In the relentless pursuit of speed and efficiency, computer architects have devised ingenious methods to wring every last drop of performance from our digital brains. Among the most fundamental and impactful of these techniques is pipelining. Imagine an assembly line, but for instructions within a processor. Instead of completing one task entirely before starting the next, pipelining allows a processor to work on multiple instructions simultaneously, each at a different stage of execution. This concept, at its core, is about parallelism within a single instruction stream, dramatically boosting the throughput of computational tasks.
The world of technology is constantly evolving, with new software, AI tools, and faster gadgets emerging at an unprecedented pace. Underpinning this rapid advancement is the ever-increasing power and sophistication of the underlying hardware. Pipelining is a cornerstone of modern processor design, enabling the very technologies we rely on daily – from streaming high-definition video and running complex AI models to executing demanding software applications. Without it, the digital experiences we take for granted would be significantly slower, if not impossible.
While the direct impact of pipelining might seem confined to the realm of hardware, its ripple effects extend far beyond. The ability to process information faster has direct implications for money. More efficient computing can lead to lower energy consumption, reduced manufacturing costs, and ultimately, more affordable and powerful devices. In the context of brand, companies that leverage cutting-edge technology, often enabled by sophisticated architectures like pipelining, can build a reputation for innovation and premium products, attracting a wider customer base and solidifying their market position.
This article will delve into the intricate world of pipelining in computer architecture. We’ll explore its fundamental principles, the stages involved, the benefits it offers, and the challenges that arise in its implementation. By understanding pipelining, we gain a deeper appreciation for the remarkable engineering that powers our digital lives and how it interconnects with broader trends in technology, business, and finance.
The Fundamental Concept: Breaking Down the Instruction
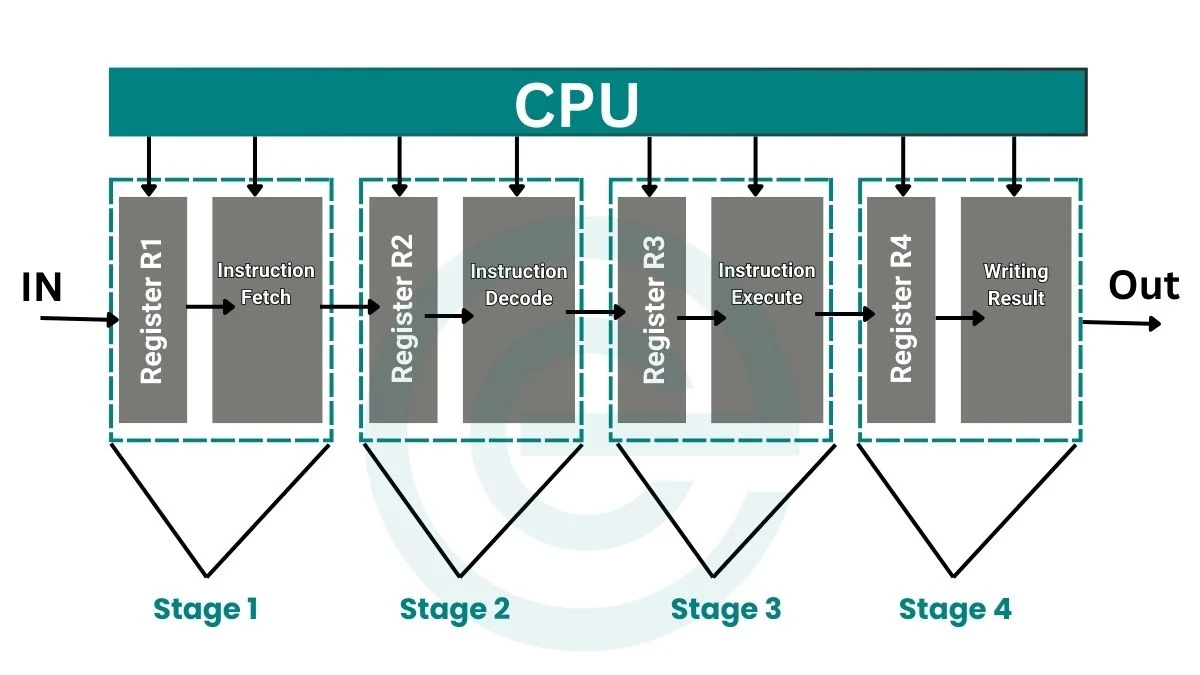
At its heart, pipelining is a technique used in the design of a central processing unit (CPU) to increase instruction-level parallelism. Instead of executing instructions sequentially – fetching an instruction, decoding it, executing it, writing back the result, and then moving to the next – pipelining breaks down the execution of a single instruction into a series of smaller, independent steps. Each of these steps is then assigned to a dedicated hardware stage within the processor.
