In the contemporary digital landscape, video content has become the primary medium for information exchange, entertainment, and professional communication. However, the utility of video is inherently limited if the auditory component is inaccessible. This is where captioning—a sophisticated technological process of converting audio into synchronized text—plays a critical role. While often confused with simple subtitling, captioning is a complex intersection of linguistics, software engineering, and artificial intelligence designed to ensure that digital media is inclusive, searchable, and versatile across various hardware and software environments.
Defining Captioning in the Digital Era
At its core, captioning is the process of displaying text on a visual display to provide additional or interpretive information to viewers. Unlike standard translation subtitles, captions aim to describe all significant audio content, including spoken dialogue, sound effects, and musical cues. From a technical perspective, captioning is a data layer that must be perfectly synchronized with the video and audio tracks of a file.

Open vs. Closed Captions: The Technical Distinction
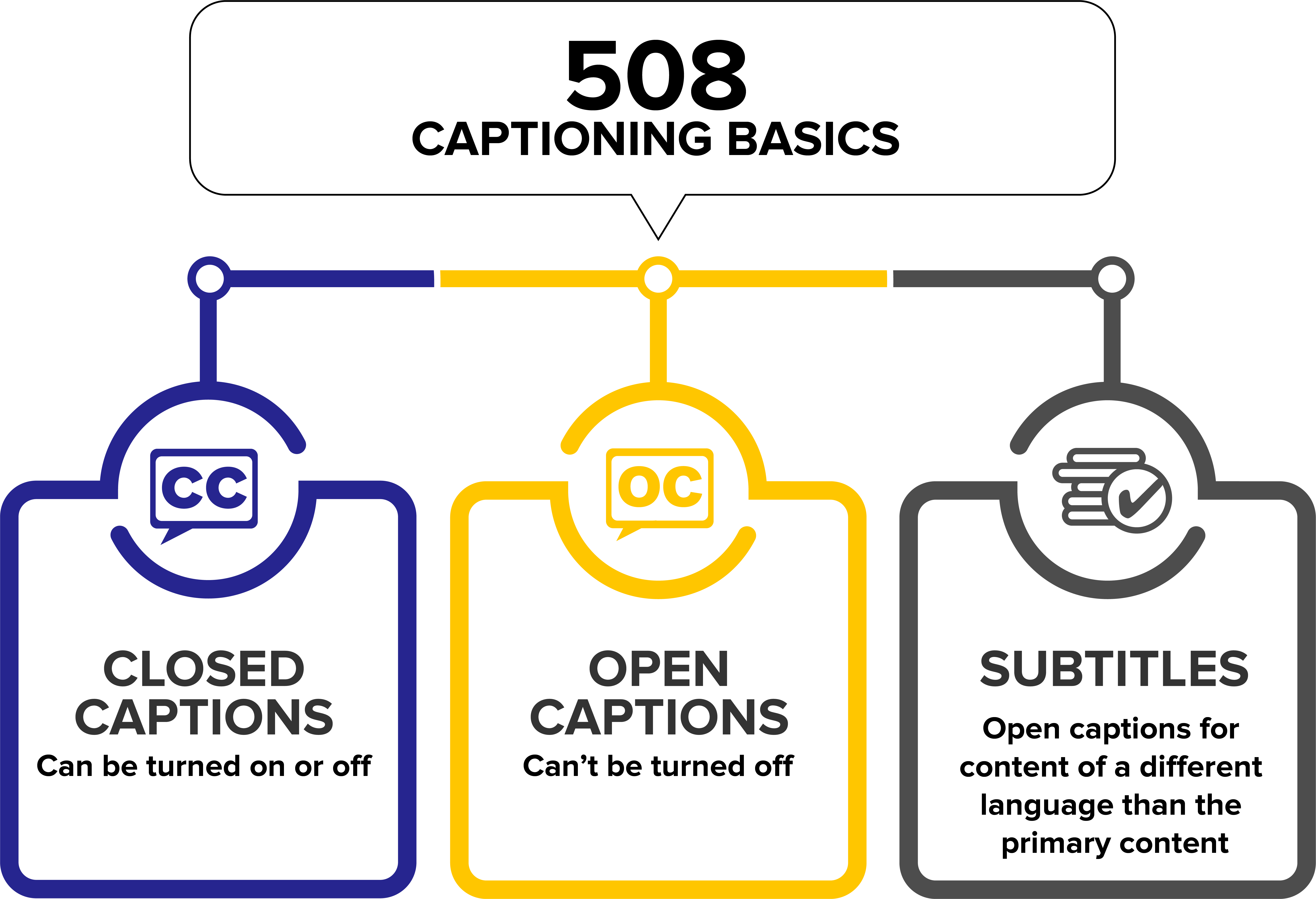
The primary technical divide in the world of captioning lies between “Open” and “Closed” formats.
Closed Captions (CC) are the industry standard for digital platforms. They exist as a separate data stream or sidecar file (such as an .SRT or .VTT file) that is multiplexed with the video. The viewer has the software-level control to toggle these captions on or off. Because they are rendered by the media player rather than the video itself, users can often customize the font size, color, and background through their device’s settings.
Open Captions (OC), conversely, are “burned-in” or hardcoded into the video frames during the post-production rendering process. There is no technical way for a user to disable them because the text has become part of the pixel data of the video. While this eliminates the risk of software compatibility issues, it removes user agency and prevents accessibility customization.
