In the rapidly evolving landscape of natural language processing (NLP) and digital communication, the ability to quantify the complexity of language has become a cornerstone of effective technology. Among the various algorithmic approaches to text analysis, the Lix index—short for Läsbarhetsindex—stands out as one of the most reliable and computationally simple metrics for determining readability. Originally developed in Sweden by Carl-Hugo Björnsson, the Lix index has transcended its linguistic origins to become a vital tool in the tech sector, specifically within software development, AI content generation, and user experience (UX) design.

When we discuss “Lix in numbers,” we are referring to a quantitative value that represents the structural difficulty of a text. For developers and data scientists, this number is more than just a score; it is a data point that informs how algorithms process information and how software interfaces communicate with users.
Decoding the Lix Formula: How the Numbers Work
At its core, the Lix index is a mathematical representation of linguistic density. Unlike more subjective measures of “good writing,” Lix relies exclusively on objective data points: word counts, sentence counts, and word length. This makes it an ideal candidate for automation within software environments.
The Mathematical Equation
The beauty of the Lix index lies in its simplicity, which allows it to be easily scripted into any programming language, from Python to JavaScript. The formula is expressed as:
Lix = (A / B) + (C × 100 / A)
Where:
- A is the total number of words in the text.
- B is the total number of sentences.
- C is the number of “long words” (defined as words with more than six characters).
The first part of the equation (A/B) calculates the average sentence length, while the second part calculates the percentage of long words. By combining these two factors, the Lix index provides a holistic view of how taxing a piece of content is for the human brain—and an AI model—to process.
Defining “Long Words” and Sentence Length
In the context of data analysis, the definition of a “long word” as anything over six characters is a specific threshold that distinguishes Lix from other metrics like the Flesch-Kincaid Grade Level, which often focuses on syllable counts. From a technical implementation standpoint, counting characters is significantly more efficient and less prone to error than counting syllables, which requires complex phonetic dictionaries or sophisticated NLP libraries. This makes Lix a “lighter” algorithm for real-time applications, such as live readability checkers in content management systems (CMS).
Interpreting the Numerical Output
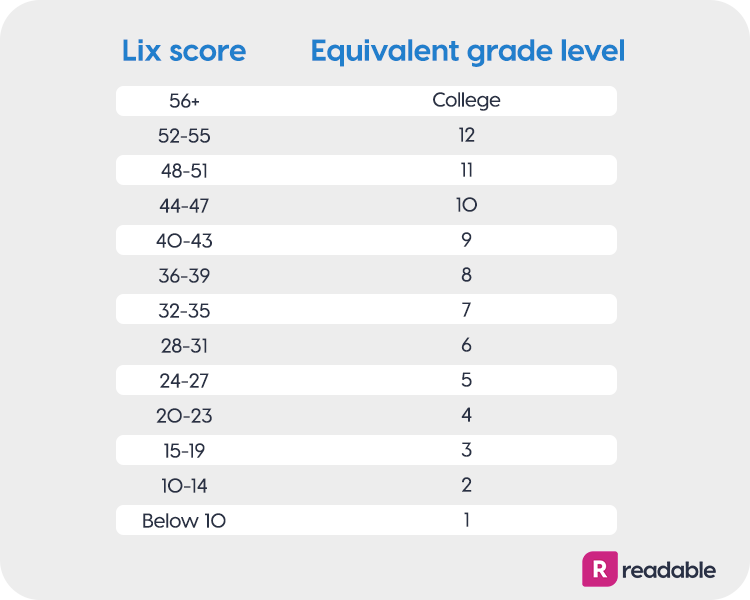
The resulting Lix score typically ranges from 20 to 60+, though higher numbers are possible.
- 20-30: Very easy (children’s literature).
- 30-40: Easy (popular fiction or standard journalism).
- 40-50: Medium difficulty (official documents and technical reports).
- 50-60: Difficult (academic journals or specialized technical whitepapers).
- 60+: Very difficult (complex legal or philosophical texts).
By understanding these ranges, software architects can set “guardrails” for content, ensuring that documentation or interface copy remains within a specific numerical bracket to maximize accessibility.
Why Lix Matters in the Era of AI and Big Data
As generative AI models like GPT-4 and Claude become integrated into corporate workflows, the need for quantitative benchmarks has surged. Lix provides a standardized metric that allows machines to evaluate the “human-friendliness” of the text they generate.
Bridging the Gap Between Human and Machine Readability
In the field of Machine Learning (ML), readability scores are often used as features in text classification tasks. If a developer is training a model to generate technical support documentation, they can use Lix as a loss function or a validation metric. By aiming for a Lix score between 40 and 45, the developer ensures that the AI does not produce overly simplistic “hallucinations” or excessively dense “technobabble.”
