability of structured schemata and the agile flexibility of unstructured data.
Balancing Flexibility with Consistency
The future of software architecture seems to be heading toward a hybrid approach. We are seeing the rise of “Multi-model databases” that support both relational (SQL) and document-based (NoSQL) schemata within the same engine. This allows tech teams to keep their core financial data in a rigid schema while allowing their user-generated content to evolve in a flexible one.
Toward “Schema-on-Read” Architectures
With the advent of Data Lakes and Data Lakehouses, the “Schema-on-Read” approach is becoming more prevalent. In this model, data is dumped into a massive repository in its raw form. The schema is only applied when a data scientist or an AI tool queries the data. This provides maximum flexibility for data exploration and discovery, though it requires significant computational power to process on the fly.
Conclusion
Schemata are the invisible scaffolding of our digital world. They are the difference between a heap of data and a functional application. From the way a database stores your credit card information to the way a search engine understands your queries, and how an AI model maps human knowledge, schemata provide the essential logic required for technology to serve human needs.
As we move deeper into the age of AI and high-speed data processing, the mastery of schemata—whether through SQL, JSON-LD, or Knowledge Graphs—remains one of the most vital skills in the tech industry. It is not just about organizing data; it is about defining the very structure of digital intelligence.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.