In the rapidly evolving landscape of software development, the complexity of modern applications—from global financial systems to sophisticated AI-driven platforms—requires a high level of structural organization. At the heart of this organization lies a fundamental concept that bridges the gap between human logic and machine execution: the Abstract Data Type (ADT). For software architects, developers, and tech enthusiasts, understanding ADTs is not merely an academic exercise; it is a prerequisite for building scalable, maintainable, and efficient digital solutions.
An Abstract Data Type is a mathematical model for data types where the type is defined by its behavior (semantics) from the point of view of a user of the data, specifically in terms of possible values, possible operations on data of this type, and the behavior of these operations. This article explores the depth of ADTs, their practical applications, and why they remain the cornerstone of high-level programming.
Decoding the Abstract Data Type: Concept and Philosophy
To understand an Abstract Data Type, one must first grasp the concept of “abstraction.” In technology, abstraction is the process of removing physical, spatial, or temporal details or attributes in the study of objects or systems to focus attention on details of greater importance. It is the art of simplifying the complex.
What is Abstraction in Programming?
In programming, abstraction allows a developer to interact with a complex system through a simplified interface. Think of a smartphone: to send a message, you interact with an application interface. You do not need to understand the voltage changes in the processor or the specific radio frequency protocols being used. The interface “abstracts” the underlying hardware and software complexities. Similarly, an ADT provides a conceptual model of how data should behave without dictating how it is stored in the computer’s memory.
Defining the “What” vs. the “How”
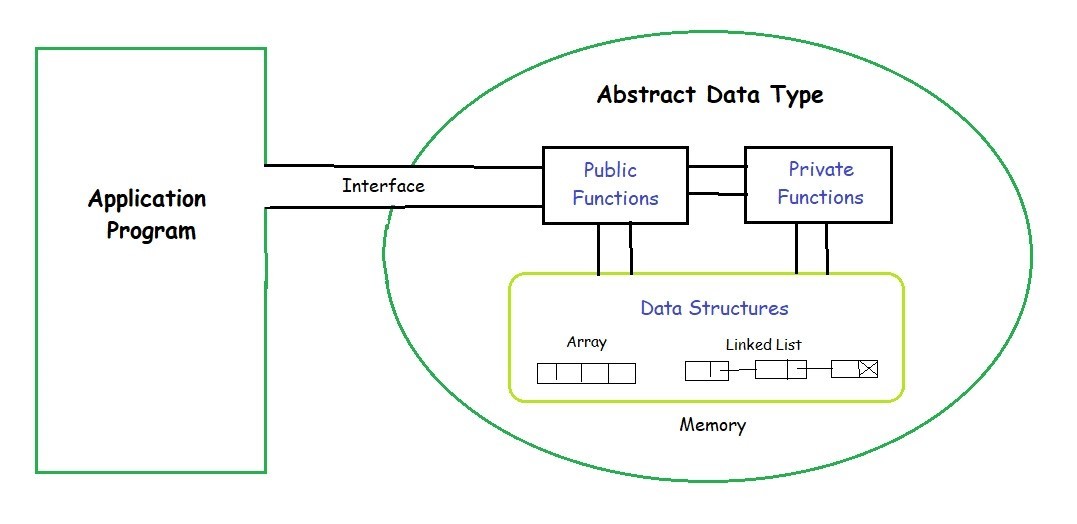
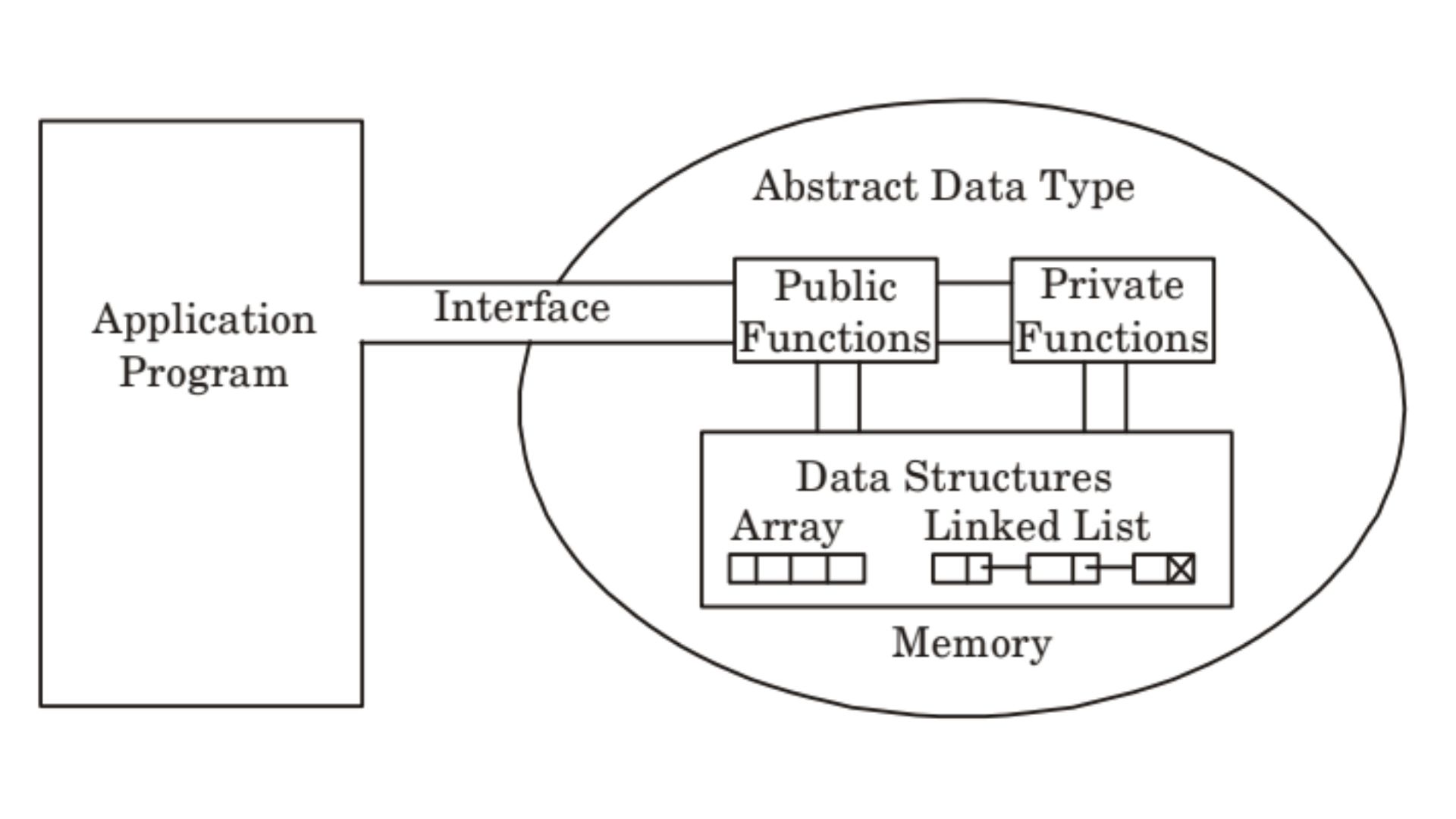
