Large Language Models (LLMs) have transformed how humans interact with technology, enabling advanced capabilities in natural language processing, content generation, and intelligent automation. Behind every conversational AI chatbot, every auto-completion suggestion, and every generated piece of text lies a critical process known as “inference.” Understanding LLM inference is fundamental to grasping how these powerful AI tools operate, their performance characteristics, and the engineering challenges involved in deploying them effectively.
Deconstructing Large Language Models (LLMs)
Before diving into inference, it’s essential to clarify the two primary stages of an LLM’s lifecycle: training and inference. These stages are distinct yet interdependent, with the latter directly leveraging the outcomes of the former.
The Training Phase: Learning from Data
The training phase is where an LLM acquires its knowledge and capabilities. During this computationally intensive process, the model is exposed to vast datasets of text and code, often comprising trillions of tokens. The model’s neural network architecture, typically a transformer, learns to identify patterns, grammatical structures, semantic relationships, and contextual nuances within this data. Through iterative adjustments of its internal parameters (weights and biases), the model minimizes a “loss function,” effectively learning to predict the next word in a sequence given previous words. This phase requires immense computational power, specialized hardware (like GPUs or TPUs), and significant time, sometimes spanning weeks or months for the largest models. The output of the training phase is a “trained model” – a frozen snapshot of the neural network’s parameters, ready to be used.
The Inference Phase: Applying Knowledge
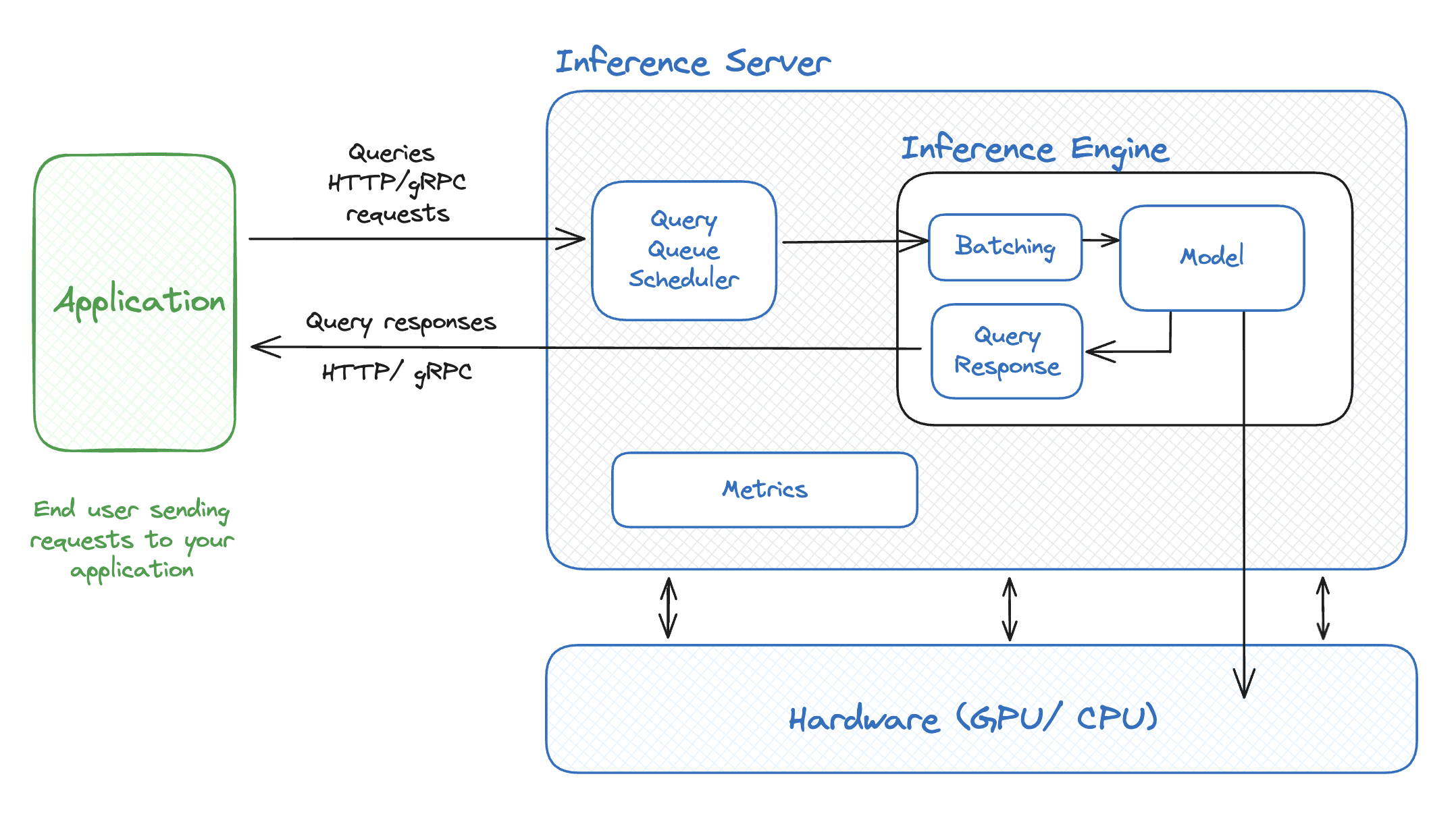
Inference, also known as prediction or forward pass, is the process of using a trained LLM to generate an output based on a new, unseen input. Once an LLM has been trained, it acts as a knowledge engine. When a user inputs a prompt or query, the model doesn’t “learn” in the traditional sense; instead, it applies the patterns and knowledge it gained during training to formulate a relevant response. This is the stage users experience directly when interacting with an AI assistant, generating an email, or summarizing a document. While training is about learning, inference is about applying that learned knowledge to produce a useful outcome in real-time or near real-time.
