In the modern digital era, we are drowning in information but starving for knowledge. Every day, billions of emails are sent, millions of social media posts are published, and countless research papers, medical records, and legal documents are digitized. It is estimated that approximately 80% of all corporate data is “unstructured”—meaning it is trapped in text formats that do not fit neatly into the rows and columns of a traditional database. This is where Text Data Mining (TDM) becomes the most critical tool in the technologist’s arsenal.
Text Data Mining is the process of transforming unstructured text into structured data to identify patterns, extract meaningful insights, and facilitate automated decision-making. Unlike simple web searches that look for specific keywords, TDM uses sophisticated algorithms to understand the relationships between words, the context of sentences, and the underlying intent of the writer. By leveraging Natural Language Processing (NLP) and Machine Learning (ML), TDM allows us to treat human language as a programmable data source.
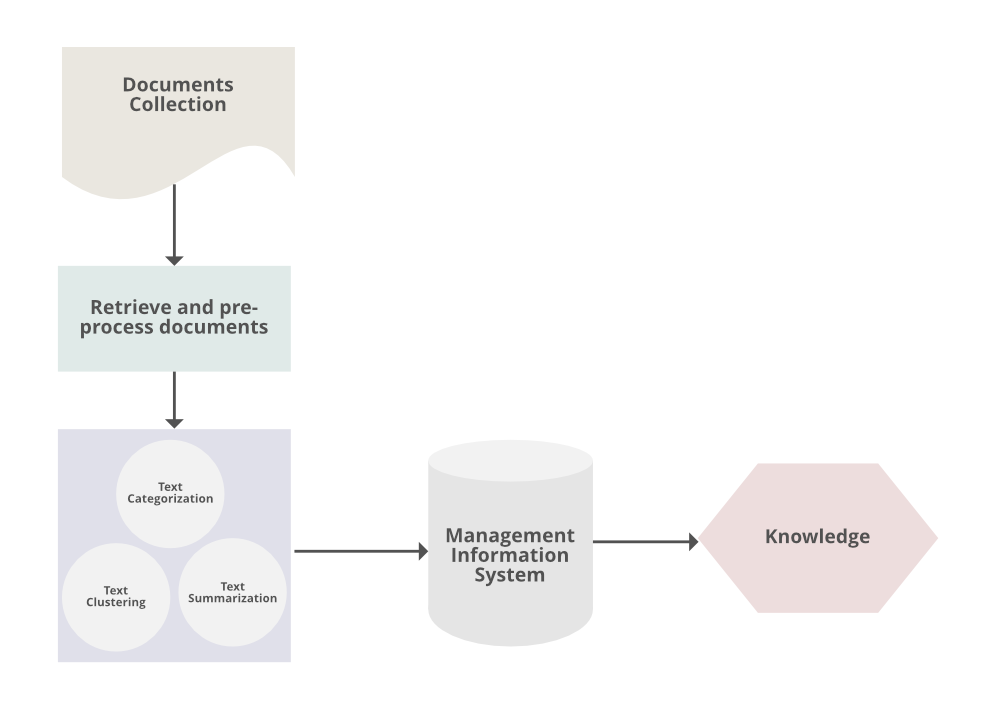
The Core Mechanics of Text Data Mining (TDM)
To understand how a machine “reads” and analyzes text, we must look at the technical architecture of the TDM pipeline. It is not a single step but a sequence of complex computational processes designed to bridge the gap between human linguistics and machine logic.
From Raw Text to Structured Data
The journey begins with data preprocessing. Raw text is inherently “noisy”; it contains typos, slang, formatting tags, and irrelevant characters. The first technical hurdle is cleaning this data through several stages:
- Tokenization: Breaking down sentences into individual units (tokens), such as words or phrases.
- Stop-word Removal: Filtering out common words like “the,” “is,” and “at” which carry little semantic value for analysis.
- Stemming and Lemmatization: Reducing words to their root form. For example, “running,” “runs,” and “ran” are all converted to the base concept of “run.”
- Part-of-Speech (POS) Tagging: Assigning grammatical categories (nouns, verbs, adjectives) to tokens to help the system understand the sentence structure.
The Role of Natural Language Processing (NLP)
While TDM focuses on the discovery of new information, NLP provides the linguistic engine that makes it possible. NLP allows the system to handle the nuances of human language, such as syntax (grammar rules) and semantics (meaning). Advanced NLP models use dependency parsing to determine how words in a sentence relate to one another, ensuring the machine understands that in the phrase “the bank of the river,” the word “bank” refers to geography, not finance.