The defining characteristic of an ADT is the separation of the interface from the implementation. An ADT focuses entirely on the “what”—what operations can be performed and what results are expected. It does not concern itself with the “how”—the specific algorithms or data structures used to realize those operations. This distinction is crucial for modularity. By defining a clear contract (the ADT), a developer can change the internal implementation of a component at any time without affecting the parts of the program that use it.
The Logical View vs. The Implementation View
When a programmer designs an ADT, they create a logical view of the data. For instance, a “List” ADT might include operations like insert, delete, get, and size. This logical view remains consistent across different programming environments. The implementation view, however, is where the “Tech” happens. A List could be implemented using a contiguous block of memory (an array) or a series of linked nodes (a linked list). The user of the ADT sees the same behavior regardless of which implementation is chosen under the hood.
Essential Examples of Abstract Data Types in Action
While the theory of ADTs is abstract, their application is incredibly practical. Most high-level programming languages provide built-in libraries that are essentially implementations of standard ADTs. Understanding these common types is essential for efficient problem-solving.
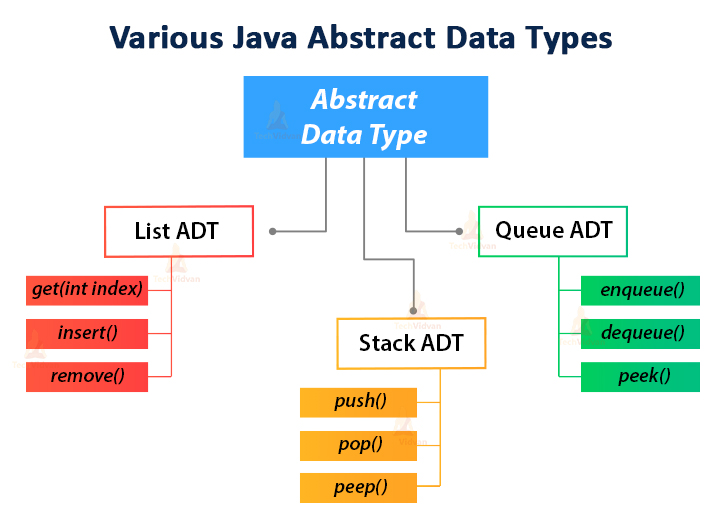
The Stack: Last-In, First-Out (LIFO)
The Stack is one of the most intuitive ADTs. It follows the LIFO principle, much like a stack of physical trays in a cafeteria. The primary operations are push (adding an item to the top) and pop (removing the item from the top).
In modern tech, stacks are used everywhere:
- Undo Mechanisms: Every time you press
Ctrl+Zin a text editor, the software pops the last action from a stack. - Function Calls: When a computer executes a program, it uses a “Call Stack” to keep track of active subroutines.
