In the rapidly evolving landscape of artificial intelligence, supervised learning and unsupervised learning often dominate the conversation. We frequently hear about large language models trained on massive datasets or algorithms that group consumer behavior into clusters. However, there is a third pillar of machine learning that is perhaps more reflective of how biological entities actually learn: Reinforcement Learning (RL). At the heart of this paradigm lies a powerful, model-free algorithm known as Q-learning.
Q-learning is the engine behind some of the most impressive feats in modern computing, from autonomous drones navigating complex environments to software agents outperforming human world champions in strategy games. It represents a shift from “learning by example” to “learning by experience.” This article explores the intricate architecture of Q-learning, its mathematical foundations, and its transformative role in the modern tech stack.
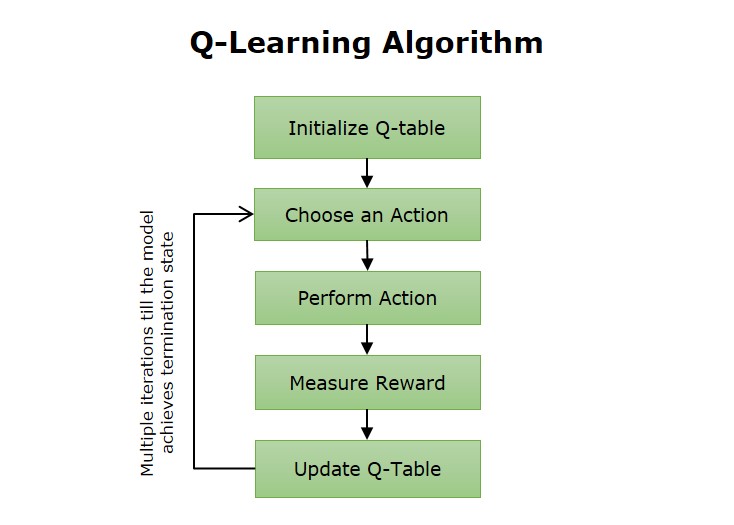
The Foundations of the Reinforcement Learning Framework
To understand Q-learning, one must first understand the framework of Reinforcement Learning (RL). Unlike supervised learning, where a model is given a set of labeled inputs and outputs, RL operates on a system of trial and error.
The Agent and the Environment
In any RL scenario, there are two primary entities: the Agent and the Environment. The Agent is the AI—the learner or decision-maker. The Environment is everything the Agent interacts with. If we were training an AI to play a video game, the Agent is the player-character, and the Environment is the game world, including the physics, the obstacles, and the enemies. The interaction is a continuous loop where the agent observes the environment, takes an action, and receives feedback.
States, Actions, and the Reward Signal
The “state” ($s$) represents the current situation of the agent within the environment. For a self-driving car, a state might include its speed, its position on a map, and the proximity of nearby obstacles. An “action” ($a$) is any move the agent can make from its current state—such as accelerating, braking, or turning left.
The most critical component is the Reward ($R$). This is a numerical value sent from the environment to the agent after an action is taken. Positive rewards encourage behavior, while negative rewards (penalties) discourage it. The ultimate goal of the agent is not just to get an immediate reward, but to maximize the total cumulative reward over time.
The Markov Decision Process (MDP)
Most Q-learning problems are framed as Markov Decision Processes. The core assumption of an MDP is the “Markov Property,” which states that the future depends only on the current state and action, not on the sequence of events that preceded it. This simplifies the computational load, allowing the agent to make decisions based on the “here and now.”
The Mechanics of Q-Learning: Tables, Values, and Equations
Q-learning is a “model-free” algorithm, meaning it does not need to understand the underlying physics or rules of the environment to succeed. Instead, it builds a “Q-table”—a cheat sheet of sorts—to track the quality of actions.
Understanding the Q-Values
The “Q” in Q-learning stands for Quality. A Q-value, denoted as $Q(s, a)$, represents the expected future rewards an agent can receive by taking action $a$ in state $s$. When the agent first begins, it knows nothing; the Q-table is filled with zeros or random numbers. As the agent explores, it updates these values based on the rewards it receives.
The Bellman Equation: The Logic of Learning
The mathematical heartbeat of Q-learning is the Bellman Equation. This formula allows the agent to update its Q-values based on new information. The simplified logic is:
*New Q-Value = Old Q-Value + Learning Rate * [Reward + (Discount Factor * Max Future Reward) – Old Q-Value]*
The Learning Rate (alpha) determines how much new information overrides old information. The Discount Factor (gamma) determines the importance of future rewards; a high gamma means the agent cares about long-term success, while a low gamma makes the agent “greedy” for immediate gratification.
