The evolution of human language is a complex, sprawling map of cultural shifts, societal taboos, and biological imperatives. For centuries, the study of the “first cuss word” was the domain of traditional etymologists—scholars who spent lifetimes poring over dusty manuscripts and ancient inscriptions. However, in the modern era, the quest to identify the origins of profanity has shifted from the library to the data center. Through the lens of technology, specifically computational linguistics and Big Data, we are finally able to deconstruct the history of taboo language with surgical precision. Understanding the “first cuss word” is no longer just a trivia question; it is a fundamental challenge for developers building Natural Language Processing (NLP) models and digital safety protocols.

The Intersection of Computational Linguistics and Taboo
To understand how technology identifies the origin of profanity, we must first look at the tools used to map language evolution. Computational linguistics is the field where computer science meets the study of speech. By digitizing millions of historical documents—from Sumerian clay tablets to Victorian court records—researchers have created massive datasets that allow algorithms to track the frequency and context of specific words over millennia.
From Parchment to Pixels: Digitizing the History of Speech
The primary hurdle in identifying the “first” cuss word is the lack of written evidence for early colloquialisms. Historically, profanity was often spoken but rarely written, as scribes and printers acted as the “moderators” of their time. However, modern digitization projects like the Google Books Ngram Viewer and the HathiTrust Digital Library have provided AI with a playground of historical data. By using Optical Character Recognition (OCR), technology has resurrected words that were previously buried in unindexed archives. AI can now scan for “lexical spikes”—moments where a word suddenly gains negative social weight—to determine when a neutral term evolved into a profanity.
The Role of Natural Language Processing (NLP) in Linguistic Mapping
NLP is the technology that allows machines to understand, interpret, and generate human language. When investigating the origins of cuss words, NLP models utilize sentiment analysis to gauge the “emotional temperature” surrounding a word in historical texts. For example, an algorithm can analyze the surrounding adjectives and verbs in a 14th-century manuscript to determine if a word was being used descriptively or as an invective. This technology helps differentiate between a word that describes a biological process and a word used to offend, allowing us to pinpoint the exact era when a word truly became “profane.”
Searching for the First Cuss: The Algorithmic Approach
While humans might debate whether the first cuss word was related to theology (blasphemy) or biology (excrement/sex), AI provides a more objective, data-driven perspective. By analyzing the earliest known written records, technology identifies the root “proto-words” that eventually became the four-letter words we recognize today.
Identifying the Roots: The Indo-European Data Sets
Using phylogenetic trees—tools usually reserved for biological evolution—computational linguists have traced the lineage of common profanities back to the Proto-Indo-European (PIE) language, spoken over 5,000 years ago. Algorithms designed for pattern recognition have identified that the earliest “taboo” words were likely related to the violation of religious oaths. Data suggests that the concept of a “cuss” (derived from “curse”) preceded modern vulgarities. In the ancient world, to “curse” someone was to invoke a literal supernatural punishment. AI-driven analysis of ancient Hittite and Sanskrit texts reveals that the most severe linguistic violations were not anatomical, but spiritual—breaking a covenant or misusing a deity’s name.
Cultural Context vs. Literal Meaning: The Challenge for Machine Learning
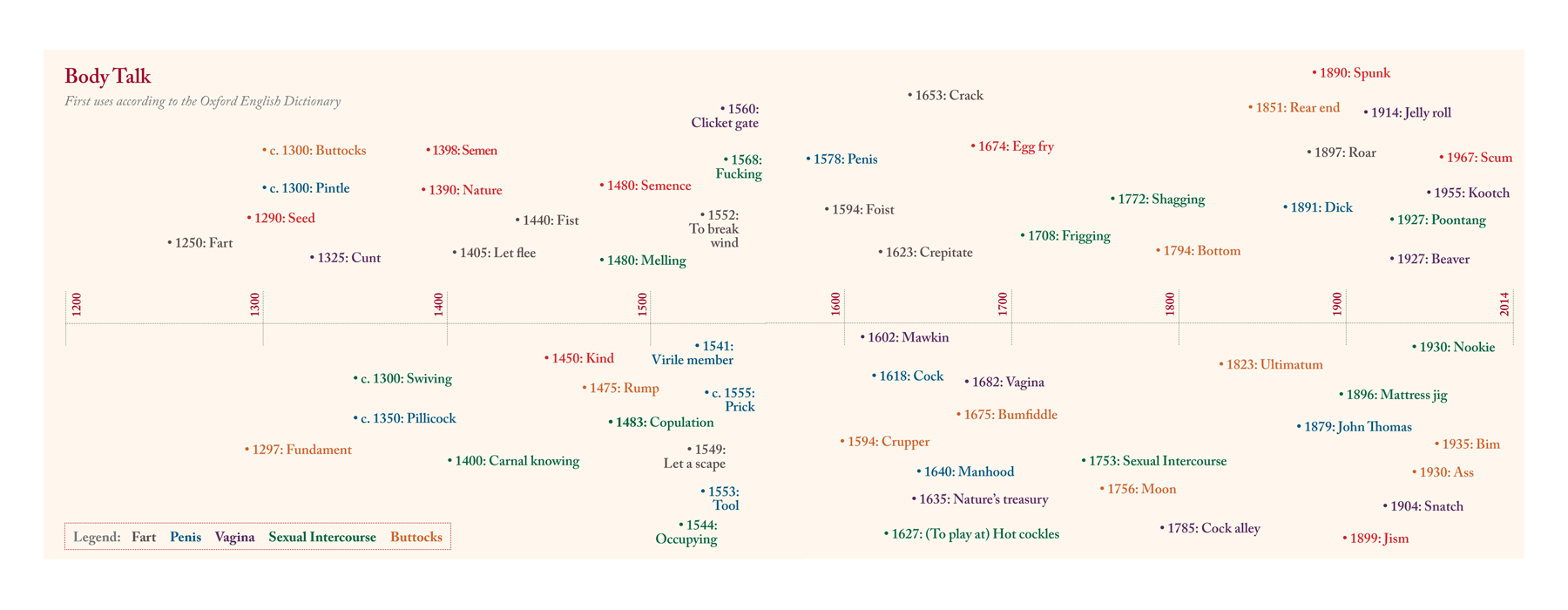