Machine Learning and Deep Learning in TDM
Modern text mining has moved beyond rule-based systems to probabilistic models. Machine learning algorithms, particularly supervised and unsupervised learning, allow systems to “learn” patterns from large datasets. Deep learning, specifically the use of Neural Networks, has revolutionized the field. Models like Transformers use “attention mechanisms” to weigh the importance of different words in a sentence, allowing for a much deeper contextual understanding than was possible even five years ago.
Essential Techniques in the Text Mining Process
Once the text is cleaned and the NLP foundations are set, specific TDM techniques are applied depending on the desired outcome. These techniques represent the “software intelligence” that drives modern AI applications.
Information Extraction (IE)
Information Extraction is the process of identifying specific pieces of data within a large text body. The most common form is Named Entity Recognition (NER), where the software automatically identifies and categorizes entities such as names of people, organizations, locations, and dates. For a technology firm, IE can be used to automatically scan thousands of software logs to extract error codes and timestamps, turning a wall of text into a searchable incident report.
Sentiment Analysis and Opinion Mining
Sentiment analysis uses text mining to determine the emotional tone behind a body of text. By utilizing lexicons (dictionaries of “weighted” words) and machine learning classifiers, TDM can categorize text as positive, negative, or neutral. In the tech world, this is used for everything from monitoring developer sentiment on forums like Stack Overflow to evaluating user feedback on beta software releases. It goes beyond simple keywords to detect sarcasm, intensity, and nuanced dissatisfaction.
Topic Modeling and Clustering
Clustering is an unsupervised learning technique used to group similar documents together without prior labeling. Topic modeling, specifically Latent Dirichlet Allocation (LDA), identifies the “latent” topics that run through a collection of documents. For example, if a tech company has 50,000 support tickets, topic modeling can automatically group them into “Battery Issues,” “UI Bugs,” and “Connectivity Problems,” allowing engineers to prioritize their workflow based on the volume of specific clusters.
Text Summarization
As the volume of digital content grows, the ability to generate concise summaries becomes vital. There are two main technical approaches:
- Extractive Summarization: The algorithm identifies and pulls out the most important sentences from the original text.
- Abstractive Summarization: The AI understands the context and “writes” a new, shorter version of the content, much like a human would. This requires advanced Generative AI capabilities.
The Modern Tech Stack for Text Data Mining
Building a text mining infrastructure requires a specialized stack of software tools and libraries. Today’s developers and data scientists have access to an ecosystem that ranges from open-source libraries to massive cloud-based API services.
Python Libraries: NLTK, SpaCy, and Scikit-learn
Python has emerged as the industry-standard language for TDM.
- NLTK (Natural Language Toolkit): The “classic” library, excellent for academic research and basic preprocessing.
- SpaCy: Designed for production use, SpaCy is incredibly fast and offers pre-trained models for NER and POS tagging.
- Scikit-learn: While a general machine learning library, it is frequently used in TDM for vectorization (converting text into numerical vectors) and classification tasks.
Large Language Models (LLMs) and Transformers
The introduction of the Transformer architecture (the “T” in ChatGPT) changed text mining forever. Tools built on BERT (Bidirectional Encoder Representations from Transformers) or GPT (Generative Pre-trained Transformer) can perform “zero-shot” or “few-shot” learning. This means they can perform text mining tasks—like classification or extraction—with very little training data, as they already possess a vast “understanding” of human language patterns from their initial training.
Cloud-Based AI Tools
For enterprises that do not want to build their own models from scratch, cloud providers offer robust TDM services. AWS Comprehend, Google Cloud Natural Language AI, and Azure Cognitive Service for Language provide out-of-the-box capabilities for sentiment analysis, entity recognition, and syntax analysis via simple API calls. These services allow developers to integrate text mining into their apps without being experts in deep learning.
Real-World Applications and Technological Impact
Text Data Mining is the invisible engine behind many of the technologies we interact with daily. Its impact spans across various tech-centric sectors, solving problems that were previously too labor-intensive for humans.
Enhancing Digital Security and Fraud Detection
In cybersecurity, TDM is used to analyze patterns in phishing emails, malicious code comments, and dark web communications. By mining the text of incoming emails, security software can identify subtle linguistic patterns that suggest social engineering, even if the email doesn’t contain a known virus. Similarly, in fintech, TDM analyzes transaction descriptions to flag suspicious activity that might indicate money laundering or identity theft.
Revolutionizing Customer Support with Intelligent Bots
The “chatbots” of a decade ago were frustratingly limited to rigid scripts. Modern intelligent agents use TDM to understand the intent and emotion of a user’s query in real-time. By mining the company’s entire knowledge base and past ticket history, these systems can provide accurate technical solutions instantly, only escalating to a human when the text mining identifies a high level of frustration or a complex, novel problem.
