In the realm of mathematics, functions serve as the foundational building blocks for understanding relationships between sets. However, when we transition from theoretical mathematics into the world of technology—specifically software engineering, database design, and artificial intelligence—the specific properties of these functions become critical tools for system architecture. Among these, the “onto function,” also known as a surjective function, stands out as a vital concept for developers and data scientists who must ensure that data flows efficiently and comprehensively across systems.
An onto function is more than just a calculation; it is a guarantee of coverage. In a technical landscape where “data gaps” can lead to system failures or biased AI models, understanding how to map one set of data onto another without leaving any part of the target space empty is essential. This article explores the mechanics of onto functions and their high-stakes applications in modern technology.
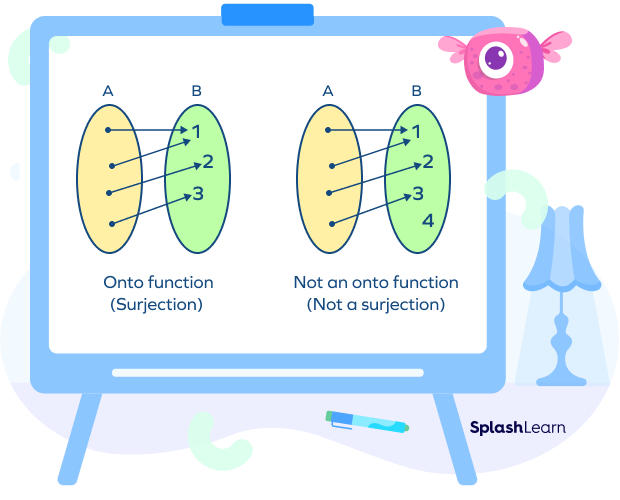
Understanding the Mathematical Foundation of Onto Functions
To appreciate the role of onto functions in tech, one must first grasp the core definition. In discrete mathematics, a function relates an input set (the domain) to an output set (the codomain). For a function to be considered “onto,” every single element in the codomain must be “hit” or mapped to by at least one element from the domain.
Defining Surjectivity in Data Science
In data science terminology, a surjective function ensures that the range of the function is exactly equal to its codomain. If you have a target dataset (Set B) and a source dataset (Set A), the transformation process is surjective only if every possible value in Set B is accounted for by the inputs in Set A. This is a critical concept when performing data normalization or transforming raw sensor data into actionable categories. If a categorization function is not onto, there may be “dead zones” in your data model—categories that exist in theory but can never be reached by the current input logic, potentially leading to “undefined” errors in production environments.
The Difference Between Into, One-to-One, and Onto Functions
Technologists often confuse these three types of mappings, but the distinctions are vital for logic design:
- Into Functions: Not every element in the target set is mapped. In software, this might represent an inefficient API that has endpoints that are never utilized.
- One-to-One (Injective): Each input maps to a unique output, but not all outputs are necessarily covered. This is the basis for unique identifiers like UUIDs.
- Onto (Surjective): Every output is covered, though multiple inputs might map to the same output. This is the hallmark of data aggregation and classification.
Understanding these distinctions allows software architects to choose the right mathematical model for the task at hand, whether they are building a simple search filter or a complex neural network.
Practical Applications in Software Engineering and Database Design
In software engineering, the theoretical concept of an onto function translates directly into system reliability and data integrity. When we design databases or build complex backend logic, we are essentially managing mappings between different states of information.
Ensuring Database Referential Integrity
Database normalization is arguably the most common practical application of onto functions. Consider a relational database for an e-commerce platform. You have a table of “Products” and a table of “Categories.” For a system to be logically sound and provide a good user experience, the relationship between Products and Categories should ideally be onto. This means that every category listed in the system must contain at least one product.
If the mapping is not surjective, the front-end application might display empty category pages, leading to a poor user experience and wasted crawl budget for search engine optimization. By enforcing surjective constraints at the architectural level, developers ensure that the system’s “state space” is fully utilized and that there are no orphaned categories that exist without underlying data.

