In the current era of digital transformation, data is often likened to the “new oil.” However, raw data, much like crude oil, is of limited value until it is refined, processed, and organized. As organizations grapple with an unprecedented influx of information—ranging from customer logs and financial transactions to IoT sensor feeds—the ability to make sense of this “data deluge” has become a competitive necessity. At the heart of this organizational capability lies data categorization.
Data categorization is the systematic process of labeling and organizing data into distinct groups based on common characteristics, properties, or sensitivity levels. In the realm of technology, it is the foundational step that enables efficient searchability, robust security, and the effective training of artificial intelligence models. Without a structured approach to categorization, a company’s data lake quickly turns into a data swamp, where valuable insights are buried under layers of digital noise.
1. The Core Mechanisms of Data Categorization in the Tech Ecosystem
To understand data categorization, one must first look at the mechanisms that drive it. In a professional tech environment, categorization is not merely a matter of moving files into folders; it is a sophisticated architectural process involving metadata, taxonomies, and automated workflows.
Manual vs. Automated Categorization Systems
Traditionally, data was categorized manually by database administrators or users. While highly accurate for small datasets, manual categorization is impossible to scale in the age of Big Data. Modern technology stacks now rely on automated categorization systems. These systems use predefined rules or heuristic patterns to scan incoming data and assign it to the appropriate bucket. For instance, a system might automatically categorize any string of numbers following a “###-##-####” format as a Social Security Number, triggering specific security protocols.
The Role of Metadata and Taxonomies
Metadata—often described as “data about data”—is the backbone of categorization. It provides the context necessary for software to understand what a piece of information represents. A robust tech infrastructure utilizes a standardized taxonomy (a hierarchical classification scheme) to ensure consistency. For example, in a cloud storage environment, metadata tags might include the author, the date of creation, the department it belongs to, and its “confidentiality” level. This structured approach allows for complex queries and automated lifecycle management.
Structured vs. Unstructured Data Challenges
One of the greatest hurdles in modern tech is categorizing unstructured data, such as emails, PDF documents, and video files. While structured data (like SQL databases) is inherently organized, unstructured data accounts for approximately 80% of all corporate information. Technology leaders must deploy specialized tools, such as Optical Character Recognition (OCR) and pattern recognition, to extract meaning from these formats and bring them into the categorized fold.
2. Enhancing Cybersecurity and Compliance Through Data Classification
In the niche of digital security, data categorization is not just an organizational preference; it is a defensive requirement. Categorizing data based on its sensitivity is the first step in building a “Zero Trust” security architecture.
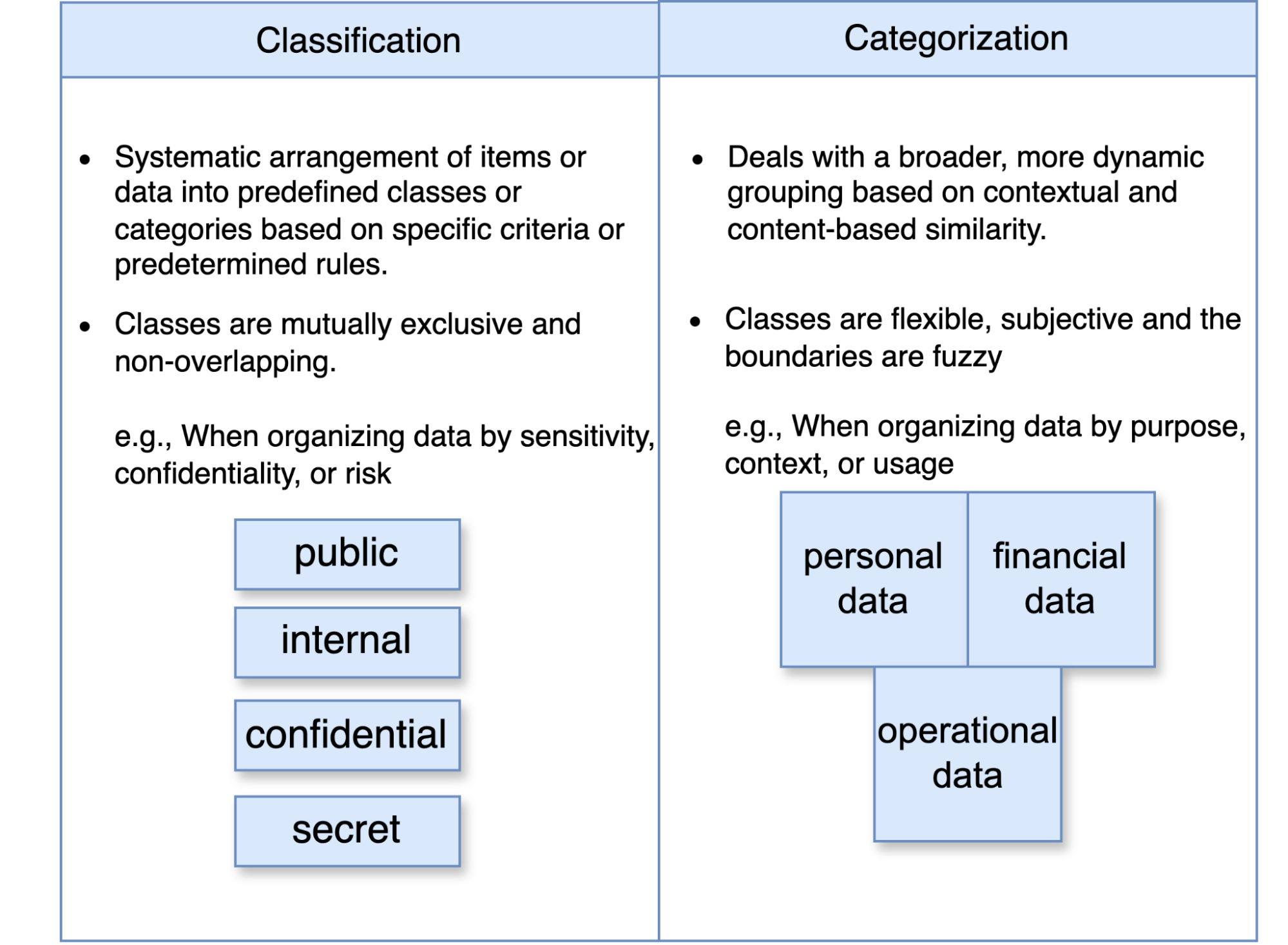
Protecting Sensitive Information via Classification Levels
Most technology frameworks utilize a tiered classification system to manage access and encryption. Typical categories include:
- Public: Information that can be freely shared without risk (e.g., marketing brochures).