The Mechanics of LLM Inference
The journey from a user’s prompt to an LLM’s response involves several sequential steps, each crucial for accurate and efficient output generation.
Input Processing and Tokenization
The first step in inference is taking the raw text input from the user and preparing it for the model. LLMs don’t directly process words or characters; instead, they operate on “tokens.” Tokenization is the process of breaking down the input text into smaller units, which can be words, sub-word units (like “un-” or “-ing”), or even individual characters, depending on the tokenizer used. For example, “unbelievable” might be tokenized into “un”, “believe”, “able”. Each token is then mapped to a unique numerical ID from the model’s vocabulary and converted into a numerical vector (embedding) that the neural network can understand. This vectorization process adds contextual information, allowing the model to interpret the meaning of tokens in relation to others.
The Forward Pass: Generating Outputs
With the input tokenized and vectorized, it’s fed into the trained LLM’s neural network. This “forward pass” involves a series of complex matrix multiplications and activation functions across numerous layers of the transformer architecture. The model processes the input sequence, considering the relationships between all tokens, and predicts the probability distribution over its entire vocabulary for the next token in the sequence. This prediction is based on the patterns it learned during training.
Crucially, LLMs are auto-regressive. This means they generate text token by token. After predicting the first new token, that token is then appended to the original input (or the generated sequence so far), and the process repeats to predict the second new token. This iterative process continues until a stop condition is met, such as generating an end-of-sequence token, reaching a maximum specified length, or completing a coherent response.
Decoding Strategies: Crafting Coherent Responses
The raw output of the forward pass is a probability distribution over the vocabulary for the next token. A decoding strategy is then employed to select the actual token from this distribution. Simply picking the token with the highest probability (greedy decoding) can sometimes lead to repetitive or suboptimal responses. More sophisticated decoding strategies are used to balance creativity and coherence:
- Greedy Decoding: Always selects the token with the highest probability. Fast but can produce generic or repetitive text.
- Beam Search: Explores multiple promising sequences of tokens simultaneously. It keeps track of the ‘k’ most probable sequences (the ‘beam width’) at each step, making it more likely to find a globally optimal sequence, but at a higher computational cost.
- Sampling (e.g., Top-k, Nucleus/Top-p Sampling): Introduces an element of randomness to make responses more diverse and less deterministic.
- Top-k Sampling: Randomly samples the next token only from the
kmost probable tokens. - Nucleus (Top-p) Sampling: Samples from the smallest set of tokens whose cumulative probability exceeds a threshold
p. This dynamically adjusts the number of tokens considered based on the probability distribution, offering a good balance between randomness and quality.
- Top-k Sampling: Randomly samples the next token only from the
The choice of decoding strategy significantly impacts the quality, diversity, and coherence of the LLM’s output.
Key Challenges and Optimizations in LLM Inference
While inference is less computationally demanding than training, it still presents significant challenges, particularly for real-time applications and at scale. Efficient inference is crucial for making LLMs practical and accessible.
Computational Demands and Hardware Requirements
LLMs, especially the larger ones, have billions or even trillions of parameters. Each token generation step involves numerous matrix multiplications across these parameters. This requires substantial computational resources, primarily specialized hardware like Graphics Processing Units (GPUs) or Tensor Processing Units (TPUs), which are optimized for parallel processing. Running inference on CPUs is possible but significantly slower for large models.
Latency: Speeding Up Response Times
Latency, the time it takes for an LLM to generate a response, is a critical factor for user experience. High latency can make an application feel sluggish and unresponsive. Reducing latency is a major focus of inference optimization. Since LLMs are auto-regressive, generating one token at a time, the total response time scales with the length of the generated output.
Cost-Efficiency: Balancing Performance and Budget
Deploying and running LLMs for inference, especially at scale, can be expensive due to hardware costs and energy consumption. Optimizing inference reduces the computational load, allowing more queries to be processed with fewer resources, thereby lowering operational costs.
Model Quantization and Pruning
Several techniques are employed to make inference more efficient:
- Quantization: Reduces the precision of the model’s parameters (e.g., from 32-bit floating-point numbers to 8-bit or even 4-bit integers). This significantly reduces the model’s memory footprint and allows for faster computations, often with minimal impact on accuracy.
