In the intricate world of technology, where precision, reliability, and accuracy are paramount, the concept of “error” is a constant companion. While often seen as a problem to be eradicated, understanding different types of errors is crucial for building robust and trustworthy systems. Among these, the random error stands out as a fundamental, often unavoidable, aspect of data, measurement, and processing in virtually every technological domain. Unlike its systematic counterpart, which introduces a consistent bias, random error manifests as unpredictable fluctuations that can obscure true values, compromise system performance, and challenge the integrity of insights derived from data.

This article delves into the nature of random errors, exploring their origins, impact across various technology sectors, and the sophisticated strategies engineers, data scientists, and developers employ to identify, quantify, and mitigate their influence. From the subtle noise in a sensor reading to the unpredictable timing variations in a complex software system, random errors are an intrinsic part of the digital landscape, demanding a deep understanding to navigate effectively.
The Nature of Random Error: Unpredictability and Distribution
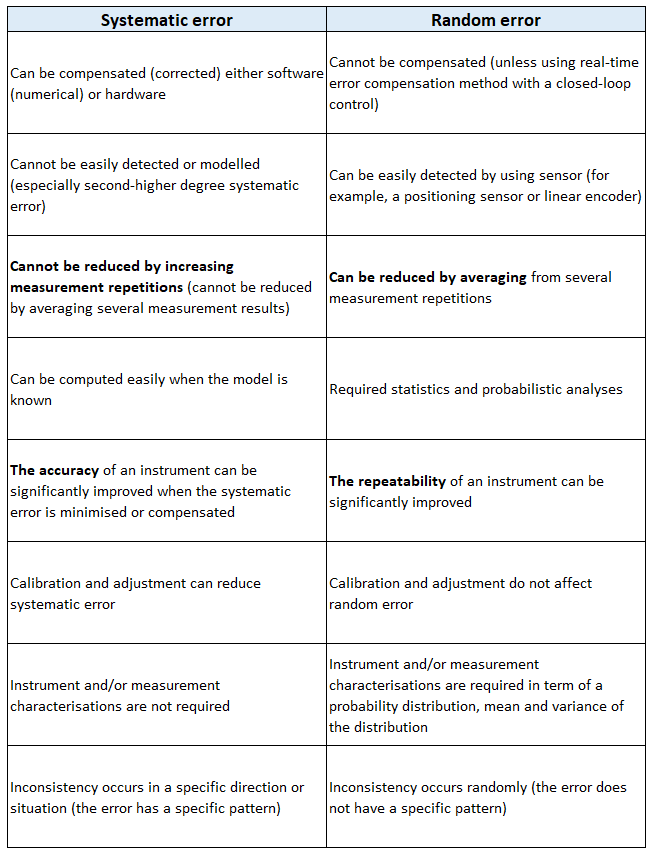
At its core, a random error represents an unpredictable deviation from the true or expected value of a measurement or process. It is characterized by its variability in both magnitude and direction, meaning that consecutive observations of the same phenomenon, under seemingly identical conditions, will yield slightly different results. This inherent unpredictability is what sets it apart from systematic error, which introduces a consistent, repeatable bias that can often be calibrated out.
Defining Random Error
Imagine taking multiple temperature readings with a digital thermometer in a stable environment. Despite the temperature remaining constant, each reading might show a minuscule difference – perhaps 25.0°C, then 25.1°C, then 24.9°C. These minute, fluctuating deviations are manifestations of random error. They are not due to a faulty calibration (that would be systematic error) but rather to the intrinsic limitations and variabilities of the measurement system and its environment.
In a technological context, random errors can be thought of as “noise.” This noise is an inherent property of physical systems and digital processes, ensuring that no measurement or operation is ever perfectly reproducible down to infinite decimal places. The goal, therefore, is not to eliminate random error entirely – an impossible feat – but rather to understand its characteristics, quantify its magnitude, and minimize its impact to an acceptable level.