One of the greatest challenges for tech in this niche is “contextual drift.” A word that is a severe cuss word in 2024 might have been a standard trade term in 1224. Machine learning models must be trained on “historically aware” datasets to avoid false positives. For instance, the word “fart” (one of the oldest documented words in the English language, appearing in the 13th-century Sumer Is Icumen In) was once considered relatively mild or even humorous rather than strictly taboo. AI helps us map this transition by analyzing the frequency of “euphemistic substitution”—the moment when writers start using dashes or symbols to hide a word, signaling its official status as a cuss word.
Content Moderation and the Evolution of Digital ‘Bleeping’
The history of the first cuss word is not just a matter of historical record; it is a functional requirement for modern digital security and software development. Every major social media platform, gaming ecosystem, and AI chat tool relies on “profanity filters.” These filters are essentially the modern digital descendants of the ancient cultural taboos we are researching.
Sentiment Analysis and the Weight of Words
Modern tech companies use sentiment analysis to determine the “toxicity score” of language. By understanding the etymology and historical weight of cuss words, developers can better calibrate how AI handles offensive content. If a word has been a high-level taboo for 500 years, the algorithm assigns it a higher weight than a “slang” word that may only be temporarily offensive. This allows for more nuanced moderation, where the AI can distinguish between a user expressing frustration and a user violating safety policies.
The Ethical Dilemma of Training LLMs on Offensive Language
As we develop Large Language Models (LLMs) like GPT-4 or Claude, a significant tech challenge arises: do we teach the AI the “first cuss words”? To be a truly fluent communicator, an AI must understand what is offensive and why. If an AI doesn’t understand the history and weight of the “first cuss word,” it cannot effectively filter it or explain why it is inappropriate in certain contexts. However, training models on “the darker side” of the internet to teach them what not to say creates a feedback loop that developers must carefully manage through Reinforcement Learning from Human Feedback (RLHF).
The Future of Linguistic Tech: Real-time Etymology and Adaptive AI
As we move forward, the technology used to trace the first cuss word will become even more integrated into our daily digital interactions. We are entering an era of “adaptive linguistics,” where software can track the birth of new taboos in real-time across the internet.
Predicting the Next Generation of Taboos
By using predictive analytics, tech companies can actually forecast which words are likely to become the “cuss words” of the future. By monitoring “linguistic saturation” on platforms like X (formerly Twitter) and Reddit, AI can identify when a neutral term is being “weaponized.” This proactive approach to digital etymology allows for faster updates to safety protocols and a deeper understanding of how human society creates new boundaries. Just as the first cuss word was likely a product of tribal boundaries and religious fears, modern cuss words are products of digital echo chambers and social polarization.

The Democratization of Historical Research
Perhaps the most significant tech trend in this field is the democratization of etymology. Cloud-based research tools and open-source datasets mean that a student in a bedroom can run the same linguistic queries that were once reserved for Ivy League labs. We are no longer reliant on a single “expert” to tell us what the first cuss word was; we have the raw data, the processing power, and the algorithms to see the evolution of language for ourselves. This transparency is a hallmark of the modern tech era, turning the study of profanity into a collaborative, data-driven science.
In conclusion, while the “first cuss word” may have been whispered in a cave or inscribed on a piece of ancient clay, its legacy is being mapped by the most advanced technology of the 21st century. Through the intersection of Big Data, NLP, and historical digitization, we are gaining unprecedented insight into the human psyche and the words we use to express our deepest frustrations and fears. Technology doesn’t just filter our language—it explains it, tracing the four-letter words of today back to the very dawn of human communication.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.