Think of it like a car assembly line. Instead of one person building an entire car from start to finish, different teams handle specific tasks: one installs the engine, another the chassis, another the interior, and so on. Each team works concurrently on different cars, leading to a much higher output than if a single worker had to perform every step. In a pipelined processor, the instruction itself is the “car” and the stages are the “teams” performing specific operations.
Instruction Execution Stages
The classic model of instruction execution can be broken down into several distinct stages, often simplified into the following five:
- Instruction Fetch (IF): This stage retrieves the next instruction from memory, based on the program counter (PC). The PC holds the memory address of the next instruction to be executed.
- Instruction Decode (ID): Once fetched, the instruction is decoded to determine what operation needs to be performed and which operands (data) are required. This stage also typically involves fetching the necessary data from registers.
- Execute (EX): This is where the actual computation takes place. For arithmetic or logical instructions, the Arithmetic Logic Unit (ALU) performs the required operation. For memory access instructions, this stage might calculate the effective memory address.
- Memory Access (MEM): If the instruction requires reading from or writing to memory (like a load or store instruction), this stage handles that operation. Other instructions might bypass this stage.
- Write-Back (WB): Finally, the result of the execution is written back to a register. This could be the result of an ALU operation or data loaded from memory.
The Power of Parallelism
Without pipelining, a processor would complete all five stages for one instruction before starting the first stage of the next. This means that for each clock cycle, only a fraction of the processor’s circuitry is being utilized. If an instruction takes 5 clock cycles to complete, and each stage takes 1 clock cycle, the processor would essentially be idle for 4 cycles while waiting for the current instruction to finish.
Pipelining revolutionizes this by allowing different instructions to be in different stages of execution simultaneously. In a perfectly ideal scenario with a 5-stage pipeline and no dependencies, the processor could complete one instruction every clock cycle after the pipeline is filled. This is a massive increase in throughput. While each individual instruction still takes the same amount of time to complete from start to finish, the rate at which new instructions are completed is significantly higher.
Benefits and Advantages of Pipelining
The adoption of pipelining in computer architecture has yielded significant advantages, impacting not only the speed of computation but also influencing broader technological and economic landscapes.
Enhanced Throughput and Performance
The most immediate and profound benefit of pipelining is the dramatic increase in instruction throughput. By overlapping the execution of instructions, the processor can complete more instructions per unit of time. This directly translates to faster program execution, enabling more complex software, richer user experiences, and the processing of vast datasets in shorter durations. For AI tools, this means faster model training and inference, and for apps, it translates to snappier performance and responsiveness. This performance boost is a critical driver for innovation across the entire tech industry.

Improved Resource Utilization
In a non-pipelined processor, functional units (like the ALU, memory access units, etc.) are idle for much of the time. Pipelining ensures that these units are kept busy, working on different instructions concurrently. This leads to better utilization of the processor’s hardware resources, making the overall design more efficient. This efficiency can trickle down to reduced power consumption, a key consideration for both mobile devices and large data centers, impacting the money spent on energy.