Sources of Randomness in Tech
The origins of random errors in technology are diverse, stemming from a confluence of physical, environmental, and operational factors:
- Environmental Factors: The physical world is inherently dynamic. Fluctuations in temperature, humidity, atmospheric pressure, electromagnetic interference (EMI), or vibrations can all subtly affect electronic components and measurement devices. For instance, an IoT sensor deployed in a dynamic environment might pick up electrical noise from nearby machinery or slight temperature changes affecting its internal circuitry.
- Instrument Limitations and Noise: All hardware, from the simplest resistor to the most sophisticated AI accelerator, has inherent physical limitations. Thermal noise (Johnson-Nyquist noise) generated by the random motion of electrons within a conductor is a universal example. Analog-to-digital converters (ADCs) introduce quantization noise. These fundamental limitations contribute to the “floor” of precision beyond which an instrument cannot reliably measure.
- Measurement Process Variability: Even with perfect instruments, the act of measurement itself can introduce randomness. Slight variations in positioning, timing of data acquisition, sampling rates, or even the interaction of a user with a device can lead to unpredictable differences. In a software context, the precise timing of operations in a multi-threaded application can vary, leading to different execution paths and outcomes that appear random.
- Systemic Complexity and Stochastic Processes: Modern technology systems are incredibly complex, with countless interacting components. In large software systems, concurrent processes, network latency, resource contention, and memory management can introduce variability that appears random. Machine learning algorithms, particularly those involving stochastic gradient descent or random initialization, inherently incorporate randomness as part of their design to explore solution spaces effectively.
Statistical Characteristics
A crucial characteristic of random errors is their tendency to follow certain statistical distributions, most notably the normal (or Gaussian) distribution, especially when many independent random factors contribute to the error. When plotted, the errors will typically cluster around zero (meaning no error) with symmetrically diminishing frequency as the magnitude of the error increases.
This statistical behavior allows engineers and data scientists to:
- Quantify Error: Use metrics like standard deviation and variance to describe the spread or magnitude of the random error. A smaller standard deviation indicates less variability and greater precision.
- Estimate True Values: By taking multiple measurements, the mean of these measurements provides a better estimate of the true value than any single measurement, as random errors tend to cancel each other out over many trials.
- Determine Confidence: Establish confidence intervals around an estimated value, indicating the range within which the true value is likely to fall, given the observed random errors.
Impact of Random Errors Across Technology Domains
Random errors are not just theoretical concepts; their effects ripple through virtually every aspect of technology, influencing everything from the accuracy of sensor data to the reliability of software and the security of digital communications.
Data Acquisition and Sensor Technology
In the realm of IoT, autonomous systems, and scientific instrumentation, sensors are the eyes and ears of technology. Random noise in sensor readings – whether from accelerometers, temperature probes, cameras, or LiDAR – directly impacts the quality and reliability of the data. For an autonomous vehicle, erratic sensor readings due to random error could lead to misinterpretations of the environment, causing navigation errors or safety hazards. In medical devices, noisy data can obscure critical diagnostic information. Filtering and averaging techniques are often applied to raw sensor data to smooth out these random fluctuations and extract a more stable signal.
Software Development and AI/ML
While software is often considered deterministic, random errors can manifest in several ways. In concurrent programming, race conditions can lead to unpredictable behavior where the output depends on the precise, non-deterministic timing of threads or processes. Performance profiling often reveals random fluctuations in execution times due to operating system scheduling, cache misses, or background processes.
In Artificial Intelligence and Machine Learning, random errors are pervasive:
- Noisy Training Data: Real-world datasets invariably contain noise and outliers that function as random errors, potentially leading models to learn incorrect patterns or generalize poorly.
- Stochastic Algorithms: Many core ML algorithms, like stochastic gradient descent, rely on randomness to explore complex solution spaces efficiently. The random initialization of weights in neural networks can lead to slightly different models trained on the same data.