- Internal: Data meant for employee eyes only but not critically sensitive (e.g., company memos).
- Confidential/Private: Data that could harm the company or individuals if leaked (e.g., employee records, customer PII).
- Restricted/Secret: Highly sensitive data that requires the highest level of encryption (e.g., trade secrets, intellectual property).
By categorizing data this way, security software like Data Loss Prevention (DLP) tools can monitor “Restricted” data more aggressively, blocking it from being uploaded to unauthorized cloud drives or sent via unencrypted email.
Meeting Regulatory Standards (GDPR, CCPA, and HIPAA)
The global regulatory landscape has become increasingly stringent regarding how technology handles personal data. The General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) require organizations to know exactly where “Personal Data” is stored and how it is processed. Categorization allows tech teams to automate compliance. When data is correctly categorized as “PII” (Personally Identifiable Information), automated scripts can ensure it is deleted after a certain period or obfuscated to protect user privacy, thereby avoiding multi-million dollar fines.

3. Leveraging AI and Machine Learning for Advanced Data Organization
The most significant trend in data categorization today is the integration of Artificial Intelligence (AI) and Machine Learning (ML). As datasets grow to petabyte scales, human-defined rules often fall short.
Supervised vs. Unsupervised Learning Models
AI-driven categorization typically utilizes two types of learning. In Supervised Learning, a model is trained on a “labeled” dataset—one where the categories are already known. For example, a model might be shown 10,000 invoices and 10,000 resumes until it learns to distinguish between the two automatically.
In Unsupervised Learning, the AI looks for patterns in unlabeled data. It might notice that a group of documents all contain similar technical jargon and group them together as “Engineering Specifications” without being explicitly told to do so. This is particularly useful for discovering hidden relationships within massive datasets.
Natural Language Processing (NLP) for Unstructured Content
NLP is a subfield of AI that allows machines to understand and categorize human language. Tech companies use NLP to scan millions of customer support tickets or social media mentions, categorizing them by “sentiment” (positive, negative, neutral) or “intent” (billing issue, technical bug, feature request). This level of categorization allows companies to respond to critical technical issues in real-time, prioritizing tickets that the AI categorizes as “urgent.”
The Feedback Loop and Continuous Improvement
Modern AI categorization tools are not “set and forget.” They operate on a continuous feedback loop. When a human corrects a miscategorized file, the system learns from that error, refining its algorithms to increase accuracy over time. This iterative process is essential for maintaining the integrity of data in dynamic tech environments where the types of data being generated are constantly evolving.
4. Best Practices for Implementing a Robust Data Categorization Framework
Implementing a categorization strategy is a complex software and cultural undertaking. For tech leads and architects, success depends on a clear roadmap and the right tooling.
Defining a Scalable and Logical Taxonomy
The first step is creating a taxonomy that is both comprehensive and flexible. A common mistake is creating too many categories, which leads to “categorization fatigue” and system slowdowns. A lean, scalable taxonomy focuses on the most critical attributes: Use Case, Sensitivity, and Retention. This framework should be documented in a central “Data Dictionary” that all developers and data scientists can reference.
Integration with Data Fabric and Mesh Architectures
In modern distributed computing, data is often spread across multi-cloud and on-premise environments. A “Data Fabric” approach uses AI to provide a unified layer of categorization across all these silos. By integrating categorization into the very fabric of the network, organizations ensure that data is organized the moment it is created, regardless of whether it resides in AWS, Azure, or a local server.
Regular Audits and Lifecycle Management
Data is not static; its value and sensitivity change over time. A piece of data categorized as “Confidential” during a product launch might become “Public” a year later. Tech teams must implement automated Data Lifecycle Management (DLM) policies. These policies use categorization tags to determine when data should be moved to cheaper “cold storage,” when it should be archived, and when it must be permanently purged to reduce the “digital footprint” and associated security risks.

The Future of Data Categorization: Toward “Intelligent Data”
As we look toward the future, data categorization is moving away from being a reactive process toward being a proactive, “intelligent” feature of the data itself. We are seeing the rise of Self-Describing Data, where categorization is embedded into the data packet at the point of origin, such as an IoT sensor.
Furthermore, with the advent of Edge Computing, categorization will increasingly happen at the “edge” of the network—on smartphones, cameras, and industrial machinery—rather than in a centralized data center. This reduces latency and ensures that only relevant, categorized information is sent to the cloud, saving bandwidth and processing power.
In conclusion, data categorization is the unsung hero of the technology world. It is the invisible scaffolding that supports our most advanced AI, the shield that guards our most sensitive digital assets, and the map that allows us to navigate the vast oceans of information we create every day. For any organization looking to thrive in the digital age, mastering the art and science of data categorization is no longer optional—it is the foundation of technological excellence.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.