Foundation for Higher Clock Speeds
While pipelining doesn’t inherently increase the clock speed of a processor, it enables higher clock speeds. Because each stage in a pipeline is designed to perform a simpler, shorter operation, it can be completed in less time. This allows architects to increase the clock frequency of the processor without encountering timing issues, as the time required for each stage becomes smaller. Higher clock speeds, combined with pipelining, lead to an exponential increase in overall performance.
Impact on Technology and Brand Reputation
The performance gains offered by pipelining are fundamental to the development of cutting-edge technologies. The ability to process data rapidly is essential for advancements in areas like virtual reality, real-time analytics, and complex simulations. Companies that can deliver products powered by these advanced technologies, often a direct result of sophisticated processor designs that incorporate pipelining, can build a strong brand identity associated with innovation, speed, and superior performance. This can translate into market leadership and increased revenue.
Challenges and Complications in Pipelining
Despite its immense benefits, pipelining is not without its complexities. Several challenges must be addressed by computer architects to ensure the smooth and efficient operation of a pipelined processor.
Pipeline Hazards
Hazards are situations in which the next instruction in the instruction stream is delayed because the current instruction has not yet completed. These breaks in the smooth flow of instructions are known as pipeline hazards. There are three main types of hazards:
- Structural Hazards: These occur when two or more instructions require the same hardware resource at the same time. For example, if a processor had only one memory port, and two instructions (one fetching an instruction, another accessing data) needed to use it simultaneously, a structural hazard would occur. Modern designs often mitigate this by having separate instruction and data caches and memory ports.
- Data Hazards: These arise when an instruction depends on the result of a previous instruction that has not yet been written back. For instance, if instruction B needs to use the result of instruction A, but instruction A is still in the pipeline (e.g., in the EX or MEM stage), instruction B will have to wait. This is often addressed through techniques like forwarding (or bypassing), where the result of an instruction is made available to subsequent instructions before it’s written back to the register file.
- Control Hazards: These occur due to branches and jumps in the program. When the processor fetches an instruction, it doesn’t immediately know whether the branch will be taken or not. If the processor guesses incorrectly, it might fetch and begin processing instructions that will not actually be executed, leading to wasted work. This is tackled using techniques like branch prediction, where the processor attempts to guess the outcome of a branch, and delayed branches, where the instruction immediately following a branch is always executed regardless of whether the branch is taken.
Handling Exceptions and Interrupts
Managing exceptions (like division by zero) and interrupts (external events that require immediate attention) in a pipelined processor is more complex than in a non-pipelined one. When an exception or interrupt occurs, the processor needs to determine which instructions have been partially executed and ensure that the program state is correctly restored before handling the event. This often involves flushing the pipeline of instructions that have started but not yet committed their results.
Complexity of Design and Verification
Implementing a pipelined architecture significantly increases the complexity of processor design. Architects must carefully design each stage, ensure correct data flow, and implement sophisticated hazard detection and resolution mechanisms. The verification of these complex designs is also a monumental task, requiring extensive simulation and testing to ensure correctness across a wide range of programs and scenarios.

The Interplay with Software and Performance Tuning
The performance of a pipelined processor is not solely determined by its hardware. The way software is written can have a profound impact. Programmers and compilers need to be aware of pipelining to optimize code. For instance, reordering instructions to minimize data hazards or avoiding predictable branching patterns can significantly improve program execution speed. This highlights the symbiotic relationship between hardware and software, where understanding architectural features like pipelining is crucial for achieving peak performance, influencing the development of efficient software and apps.
In conclusion, pipelining is a fundamental and powerful technique that underpins the performance of modern computer architectures. By breaking down instruction execution into stages and overlapping their execution, processors can achieve significantly higher throughput. While challenges like pipeline hazards and control flow management exist, sophisticated architectural solutions have been developed to overcome them. The continuous advancement in pipelining techniques, alongside other architectural innovations, ensures that our digital world continues to evolve at an ever-accelerating pace, driving progress in technology, shaping consumer brands, and influencing global money markets through increased productivity and innovation.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.