In the biological world, the mouth serves as the critical entry point where complex substances are broken down into manageable components before they ever reach the central processing units of the body. In the rapidly evolving landscape of information technology, we see a striking parallel. When we ask “what type of digestion occurs in the mouth” through a technological lens, we are exploring the critical “Data Ingestion” phase. This is the stage where raw, unstructured data is first encountered, filtered, and prepared for deeper analysis.
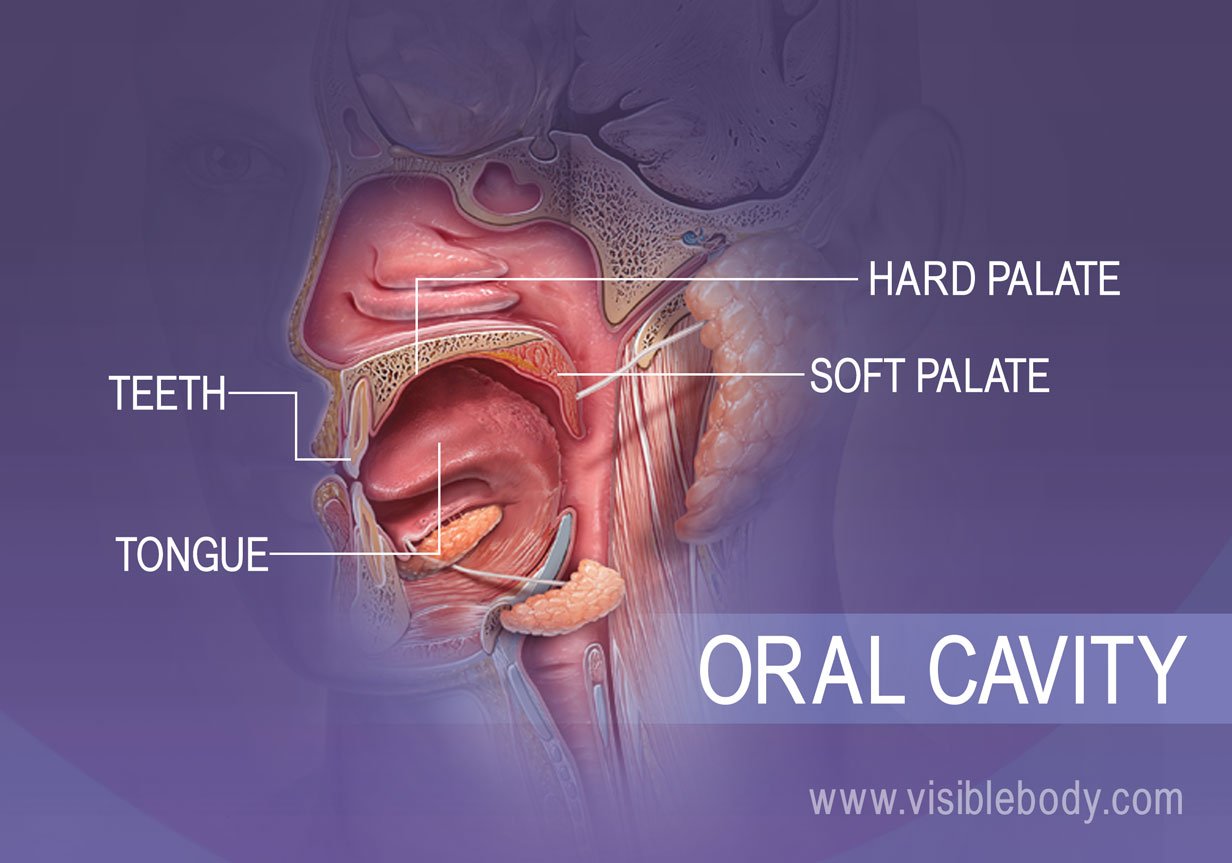
Just as human digestion involves both mechanical and chemical processes to ensure nutrients can be absorbed, digital systems must “digest” incoming streams of information at the edge of the network. Without this preliminary digestion, the central “stomach”—the cloud or the core data warehouse—would be overwhelmed by indigestible noise.
The Anatomy of Digital Ingestion: The “Mouth” of the System
In a sophisticated tech stack, the “mouth” represents the interface between the external environment and the internal database. This includes everything from IoT sensors and user-facing APIs to web scrapers and mobile application front-ends. The “digestion” that occurs here is the first line of defense and the primary stage of optimization.
Mastication in Tech: Breaking Down Unstructured Data
Mechanical digestion in humans involves breaking food into smaller pieces. In technology, this is mirrored by the process of data parsing. When a system receives a massive, monolithic file—perhaps a 10GB log file or a high-definition video stream—it cannot be processed as a single unit without risking system latency.
“Mechanical” digital digestion involves breaking these streams into packets or “chunks.” By segmenting data at the ingestion point, systems can distribute the load across multiple microservices. This ensures that the system doesn’t “choke” on the volume of information, allowing for parallel processing that mimics the efficiency of a well-functioning biological system.
Identifying the Salivary Enzymes: Automated Metadata Tagging
Biological digestion uses enzymes to begin the chemical breakdown of food. In the tech world, metadata serves as these enzymes. As data enters the “mouth” of the platform, automated scripts and AI agents attach tags that describe the nature of the data: its origin, its timestamp, its file type, and its priority level.
