In the high-stakes world of enterprise technology and software engineering, few scenarios are as terrifying as a sudden, total system paralysis. One moment, your infrastructure is humming along at peak efficiency; the next, users are reporting “the spinning wheel of death,” unresponsive interfaces, and a complete cessation of data flow. To an outside observer, or even a panicked IT administrator, these “stroke-like symptoms”—sudden loss of function, inability to communicate, and localized “paralysis” of specific features—often signal a catastrophic hardware failure or a fatal security breach.
However, just as in medicine, not every system-wide collapse is a terminal event. Many “digital strokes” are actually caused by underlying conditions that mimic total failure but are entirely reversible with the right diagnostic approach. Understanding what causes these symptoms is critical for maintaining uptime, optimizing software performance, and ensuring that temporary glitches do not lead to unnecessary and costly infrastructure overhauls.

The Anatomy of a Tech Stroke: Identifying Pseudo-Failures
When a piece of hardware or a complex software ecosystem exhibits “stroke-like” symptoms, it typically manifests as a sudden loss of responsiveness. The system may still be powered on, and certain background processes might even continue to run, but the “body” of the application is no longer reacting to external stimuli.
The Illusion of Hardware Death
Often, the first instinct during a system freeze is to blame the “organs”—the CPU, the SSD, or the motherboard. When a server stops responding to pings, it looks like a hardware stroke. Yet, frequently, the hardware is perfectly healthy. The symptoms are instead caused by a “kernel panic” or a driver conflict that has severed the communication lines between the operating system and the hardware. In these cases, the system isn’t dead; it is effectively locked in a state of “digital catatonia” where it cannot process new instructions because it is stuck in a logic loop.
Distinguishing Latency from Total Failure
In modern web architecture, high latency is often mistaken for a total system collapse. To a user, a website that takes 60 seconds to load might as well be offline. This “functional paralysis” mimics a stroke because the service is technically alive but practically useless. Identifying whether the issue is a “clogged artery” (network congestion) or a “ruptured vessel” (database corruption) is the first step in digital triage.
Common Culprits: What Mimics a System Stroke?
If the hardware is intact and the code is theoretically sound, what causes a system to suddenly “seize up”? In the tech industry, several common “lifestyle factors” of a software environment can trigger symptoms that look like a fatal crash.
Resource Exhaustion and Memory Leaks
A memory leak is perhaps the most common cause of stroke-like symptoms in software. Over time, an application fails to release the RAM it has used, gradually consuming all available resources. When the system hits a “memory wall,” it begins to swap data to the much slower hard drive (disk thrashing) or simply stops responding altogether. The application appears paralyzed, but the “brain” (the code) is actually fine—it just has no “room to think.”
Deadlocks in Multithreaded Environments
In the world of concurrent programming, a “deadlock” is the ultimate stroke mimic. This occurs when two or more processes are waiting for each other to release resources, resulting in a permanent stalemate. To the user, the app hasn’t crashed; it hasn’t disappeared from the task manager; it simply stops. It is frozen in time. Resolving a deadlock doesn’t require new hardware; it requires a logical intervention to break the cycle of dependency.
Cascading API Failures and Timeout Storms
We live in an era of microservices, where one application might rely on a dozen external APIs to function. If a secondary service—such as a payment gateway or a weather data provider—experiences a hiccup, it can cause a “stroke” in the primary application. If the primary app is not programmed with “circuit breakers,” it will wait indefinitely for a response that isn’t coming. This creates a bottleneck that looks like a localized failure of the main system, when in reality, it is a symptomatic response to a remote issue.
The AI Mirror: Hallucinations and Model “Seizures”

As Artificial Intelligence (AI) becomes integrated into our daily tech stacks, we are seeing a new category of stroke-like symptoms: cognitive failure in Large Language Models (LLMs) and neural networks. When an AI stops producing coherent output or begins to loop nonsensical phrases, it mimics a neurological event.
When AI “Freezes” or Loops
Large language models can sometimes enter a state of “repetition penalty failure,” where they generate the same word or phrase indefinitely. To the developer, the API is still returning tokens, but the utility of the output is zero. This isn’t a “crash” in the traditional sense; the server is running, and the GPU is hot. However, the model has lost its “functional coherence.” These symptoms are often caused by improper “temperature” settings or a lack of diversity in the sampling parameters, rather than a flaw in the model’s training.
Data Drift and Input “Poisoning”
A model that has worked perfectly for months may suddenly start producing erratic, “stroke-like” results. This is often “Data Drift”—where the real-world data being fed into the system no longer matches the data it was trained on. The system becomes confused, leading to output that looks like digital aphasia. The cure isn’t more processing power; it’s retraining or recalibrating the model to the new reality.
The Cybersecurity Factor: Malicious Mimicry
Not all “strokes” are accidental. In the realm of digital security, certain attacks are specifically designed to mimic system failure to distract IT teams or force a reboot into a vulnerable state.
Denial of Service (DoS) as Functional Paralysis
A classic Distributed Denial of Service (DDoS) attack creates a “stroke” by overwhelming the system’s “respiratory” capacity. By flooding a server with more requests than it can handle, the attacker effectively suffocates the service. The symptoms—unresponsiveness and time-outs—are identical to a major system failure, but the underlying cause is an external “pressure” rather than internal rot.
Ransomware and Systematic Freezing
Advanced ransomware doesn’t always crash a system immediately. Sometimes, it begins by selectively “paralyzing” background services—backups, shadow copies, and antivirus updates. These localized “mini-strokes” are precursors to a total system lockout. Recognizing these subtle, stroke-like interruptions in service can be the difference between a minor security incident and a total corporate blackout.