Lix vs. Flesch-Kincaid: Choosing the Right Algorithmic Model
While Flesch-Kincaid is perhaps more well-known in the United States, Lix is often preferred in international tech environments. Because Lix does not rely on syllables—which vary wildly between languages—it is more “language-agnostic.” For a global SaaS company that needs to measure the readability of its documentation across English, Swedish, German, and French, Lix offers a more consistent numerical baseline. This consistency is crucial for data integrity when managing multi-language databases.
Enhancing Search Engine Algorithms
Search engines are increasingly prioritizing “User Intent” and “Content Quality.” Modern SEO software integrates Lix scores to help developers and content strategists understand if their pages are too complex for the average searcher. By keeping a page’s Lix number in the “Easy” to “Medium” range, tech companies can reduce bounce rates and improve the dwell time—metrics that search engine algorithms use to rank technical tutorials and blog posts.
Implementing Lix in Modern Software Development
For developers, the Lix index is not just a concept; it is a feature to be implemented. Whether it is a browser extension that evaluates news articles or a dashboard for corporate communications, the integration of Lix is a standard procedure in text-analytics software.
Integrating Readability APIs into CMS Platforms
Many modern headless CMS platforms now offer “Content Intelligence” modules. By integrating a Lix-based API, these platforms can provide real-time feedback to writers. As a user types, the backend processes the character counts and sentence delimiters, updating the Lix score in the sidebar. This immediate feedback loop is essential for maintaining consistency in large-scale technical deployments where dozens of contributors are writing documentation simultaneously.
Using Lix for Natural Language Processing (NLP) Training
In the realm of data science, Lix is often used during the data cleaning and preprocessing phase. When scraping large datasets from the web to train a language model, developers may use Lix to filter out “noise.” For example, a script might automatically discard text with a Lix score above 70 (likely unparseable legal jargon) or below 15 (likely low-quality automated spam). This ensures that the training data remains within a high-quality, readable spectrum.
Practical Applications: Optimizing Technical Documentation and UX
The ultimate goal of using Lix in numbers is to improve the interaction between humans and technology. In the tech industry, where complexity is the default, Lix acts as a necessary check on “expert blind spot.”
Scaling Global Tech Support via Simplified Language
Tech support for hardware and software products must be accessible to users of all education levels. By mandating a specific Lix score for all “Knowledge Base” articles, companies can ensure that their instructions are clear. For instance, a developer writing a tutorial on “How to Configure an API Gateway” might accidentally produce a Lix score of 55. By revising the text to shorten sentences and use more common terms, they can bring that number down to 42, significantly reducing the number of support tickets generated by confused users.
Enhancing UX Through Quantitative Clarity
User Experience (UX) writing is the art of guiding a user through a digital product. Microcopy—the small bits of text on buttons, tooltips, and error messages—must be processed instantly. While Lix is typically used for longer passages, the principles of the index inform UX frameworks. Tech companies now use “Readability Audits” powered by Lix to scan their entire app interface, ensuring that the cumulative complexity of the platform does not lead to “cognitive load,” which can drive users away from the product.
The Future of Readability Metrics in Generative AI
As we look toward the future, the role of Lix in the tech sector will likely expand from a simple descriptive metric to a prescriptive one. We are entering an era where AI doesn’t just write; it optimizes its own output based on numerical constraints.
Moving Beyond Basic Counts to Contextual Understanding
While Lix is efficient because it avoids phonetic complexity, the next generation of readability tools will likely combine Lix scores with semantic analysis. Developers are already experimenting with “Semantic Lix,” where the 100/A factor in the formula is weighted by the rarity of the words used, not just their length. This would allow a software tool to distinguish between a “long” common word like information and a “long” technical word like anisotropy.

Automated Content Governance
In large enterprises, “Content Governance” is becoming an automated process. Software suites are being developed that prevent a technical manual from being “merged” or “published” to a live site if its Lix score exceeds a pre-defined threshold. This is essentially “Unit Testing” for language. Just as a developer cannot push code that fails a build test, a technical writer in the future may not be able to push content that fails a readability test.
In conclusion, “Lix in numbers” is a vital bridge between the qualitative world of human language and the quantitative world of technology. By reducing the complexity of text to a manageable numerical value, the Lix index allows software to measure, analyze, and optimize communication. Whether it is used to train the next generation of AI, streamline global technical support, or improve the interface of a mobile app, Lix remains an indispensable tool for anyone looking to master the intersection of data and discourse. As technology continues to grow more complex, the numbers provided by the Lix index will only become more essential in ensuring that our digital world remains readable and accessible to everyone.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.