Efficient Memory Allocation and Mapping
Lower-level systems programming also relies on the concept of surjectivity, particularly in memory management. When a virtual memory manager maps virtual addresses to physical memory addresses, it strives to ensure that the physical memory is utilized effectively. While this isn’t always a perfect onto function (due to fragmentation), the goal of high-performance computing is often to create a surjective mapping where every available physical memory block is addressable and utilized. This minimizes waste and ensures that the hardware’s capacity is fully leveraged by the software layer.
The Role of Onto Functions in Modern AI and Machine Learning
The explosion of artificial intelligence has brought functional mapping into the spotlight. Neural networks are essentially massive, multi-layered functions that transform high-dimensional input data (like pixels) into specific output classifications (like “cat” or “dog”).
Dimensionality Reduction and Feature Mapping
In Machine Learning, we often use techniques like Principal Component Analysis (PCA) or Autoencoders to compress data. This process involves mapping a high-dimensional space into a lower-dimensional “latent space.” For this latent space to be useful, the mapping function should ideally be onto. If the mapping is surjective, it means the latent space is fully representative of the potential features of the input data. This ensures that the model isn’t “missing” any possible variations in the data, which is crucial for generative models (like GANs or LLMs) to produce diverse and comprehensive outputs.
Neural Network Layers and Transformation Coverage
Each layer in a deep learning model acts as a function. If a specific layer’s activation function is not surjective regarding the necessary feature space, it can lead to “dying neurons”—a phenomenon where certain parts of the network stop contributing to the learning process because they never output a value that influences the final result. By ensuring that transformations remain surjective where appropriate, AI researchers can maintain the “expressive power” of a network, allowing it to cover the entire range of possibilities required for complex decision-making.
Security Implications: Hashing and Cryptography
Digital security is another field where the properties of functions are a matter of life and death for data. While cryptographic hash functions (like SHA-256) are generally designed to be “collision-resistant” (approaching injective properties), the concept of the onto function plays a subtle but important role in entropy and randomness.
Collision Resistance vs. Surjectivity
In a perfect world, a hash function would be surjective over its entire bit-space, meaning every possible hash value could eventually be produced. If a hash function were discovered to be non-surjective—meaning a large portion of its output space could never be reached—it would significantly reduce the “keyspace” that an attacker would need to search. This would make brute-force attacks much easier. Therefore, while we don’t want two different inputs to result in the same output (collision), we do want to ensure that the function “covers” the output space as broadly as possible.
Strengthening Encryption Through Balanced Mappings
In symmetric encryption, the process of scrambling data must be a “bijection”—a function that is both one-to-one (to ensure unique decryption) and onto (to ensure every possible encrypted block is a valid state). If the encryption function were not onto, the resulting ciphertext would have detectable patterns or “forbidden states,” which cryptanalysts could exploit to break the code. Surjectivity ensures that the ciphertext looks like pure, unpredictable noise, which is the gold standard for secure communications.

Conclusion: Why Surjectivity Matters for Tech Professionals
As we have seen, the concept of onto functions is far from a dry mathematical theory. It is a vital framework for ensuring that technical systems are comprehensive, efficient, and secure. From the way a database organizes product categories to the way a neural network understands the world, the requirement that every output must be accounted for is a fundamental principle of robust engineering.
For developers, architects, and data scientists, thinking in terms of onto functions encourages a “total coverage” mindset. It prompts critical questions during the design phase: Is every possible system state reachable? Are there “dead” endpoints in our API? Does our AI model utilize its full representational capacity? By mastering the logic of surjectivity, tech professionals can build systems that are not only functional but are mathematically optimized to handle the complexities of the modern digital landscape. In a world driven by data, ensuring that no point in your target space is left behind is the key to building the next generation of reliable technology.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.