Balancing Exploration and Exploitation
A significant challenge in tech development for RL is the Exploration-Exploitation trade-off. If an agent finds a path that yields a small reward, should it keep taking that path (exploitation), or should it try a new, unknown path in hopes of finding a bigger reward (exploration)?
Developers typically use an “Epsilon-Greedy” strategy. In the beginning, the agent has a high probability (Epsilon) of taking random actions to explore the environment. As the agent learns more, Epsilon decays, and the agent begins to exploit its knowledge by choosing the actions with the highest Q-values.

From Q-Tables to Deep Q-Networks (DQN)
While traditional Q-learning works perfectly for simple environments like a game of Tic-Tac-Toe, it hits a wall when faced with high-dimensional data. This is often referred to as the “Curse of Dimensionality.”
The Curse of Dimensionality
Imagine trying to create a Q-table for a modern high-definition video game or a real-world robotics application. There are millions of possible states (every pixel combination) and numerous possible actions. Storing this in a table is computationally impossible and memory-prohibitive. For AI to handle complex tech environments, the table needs to be replaced.
Integrating Deep Learning
In 2013, researchers at DeepMind revolutionized the field by combining Q-learning with Deep Neural Networks, creating the Deep Q-Network (DQN). Instead of looking up a value in a table, the agent passes the state into a neural network, which then predicts the Q-values for all possible actions. This allows the AI to generalize; it doesn’t need to see every exact state to know what a “good” action looks like, much like a human driver doesn’t need to have seen every specific intersection to know how to turn.
Experience Replay and Stability
Training deep neural networks with RL is notoriously unstable because the data is highly correlated (each state is very similar to the one before it). To solve this, developers use “Experience Replay.” The agent stores its experiences (state, action, reward, next state) in a memory buffer. During training, the agent takes a random sample from this buffer. This “shuffling” of experiences breaks the correlation and leads to much more stable learning.
Practical Implementations in Modern Technology
Q-learning is no longer a theoretical exercise confined to academic papers. It is a foundational technology used across various software and hardware sectors.
Autonomous Systems and Robotics
In robotics, Q-learning is used to teach machines how to walk, fly, or manipulate objects. Instead of hard-coding every motor movement—which is nearly impossible due to the unpredictability of the physical world—engineers set up a reward system. A walking robot gets a reward for distance traveled and a penalty for falling. Over thousands of iterations in a simulation, the Q-learning algorithm discovers the optimal gait.
Network Optimization and Cloud Computing
Tech infrastructure companies use Q-learning to manage data traffic and server loads. In a complex cloud environment, the “state” is the current traffic load, and the “action” is the routing of data or the spinning up of new virtual machines. Q-learning helps these systems find the most efficient pathways to minimize latency and energy consumption without human intervention.
Cybersecurity and Threat Detection
Modern digital security tools are beginning to employ RL to defend against polymorphic malware and sophisticated hacking attempts. A Q-learning agent can be trained to “defend” a network in a simulated environment, learning to recognize the states that precede a breach and taking proactive actions to isolate compromised nodes.
The Future of Q-Learning and Algorithmic Evolution
As we look toward the future of software development, Q-learning continues to evolve, spawning new variations that address its original limitations.
Overcoming Overestimation: Double Q-Learning
One known issue with standard Q-learning is that it tends to overestimate Q-values because it always takes the maximum possible future reward in its calculation. This can lead to sub-optimal policies. “Double Q-learning” uses two separate networks to decouple the action selection from the action evaluation, leading to more accurate value estimates and better performance in complex tech applications.
Transitioning to Continuous Action Spaces
Traditional Q-learning is designed for discrete actions (e.g., move left, move right). However, many real-world tech problems involve continuous actions (e.g., turning a steering wheel exactly 12.5 degrees). New algorithms like Deep Deterministic Policy Gradient (DDPG) build upon the foundations of Q-learning to bring these capabilities to autonomous vehicles and industrial automation.

The Path Toward General AI
Q-learning represents a vital step toward General Artificial Intelligence. By teaching machines to learn from their own interactions rather than just mimicking human-provided data, we are creating software that can solve problems humans don’t yet know how to solve. Whether it is optimizing the layout of a microchip or discovering new chemical compounds through simulated interaction, the principles of Q-learning—trial, error, and reward—remain the most promising path for creating truly intelligent, autonomous systems.
In conclusion, Q-learning is more than just a mathematical formula; it is a philosophy of machine intelligence. By quantifying “quality” and allowing software to explore the boundaries of its environment, we have unlocked a level of technological autonomy that was once the stuff of science fiction. As hardware becomes more powerful and neural networks become more sophisticated, the applications of Q-learning will only continue to expand, cementing its place as a cornerstone of the modern tech revolution.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.