This preliminary “chemical” breakdown is essential because it informs the rest of the system how to handle the data. Without metadata tagging at the point of entry, the central processing unit would have to spend valuable resources simply identifying what it is looking at, rather than analyzing its value.
Real-Time Processing at the Edge: Why the “Mouth” Matters
In modern architecture, we no longer wait for data to reach the central server to begin processing. This shift toward “Edge Computing” represents a specialized form of digestion that occurs entirely within the “mouth” of the network.
Edge Computing as the Primary Digestive Tool
Edge computing refers to the practice of processing data near the source of its generation. For example, a self-driving car generates terabytes of data every hour. If that car had to send every single byte to a central cloud server to decide whether to hit the brakes, the latency would be fatal.
Instead, the “digestion” happens at the edge—right in the vehicle’s onboard computer. This local processing filters out the “noise” (like the color of a passing bird) and focuses only on the “nutrients” (the distance to the car in front). By digesting the data locally, the system ensures real-time responsiveness and reduces the bandwidth required to communicate with the central hub.
Reducing Latency: The Need for Speed
In the tech world, latency is the equivalent of indigestion. It slows down the user experience and can lead to system failures. By performing initial digestion in the mouth of the system, companies can achieve “sub-second” latency. This is particularly vital in financial tech (FinTech), where the “digestion” of market data must happen in microseconds to execute high-frequency trades. The faster the mouth can process and filter the incoming “food,” the more agile the entire organization becomes.

AI and Machine Learning: Refining the “Taste” of Data
As artificial intelligence becomes more integrated into software development, the “mouth” of the system is becoming smarter. We are moving away from simple filtering and toward “Semantic Digestion,” where the system understands the context of the information it is consuming.
Sifting the Nutrients from the Waste: AI Filtering
Not all data is useful. In fact, a significant portion of the data generated by users and machines is “trash”—redundant information, bot traffic, or corrupted packets. Intelligent ingestion layers use machine learning models to act as a “taste bud” for the system.
These models are trained to recognize patterns of high-value data and separate them from the waste. For instance, an e-commerce platform’s ingestion layer might identify a “bot-like” browsing pattern and discard that data immediately, preventing it from skewing the analytics used by the marketing team. This ensures that only the “nutrients” reach the core business intelligence tools.
Natural Language Processing (NLP) as Semantic Digestion
When we talk about voice assistants like Alexa or Siri, the “mouth” of the system is the microphone and the NLP engine. Here, the digestion is purely semantic. The system takes raw audio waves and “digests” them into intent and entities. This is a complex form of pre-processing where the “mouth” must understand nuances, accents, and context to provide a meaningful response. This type of digestion is what allows for a seamless interaction between human biology and digital technology.
Security Protocols: The Immune System of Data Ingestion
The mouth is not just a place for digestion; it is also a gateway that must be guarded. In biology, the mouth contains tonsils and specialized cells to catch pathogens. In the tech niche, this translates to the security measures implemented at the ingestion layer.
Guarding the Entryway: Firewalls and Authentication
Every time data enters a system, it poses a risk. Malware, SQL injection attacks, and DDoS attempts all try to enter through the “mouth.” Therefore, the type of digestion that occurs here must include a rigorous screening process.
Web Application Firewalls (WAF) and Identity Access Management (IAM) systems act as the gatekeepers. They “digest” the credentials of the incoming data packets to ensure they have the right to enter. If the “food” is found to be toxic, the system rejects it immediately, protecting the “stomach” (the database) from infection or corruption.
Preventing Toxic Ingestion: Validation and Sanitization
Data sanitization is a critical part of the digital digestive process. Before any data is stored, it must be “cleaned.” This involves stripping away potentially malicious code and ensuring that the data conforms to the expected format. For example, if a user input field expects a phone number, the “mouth” of the system must digest that input and reject any characters that aren’t numbers. This level of scrutiny at the point of entry is the hallmark of a secure and robust software architecture.
Future Trends: The Evolution of Digital Digestion
As we look toward the future, the “mouth” of our technological systems will become even more sophisticated, driven by advancements in hardware and decentralized networks.
Quantum Ingestion: The Next Evolutionary Leap
While still in its infancy, quantum computing promises to revolutionize how we digest information. A quantum “mouth” would be able to process multiple states of data simultaneously, allowing for the ingestion of incredibly complex datasets—such as global climate models or genomic sequences—in a fraction of the time it takes today’s binary systems.
Autonomous Data Architectures
We are moving toward a world where the “mouth” of the system is self-healing and self-optimizing. Using “AIOps” (Artificial Intelligence for IT Operations), the ingestion layer can detect its own bottlenecks and “re-digest” data more efficiently without human intervention. This autonomy represents the peak of technological evolution, where the system manages its own health and nutritional needs to ensure peak performance.
In conclusion, when we examine “what type of digestion occurs in the mouth” through the lens of technology, we discover a complex, multifaceted process of data ingestion, edge processing, and security validation. This initial stage is perhaps the most critical part of the data lifecycle, determining the speed, security, and intelligence of the entire system. By perfecting the “mouth,” tech innovators ensure that their systems are not just consuming data, but truly thriving on it.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.