- Robustness and Explainability: The presence of random noise can test the robustness of an AI model, and understanding its impact is crucial for developing models that are reliable in real-world, unpredictable environments.
Digital Security and Cryptography
Randomness is a cornerstone of digital security. Cryptographic systems rely heavily on truly random numbers for generating secure keys, nonces, and initialization vectors. If the “randomness” is predictable – i.e., subject to a subtle systematic bias or a weak pseudo-random number generator (PRNG) that can be reverse-engineered – it can introduce critical vulnerabilities, allowing attackers to compromise encryption or authentication mechanisms. The quest for “true randomness” from physical sources like thermal noise or atmospheric noise, rather than algorithmic pseudo-randomness, is a constant effort in high-security applications.
Network Communications and Distributed Systems
In distributed systems and network communications, random errors appear as unpredictable packet loss, variable latency (jitter), and intermittent connectivity issues. These fluctuations can disrupt real-time applications like video conferencing, online gaming, or financial trading. Data packets can be randomly corrupted during transmission due to electromagnetic interference or hardware glitches. Error correction codes (ECC) are widely used to detect and often correct these random bit flips, ensuring data integrity despite the noisy channels. The unpredictable nature of these errors necessitates resilient network protocols and system designs that can gracefully handle transient failures.
Strategies for Identifying and Quantifying Random Error

Effectively managing random errors begins with their identification and quantification. Since these errors are unpredictable, statistical methods are indispensable tools for understanding their characteristics.
Repeated Measurements and Statistical Analysis
The most fundamental approach to dealing with random error is to take multiple measurements of the same phenomenon under identical conditions. By doing so, the random fluctuations tend to average out, allowing for a more accurate estimation of the true value.
- Mean and Standard Deviation: Calculating the arithmetic mean of several measurements provides a better estimate of the true value, as positive and negative random errors cancel each other out. The standard deviation quantifies the spread or variability of the measurements around the mean, serving as a direct measure of the magnitude of the random error.
- Confidence Intervals: Statistical analysis allows the calculation of confidence intervals, which provide a range within which the true value is expected to lie with a certain probability (e.g., 95% confidence). This helps to convey the inherent uncertainty introduced by random errors.
- Sample Size: Increasing the number of measurements (sample size) generally reduces the impact of random error on the estimated mean, making the estimate more precise.
Calibration and Benchmarking
While primarily used for systematic errors, calibration and benchmarking play a role in characterizing random error. By measuring known standards, technologists can not only identify consistent biases but also observe the inherent variability (noise floor) of their instruments. Running controlled experiments with known inputs allows engineers to isolate and quantify the random error introduced by a specific component or process under various operating conditions.
Data Visualization and Anomaly Detection
Visualizing data over time or across different conditions can reveal patterns indicative of random errors. Scatter plots, histograms, and time-series graphs can highlight variability, outliers, or unusual distributions that suggest the presence and characteristics of random noise. Advanced anomaly detection algorithms, often powered by machine learning, can automatically identify data points or patterns that deviate significantly from expected behavior, which could be due to either random error or genuine system anomalies.
Logging and Monitoring
In complex software and distributed systems, robust logging and real-time monitoring are critical. By capturing granular data about system states, resource utilization, and operation outcomes, developers can identify intermittent issues and unpredictable performance variations that point to random errors. Analyzing logs for specific error codes, warning messages, or unusual timing data can help diagnose the root causes of randomness and characterize its frequency and impact.
Mitigating and Managing Random Error in Tech Systems
While random errors cannot be eliminated, their impact can be significantly reduced through a combination of hardware design, software techniques, and robust system architecture.
Hardware-Level Solutions
- Sensor Fusion: In scenarios requiring high accuracy, like autonomous navigation, data from multiple heterogeneous sensors (e.g., camera, LiDAR, radar, GPS) is combined. Sensor fusion algorithms, such as Kalman filters, leverage the strengths of each sensor and use statistical models to estimate the true state more accurately by averaging out random noise from individual sensors.