Prevention and Resuscitation: Building Digital Resilience
To prevent these “stroke-like” events, technology leaders must shift from a reactive mindset to a proactive, diagnostic one. Just as human health relies on monitoring and preventative care, system health relies on observability and redundancy.
Implementing Deep Observability
You cannot fix what you cannot see. Modern DevOps teams utilize “telemetry”—a constant stream of data regarding CPU usage, memory allocation, and request latency. Tools like Datadog, Prometheus, or New Relic act as the “MRI machines” of the tech world. By analyzing “heart rate” (requests per second) and “blood pressure” (server load), engineers can spot a memory leak before it causes a full-blown system stroke.
The Role of Redundancy and Circuit Breakers
In software engineering, a “circuit breaker” pattern is a failsafe that prevents a localized issue from causing a system-wide stroke. If an external API is slow, the circuit breaker “trips,” allowing the main application to continue functioning (perhaps with limited features) rather than waiting and freezing. Similarly, load balancing and “high availability” clusters ensure that if one “lobe” of the server infrastructure suffers a failure, the rest of the “brain” takes over the workload instantly.
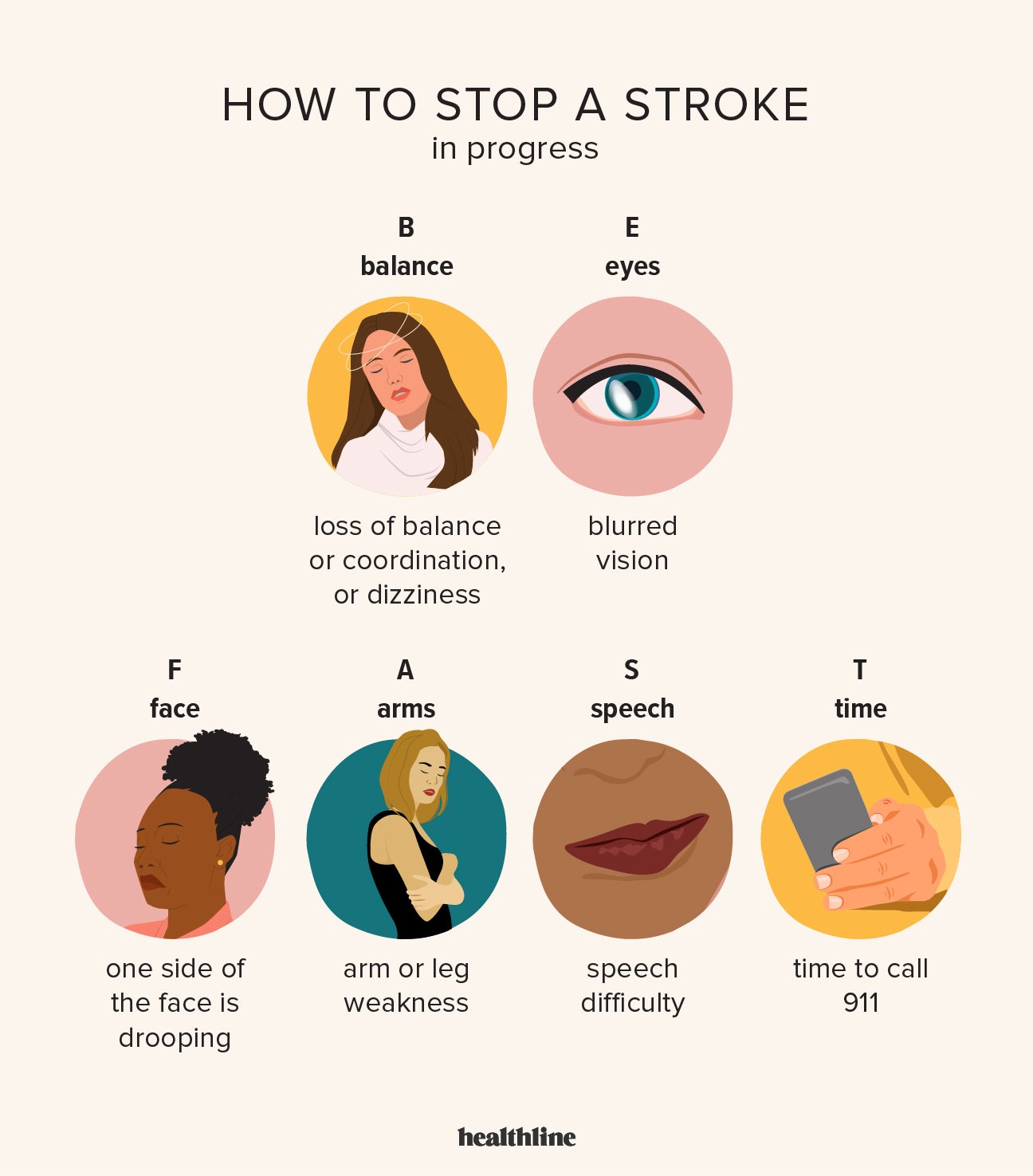
The Digital “F.A.S.T.” Check
In the medical world, F.A.S.T. (Face, Arms, Speech, Time) is used to diagnose a stroke. Tech teams can adopt a similar protocol for system checks:
- F (Flow): Is data still moving through the pipes?
- A (Access): Can users still authenticate and log in?
- S (Speed): Has latency spiked beyond acceptable thresholds?
- T (Telemetry): What do the logs say about the internal state?
By identifying “stroke-like” symptoms early and understanding that they are often caused by software bottlenecks, resource mismanagement, or external dependencies rather than fatal hardware failure, organizations can drastically reduce downtime. In the digital age, the ability to distinguish between a “glitch” and a “grave” is the ultimate competitive advantage.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.