The Queue: First-In, First-Out (FIFO)
The Queue ADT models a real-world line. The first element added is the first one to be removed. Standard operations include enqueue (add to back) and dequeue (remove from front).
Queues are vital in systems architecture:
- Task Scheduling: Operating systems use queues to manage processes waiting for CPU time.
- Message Brokers: In distributed systems, tools like RabbitMQ or Kafka use queues to manage data flow between microservices, ensuring that requests are processed in the order they were received.
Lists, Sets, and Maps: Managing Collections
Beyond simple linear structures, ADTs like Sets and Maps (or Dictionaries) provide more complex behaviors.
- Sets: An ADT that stores unique elements with no specific order. Operations include
add,remove, andcontains. - Maps: Perhaps the most powerful ADT in modern software, a Map stores key-value pairs. This allows for near-instant retrieval of data based on a unique identifier, making it the backbone of database indexing and session management in web apps.
ADT vs. Data Structures: Clarifying the Confusion
The terms “Abstract Data Type” and “Data Structure” are often used interchangeably in casual conversation, but in the realm of computer science and professional software engineering, they refer to different layers of the development process.
The Conceptual Blueprint vs. The Physical Construction
An ADT is the blueprint; a data structure is the physical construction. If you were building a house, the ADT would be the architectural drawing specifying that there must be a kitchen, a bedroom, and a bathroom. It doesn’t tell you whether the walls are made of brick, wood, or concrete. The Data Structure is the actual material and the way those materials are assembled to meet the requirements of the blueprint.
Why Implementation Hiding Matters for Security and Performance
By using ADTs, tech organizations can enforce a principle known as “information hiding” or “encapsulation.” This is a major pillar of digital security and system stability. When the internal workings of a data structure are hidden behind an ADT interface, it prevents external parts of the code from accidentally—or maliciously—corrupting the data. Furthermore, it allows engineers to optimize performance. If a Stack implemented with an array becomes too slow as data grows, the engineer can swap it for a linked-list implementation without changing a single line of code in the higher-level application.
The Strategic Importance of ADTs in Software Development
In the context of professional software engineering, ADTs are not just a way to organize code; they are a strategic tool for managing large-scale projects and technical debt.
Promoting Modularity and Reusability
Modular programming is the practice of breaking a large system into smaller, independent pieces. ADTs are the ultimate units of modularity. Because they define a clear interface, they can be reused across different projects. A well-designed “User Account” ADT created for a mobile app can be ported to a web platform or a desktop application with minimal friction, provided the interface remains the same.
Simplifying Debugging and Maintenance
When a software system fails, developers must isolate the cause. ADTs make this significantly easier. Because the behavior of an ADT is strictly defined, if a “Queue” is returning the wrong item, the developer knows exactly where to look: the implementation of that specific ADT. This prevents bugs from “leaking” across different parts of the system, which is a common nightmare in poorly structured legacy code.
Enhancing Collaboration in Large-Scale Tech Teams
In large tech firms like Google or Amazon, hundreds of developers may work on a single product. ADTs serve as a “contract” between different teams. Team A can build the user interface using a “Database ADT” provided by Team B. Team A doesn’t need to know how Team B is storing the data—whether it’s in a SQL database, a NoSQL cloud bucket, or a local cache. They only need to know which operations (functions) are available. This allows teams to work in parallel, drastically increasing the speed of the development lifecycle.
ADTs in the Age of AI and Modern Tooling
As we move further into the era of Artificial Intelligence and cloud-native computing, the role of Abstract Data Types is evolving, becoming even more essential for managing high-dimensional data.
High-Level Abstractions in AI Frameworks
Machine Learning frameworks like TensorFlow and PyTorch rely heavily on complex ADTs called “Tensors.” A Tensor is essentially a multi-dimensional array with a specific set of mathematical operations (like matrix multiplication or convolution) defined for it. By treating Tensors as ADTs, these frameworks allow data scientists to build complex neural networks without needing to manually manage the memory allocation on a GPU or TPU. The “what” (the mathematical model) is separated from the “how” (the hardware acceleration).
Cloud-Native Architecture and Data Modeling
In cloud computing, we often deal with “Distributed ADTs.” These are data structures that live across multiple servers in a data center. For example, a “Distributed Hash Map” allows a developer to store and retrieve data globally. The developer interacts with it as if it were a local map, but the underlying implementation handles data replication, consistency, and network latency. This is the pinnacle of abstraction, allowing modern apps to scale to millions of users seamlessly.
In conclusion, the Abstract Data Type is the invisible framework upon which the entire tech industry is built. By focusing on behavior rather than implementation, ADTs enable the creation of software that is robust, flexible, and capable of evolving alongside technological trends. Whether you are a student learning your first programming language or a senior engineer architecting a global platform, the principles of the ADT remain your most powerful tool for turning complex logic into functional, high-performance reality.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.