Subtitles vs. Captions: Not Just a Translation Issue
In tech circles, the terms are often used interchangeably, but they serve different technical functions. Subtitles assume the viewer can hear the audio but does not understand the language; thus, they only transcribe dialogue. Captions, specifically Subtitles for the Deaf and Hard of Hearing (SDH), assume the viewer cannot hear the audio at all. Therefore, the technical metadata of a caption file includes non-speech information like [Door Creaks] or [Tense Orchestral Music], which requires more sophisticated descriptive algorithms and timing.
The Technological Backbone: How Automated Speech Recognition (ASR) Works
The evolution of captioning has moved from manual human transcription to high-speed, AI-driven Automated Speech Recognition (ASR). This transition represents one of the most significant leaps in Natural Language Processing (NLP) over the last decade.
The Role of Natural Language Processing (NLP)
Modern captioning software utilizes deep learning models to process audio signals. The process begins with “feature extraction,” where the software breaks down the audio waveform into small fragments called phonemes—the smallest units of sound in a language.
The AI then uses a hidden Markov model or a neural network to predict the most likely sequence of words based on these phonemes. Advanced NLP engines go a step further by using “language modeling” to understand context. For example, a high-quality ASR engine can distinguish between “there,” “their,” and “they’re” by analyzing the surrounding syntax, a feat that was impossible for early-generation captioning tech.
Synchronicity and Time-Stamping Protocols
One of the most difficult technical hurdles in captioning is synchronization. For captions to be effective, the text must appear within milliseconds of the audio cue. Captioning software uses “time-stamps” (often formatted as Hours:Minutes:Seconds:Milliseconds) to anchor text blocks to specific frames in the video.

In live captioning—such as on Zoom, Microsoft Teams, or live news broadcasts—the challenge is “latency.” The system must ingest the audio, process it through the ASR engine, perform a contextual check, and output the text to the screen in under two seconds to maintain a coherent user experience. This requires massive computational power and optimized API pipelines.
Industry Standards and File Formats
To ensure that captions work across different devices—from an iPhone to a smart TV to a web browser—the tech industry relies on standardized file formats. These formats act as the “bridge” between the video player and the text data.
SRT, VTT, and SCC: Navigating the Alphabet Soup
- SubRip (.SRT): This is the most basic and widely supported caption format. It is a plain-text file that includes the sequence number, the time-stamped start and end points, and the text. Its simplicity makes it the “universal” format for social media platforms like YouTube and Facebook.
- WebVTT (.VTT): Created specifically for the HTML5 video standard, WebVTT is the “web-native” version of captioning. Unlike SRT, VTT supports CSS styling, allowing developers to define text alignment, colors, and even animations within the code.
- Scenarist Closed Caption (.SCC): This is a more technical format used primarily in broadcast television and DVD production. It represents data in a hexadecimal format and is designed to comply with CEA-608 and CEA-708 standards, which are the regulatory requirements for television accessibility.
Compliance and WCAG 2.1 Technical Guidelines
Captioning is not just a feature; in many jurisdictions, it is a technical requirement. The Web Content Accessibility Guidelines (WCAG) 2.1 provide a framework for how captions should be implemented. Technically compliant captions must meet criteria for “accuracy,” “placement” (not obscuring vital visual information), and “responsiveness” (scaling correctly on different screen sizes). For software developers, integrating captioning means ensuring that their video players are ARIA-compliant (Accessible Rich Internet Applications), allowing screen readers to interact with the caption data.
The Future of Captioning: AI, Real-Time Translation, and Beyond
As we look toward the future, captioning technology is moving beyond simple transcription and toward intelligent, real-time global communication.
Generative AI and Contextual Accuracy
The current frontier in captioning tech is the integration of Large Language Models (LLMs) like GPT-4 into the transcription pipeline. Traditional ASR often struggles with technical jargon, accents, or overlapping speakers. Generative AI can “read” the context of a video—for instance, recognizing that a video is a medical lecture—and automatically adjust its dictionary to prioritize medical terminology over common words. This reduces the Error Rate (ER) significantly, moving from the industry-average 80-85% accuracy to a near-human 99%.
Live Auto-Captioning and Machine Translation
Perhaps the most exciting tech trend is the marriage of captioning and Neural Machine Translation (NMT). We are approaching a point where a speaker can deliver a keynote in English, and viewers across the globe can receive live, AI-generated captions in Spanish, Mandarin, or French with sub-second latency. This involves a dual-processing stack: first, the ASR converts speech to text, and then the NMT translates that text into a target language while preserving the original time-stamps.
Speaker Identification and Diarization
Advanced captioning systems now employ “speaker diarization,” a technique that uses machine learning to identify and differentiate between different voices in a recording. Technically, the system creates a “voiceprint” for each participant. In the caption file, this is reflected by assigning different colors or labels to the text (e.g., [John]: Hello vs. [Jane]: Hi). This is a vital feature for multi-person tech conferences and remote board meetings, where knowing who is speaking is as important as what is being said.
Conclusion
Captioning has evolved from a niche broadcast requirement into a fundamental pillar of the global digital infrastructure. It is a field driven by rapid innovations in artificial intelligence, cloud computing, and software standardization. As video continues to dominate our digital lives, the technology behind captioning ensures that information is not just seen or heard, but understood by everyone, regardless of their hearing ability, language, or environment. For tech professionals and developers, mastering the nuances of ASR, file formats, and AI integration is no longer optional—it is essential for building the inclusive digital ecosystem of tomorrow.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.