In the rapidly evolving landscape of Educational Technology (EdTech), the ability to quantify human capability and content difficulty is paramount. Among the most significant innovations in this space is the Lexile Framework for Reading. Developed by MetaMetrics, the Lexile measure is more than just a score; it is a sophisticated, data-driven metric that facilitates a scientific approach to literacy. By leveraging complex algorithms and linguistic data, the Lexile Framework provides a common scale for matching readers with text, effectively bridging the gap between student ability and content complexity.
As digital learning platforms become more personalized, understanding the mechanics of the Lexile measure is essential for software developers, educators, and tech-savvy parents. This article explores the technical foundations of Lexile measures, their integration into modern software ecosystems, and how the future of AI is shaping the way we quantify readability.
The Algorithm Behind the Measure: How Text Complexity is Quantified
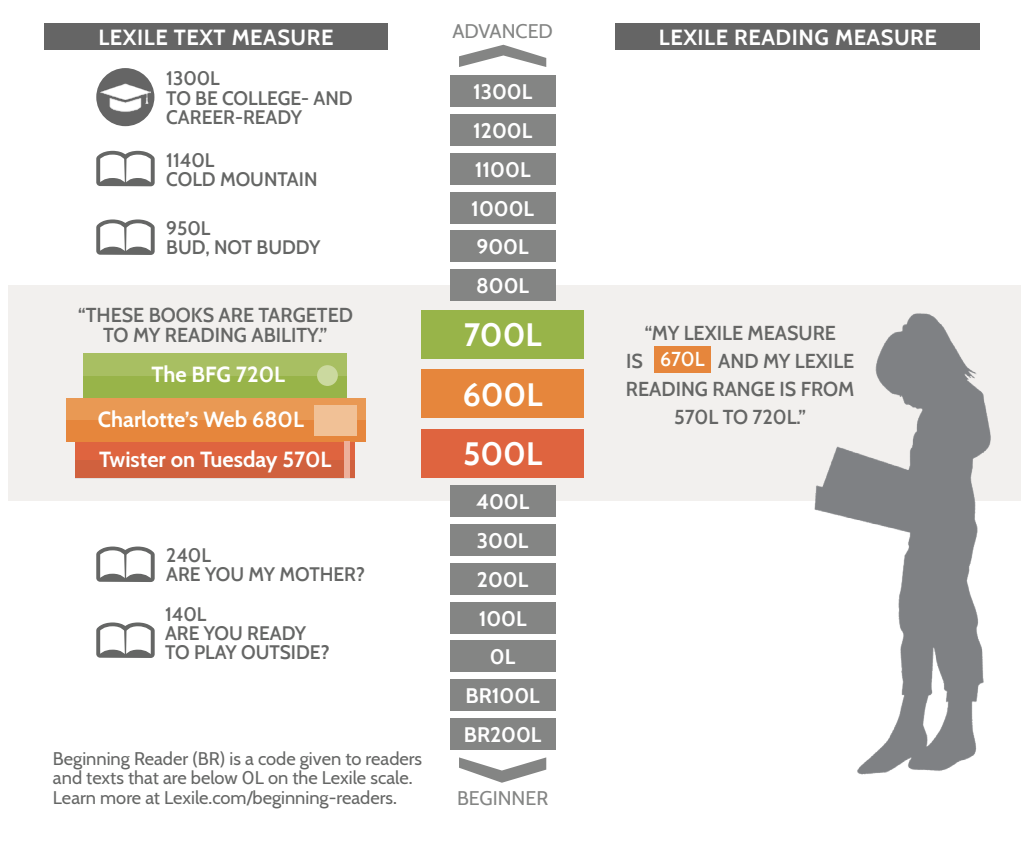
At its core, the Lexile measure is a product of computational linguistics. Unlike traditional readability formulas that might simply count syllables or word length, the Lexile Framework uses a proprietary algorithm to analyze the semantic and syntactic characteristics of a text. This generates a “Lexile measure,” represented by a number followed by an “L” (e.g., 800L), which can range from below 0L (Beginning Reader) to above 1600L.
Semantic Difficulty and Word Frequency Data
The semantic component of the Lexile algorithm focuses on the difficulty of the individual words within a text. This is not merely a matter of how many letters a word has, but rather its frequency within the “Lexile Corpus”—a massive database of billions of words compiled from a diverse array of published materials.
From a technical standpoint, the algorithm calculates the “log-likelihood” of a word appearing in standard discourse. High-frequency words (like “the,” “and,” or “house”) result in a lower Lexile measure, while low-frequency, specialized, or technical terms (like “mitochondria” or “arbitrage”) drive the measure higher. This data-centric approach allows the software to account for the actual exposure a reader likely has to specific vocabulary, providing a more accurate assessment of “semantic demand” than simple syllable counting.
Syntactic Complexity and Sentence Construction
The second pillar of the Lexile algorithm is syntax, which refers to the arrangement of words and the complexity of sentence structures. The framework operates on the data-validated principle that longer sentences tend to contain more complex grammatical structures, such as prepositional phrases, dependent clauses, and appositives.
The software processes text by measuring the average sentence length across a work. However, the calculation is far from a simple average. The algorithm applies logarithmic transformations to the data to ensure that the relationship between sentence length and difficulty is appropriately weighted. By analyzing these syntactic patterns, the Lexile engine can determine the cognitive load required for a reader to process the relationship between ideas within a sentence, providing a high-fidelity representation of text complexity.