- Filtering Techniques: Both analog and digital filters are extensively used to reduce noise. Analog filters smooth raw signals before digitization, while digital filters (e.g., moving averages, median filters, Butterworth filters, Kalman filters) are applied to digitized data to suppress random fluctuations while preserving the underlying signal.
- Redundancy and Error Correction Codes (ECC): In data transmission and storage, redundancy is key. Error Correction Codes add redundant information to data packets. If random noise corrupts some bits during transmission, the ECC can detect and often correct these errors without requiring retransmission, ensuring data integrity and system reliability.
Software and Algorithmic Approaches
- Robust Algorithms: Designing algorithms that are inherently less sensitive to noisy or slightly incorrect inputs is crucial. For instance, in control systems, PID controllers are designed with parameters that can tolerate some measurement noise.
- Ensemble Methods in AI: In machine learning, ensemble methods like Random Forests or Gradient Boosting combine the predictions of multiple individual models. This “wisdom of the crowd” approach significantly reduces the variance (the impact of random error) compared to a single model, leading to more stable and accurate predictions.
- Defensive Programming: Writing code that anticipates and gracefully handles unpredictable inputs, unexpected system states, or timing variations is a fundamental practice. This includes input validation, robust error handling, and timeout mechanisms.
- Rigorous Testing and Validation: Comprehensive testing under various conditions, including stress testing and performance testing, helps identify and characterize how random errors manifest in software. Continuous integration and automated testing pipelines help catch regressions that might reintroduce variability.
System Design Principles
- Fault Tolerance: Designing systems to continue operating correctly even when individual components fail or produce erroneous outputs (due to random errors) is paramount. This involves redundancy at various levels – hardware, software, and data.
- High Availability: Aiming for minimal downtime, high availability systems use redundant components and rapid failover mechanisms to absorb intermittent random failures and ensure continuous service.
- Statistical Process Control (SPC): Monitoring system metrics over time using SPC techniques helps detect deviations from expected statistical norms. This allows operators to identify when random errors might be increasing in magnitude or when a systematic problem is beginning to emerge.
The Future of Error Management in Advanced Technologies
As technology advances, the nature of random errors and the strategies to manage them continue to evolve.
AI-Driven Error Correction and Prediction
The increasing sophistication of AI and machine learning offers new avenues for managing random errors. ML models can be trained to recognize patterns of noise and automatically filter or correct data in real-time. Predictive maintenance, powered by AI analyzing sensor data, can anticipate component failures before they lead to catastrophic errors, mitigating the impact of random hardware degradation.
Quantum Computing and Error Correction
Quantum computing introduces entirely new challenges in error management. Qubits are incredibly fragile and susceptible to “decoherence” caused by random environmental interactions, leading to errors. Quantum Error Correction (QEC) is a critical area of research, developing techniques to preserve the delicate quantum states and compute reliably despite the overwhelming influence of random noise. This field is pushing the boundaries of what is possible in error management.
The Pursuit of “Deterministic” Systems
While complete elimination of random errors remains an impossibility given the laws of physics, the relentless pursuit of more predictable and deterministic systems continues. From formal verification methods that mathematically prove software correctness to advances in ultra-precise manufacturing, the goal is to reduce variability to negligible levels, allowing for unprecedented levels of reliability and accuracy in future technological marvels.
Conclusion
Random error is an inescapable aspect of our technological landscape. It is the subtle, unpredictable whisper in every measurement, the inherent variability in every process. Far from being a mere nuisance, understanding random error is fundamental to engineering reliable, accurate, and secure technological systems. By acknowledging its presence, characterizing its behavior through statistical rigor, and strategically employing a diverse toolkit of mitigation techniques – from sophisticated hardware filters to advanced AI algorithms and robust system designs – we don’t eliminate randomness, but rather master its influence. As technology continues its inexorable march forward, the ability to effectively manage random error will remain a cornerstone of innovation, ensuring that our digital future is built on a foundation of precision and trust.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.