Accelerating Scientific Research and Bio-Informatics
The volume of scientific literature is growing exponentially. In the pharmaceutical and biotech industries, TDM is used to mine millions of research papers to find connections between genes, diseases, and chemical compounds. This “Literature-Based Discovery” can identify potential new uses for existing drugs by finding relationships in the data that no single human researcher could ever spot across thousands of independent studies.
Challenges and the Future Landscape of TDM
Despite its power, Text Data Mining is not without its hurdles. The future of the field depends on how we address the technical and ethical limitations currently present in the technology.
Navigating Data Privacy and Ethical AI
As TDM becomes more pervasive, the privacy of the data being mined becomes a paramount concern. When algorithms mine emails or private messages to “improve user experience,” they risk infringing on personal privacy. Furthermore, there is the issue of algorithmic bias. If the text data used to train a model contains historical prejudices, the TDM outputs will reflect and potentially amplify those biases. Developers are now focusing on “Fairness in NLP” to create more equitable tools.
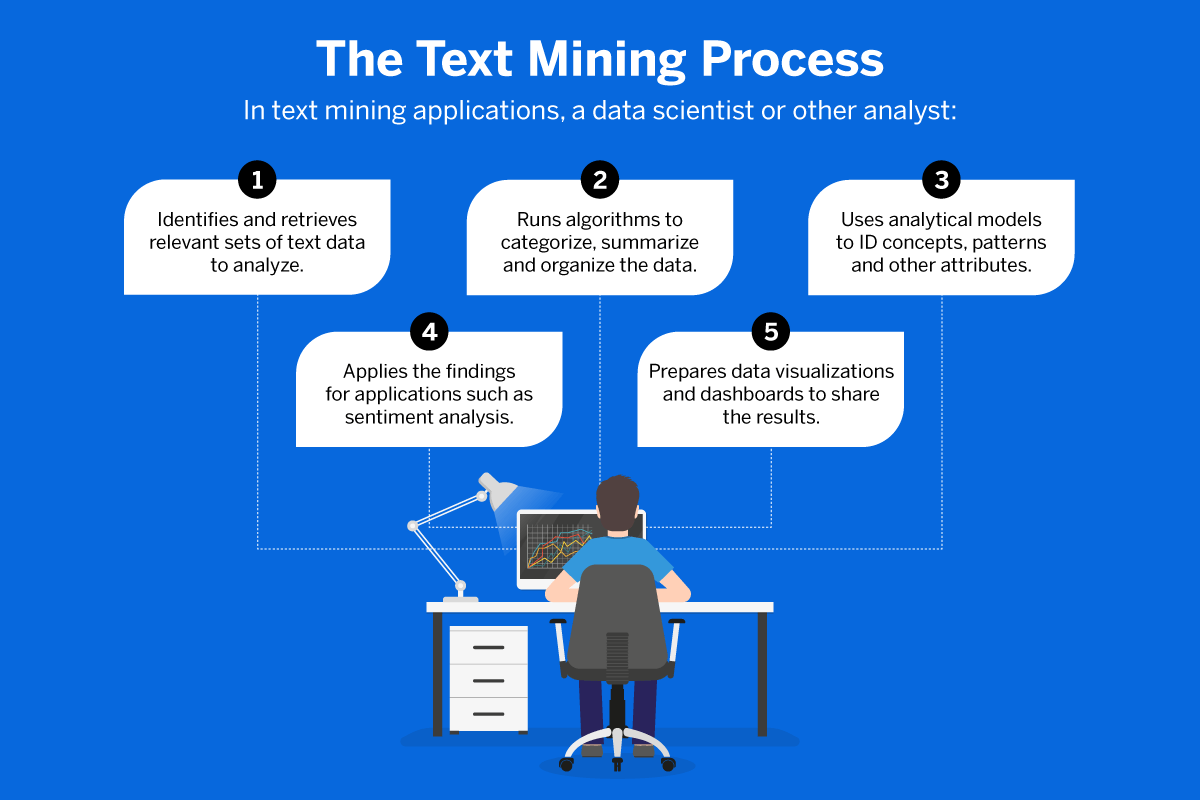
Overcoming Ambiguity and Contextual Nuance
Human language is messy. Sarcasm, irony, cultural metaphors, and evolving slang remain difficult for machines to parse perfectly. A phrase like “That’s the bomb” can be a high compliment or a security alert depending on the context. The next frontier in TDM is “Contextual Intelligence,” where models look beyond the immediate document to external world knowledge to resolve ambiguity.
As we move toward a more automated world, the ability to extract structured insights from the sea of unstructured text will be the defining factor of successful technology. Text Data Mining is no longer a niche academic pursuit; it is the fundamental bridge between human thought and machine action, turning our collective digital history into a roadmap for future innovation.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.