The Digital Ecosystem of Lexile: Integration into Apps and Educational Platforms
One of the reasons the Lexile measure has become a global standard is its high level of interoperability within the EdTech ecosystem. Modern educational apps and Learning Management Systems (LMS) do not just display Lexile scores; they integrate them into their core architecture to drive user experience and pedagogical outcomes.
API Integration in Modern Reading Software
For developers of digital libraries and literacy apps, the MetaMetrics API is a critical tool. This API allows platforms to instantly retrieve the Lexile measure for millions of books and articles. When a user logs into a reading app, the software can ping the database to cross-reference the user’s current reading level with the available content.
This technical integration enables “smart filtering.” Instead of a student browsing a chaotic digital library, the backend logic of the app presents a curated “Power V” range—usually 100L below to 50L above the student’s current measure. This data-driven curation ensures that the content is neither too easy (leading to boredom) nor too difficult (leading to frustration), optimizing the “Zone of Proximal Development” through software automation.
Adaptive Learning Engines and Personalized Content Delivery
The true power of the Lexile measure in tech is seen in adaptive learning engines. Platforms like Newsela or Achieve3000 use the Lexile Framework to provide “leveled content.” In these systems, a single news story might exist in five different versions, each tagged with a different Lexile measure.
The software employs a feedback loop: as a student interacts with the text and completes embedded assessments, the system analyzes their performance data. If the student consistently succeeds at a 700L version of an article, the algorithm automatically adjusts the difficulty of the next piece of content to 750L. This real-time, data-driven adjustment is a hallmark of modern EdTech, transforming the Lexile measure from a static label into a dynamic component of personalized learning algorithms.
AI and the Future of Readability Assessment
As we move further into the era of Generative AI and Large Language Models (LLMs), the way we calculate and utilize readability measures like Lexile is undergoing a transformation. The intersection of traditional psychometrics and modern Natural Language Processing (NLP) is creating new frontiers for EdTech.
Machine Learning vs. Traditional Lexile Frameworks
While the traditional Lexile algorithm is highly reliable, it is a “closed-box” formula based on specific linguistic variables. Modern machine learning models, however, can analyze text using thousands of features, including sentiment, cohesion, and rhetorical structure.
The tech industry is currently exploring how to combine the standardized reliability of Lexile measures with the nuanced understanding of AI. For instance, AI can now detect if a text’s difficulty is driven by abstract concepts rather than just complex vocabulary. Integrating these AI insights with the Lexile scale allows for a more multidimensional view of text complexity, helping developers create tools that understand not just if a text is hard, but why it is hard.
Natural Language Processing (NLP) in Real-Time Analysis
One of the most exciting trends in EdTech is the move toward real-time Lexile analysis of user-generated content. Previously, getting a Lexile measure for a text required submitting it to MetaMetrics for formal evaluation. Today, NLP-powered tools can provide “on-the-fly” estimates of Lexile measures for any digital text.
This has profound implications for digital accessibility. Browser extensions can now analyze a webpage’s content in real-time and provide a Lexile estimate, helping users determine if a technical manual or a news site matches their reading proficiency. For developers, this means the ability to build “readability checkers” directly into content management systems, ensuring that corporate communications or educational materials are calibrated for their intended audience before they are even published.
Leveraging Lexile Data for Content Personalization in the Digital Age
The ultimate goal of any EdTech tool is to facilitate growth. The Lexile Framework achieves this by providing a longitudinal scale—a consistent way to track progress over years of digital interaction. This data persistence is a key feature for modern data analytics in education.
Data-Driven Literacy Growth Tracking
In a tech-forward classroom, every interaction a student has with a digital text generates a data point. By aggregating these Lexile-linked data points, software platforms can generate “growth trajectories.” These are predictive models that show where a student’s reading level is likely to be in six months or a year based on their current engagement.
For EdTech administrators, this data is invaluable. It allows for “early warning systems” where the software flags students whose Lexile growth has plateaued. This allows for human intervention backed by hard data, demonstrating how a simple measure of text complexity can evolve into a comprehensive tool for institutional analytics.
The Role of E-Readers and Digital Libraries
The hardware side of the tech industry, specifically e-readers like the Amazon Kindle, has also embraced Lexile measures. Many e-readers now allow users to sort their entire digital library by Lexile level. Furthermore, features like “Word Wise” on Kindle use Lexile-based data to provide automated definitions for difficult words, effectively providing a “scaffolded” reading experience.
As digital libraries continue to expand into the millions of volumes, the Lexile measure serves as the primary metadata tag for organization. Without this standardized metric, the discovery of appropriate content in a massive digital repository would be nearly impossible. By indexing content via Lexile measures, digital platforms ensure that the right book finds the right reader at the right time.

Conclusion: The Algorithmic Backbone of Modern Literacy
The Lexile measure is a prime example of how technology can bring scientific precision to a subjective field like reading. By distilling the complexities of human language into a quantifiable, algorithmic framework, it has provided the EdTech industry with a universal language for literacy.
From the backend APIs that power our favorite reading apps to the AI models that are currently redefining text analysis, the Lexile Framework remains a cornerstone of digital education. As we continue to refine our tools and expand our data sets, the Lexile measure will continue to evolve, ensuring that the bridge between human capability and the vast world of digital information remains robust, accessible, and data-driven. For any tech professional or educator working in the digital space, mastering the implications of the Lexile measure is not just an advantage—it is a necessity in the quest to enhance global literacy through technology.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.