- Pruning: Removes less important connections or parameters from the neural network. This creates a “sparser” model that can be smaller and faster, though it requires careful identification of which parts to prune to avoid losing performance.
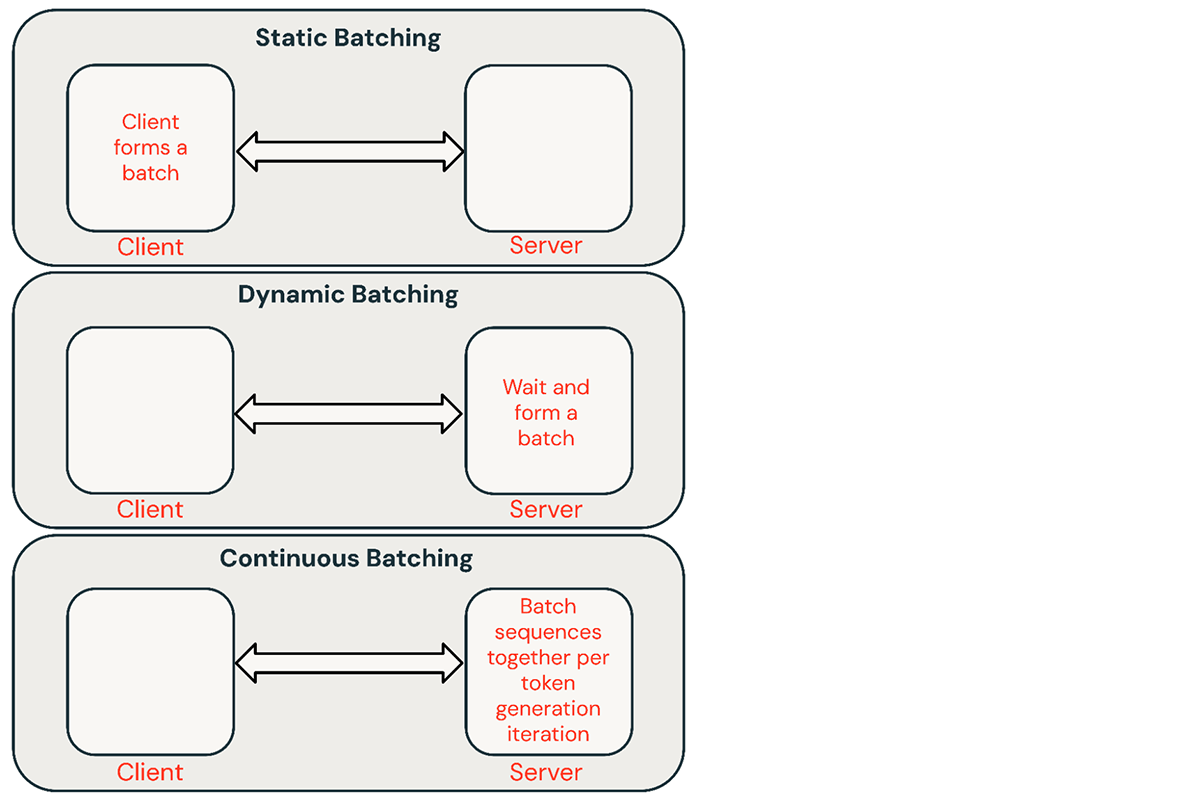
Batching and Parallel Processing
When processing multiple inference requests, “batching” can be used. Instead of processing each request sequentially, several requests are grouped into a batch and processed simultaneously. This takes advantage of the parallel processing capabilities of GPUs, leading to higher throughput (more responses per second) even if the latency for a single request might slightly increase. Advanced techniques like continuous batching or dynamic batching further optimize this by filling available compute capacity more effectively.
The Impact and Future of Efficient LLM Inference
The ability to perform LLM inference efficiently and at scale has profound implications across various technological domains.
Real-time Applications and User Experience
Efficient inference enables LLMs to power real-time applications such as conversational AI, customer service chatbots, and interactive content creation tools. Low latency ensures a smooth and engaging user experience, making AI interactions feel natural and responsive. As inference speeds improve, the scope of real-time AI applications will broaden significantly.
Enabling New AI Products and Services
Optimized inference makes it economically viable to integrate LLMs into a wider array of products and services. From intelligent search engines and personalized learning platforms to advanced coding assistants and creative writing tools, efficient inference democratizes access to powerful AI capabilities, driving innovation across industries. Startups and large enterprises alike can build scalable solutions without prohibitive operational costs.
Ethical Considerations and Responsible Deployment
As LLM inference becomes ubiquitous, ethical considerations around bias, fairness, transparency, and accountability become even more critical. Deploying models responsibly involves not only optimizing for performance but also understanding and mitigating potential harms. Efficient inference allows for more frequent model updates and fine-tuning, which can be crucial for addressing emerging ethical challenges and improving model safety over time. The future of LLM inference will likely involve a continuous push for not only faster and cheaper operations but also for more robust and ethically aligned outputs.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.