In the modern technological landscape, data is often described as the new oil. However, raw data is only as valuable as the structure that supports it. For software developers, data architects, and tech enthusiasts, understanding how data relates to other data is the cornerstone of building scalable, reliable applications. At the heart of this structural logic lies a fundamental concept in relational database management systems (RDBMS): the Foreign Key.
A foreign key is more than just a technical constraint; it is the connective tissue of a database. It ensures that information remains consistent across multiple tables, preventing the fragmentation that leads to “data rot” or system errors. To truly appreciate the foreign key, one must look beyond the syntax and understand its role in maintaining referential integrity within a digital ecosystem.
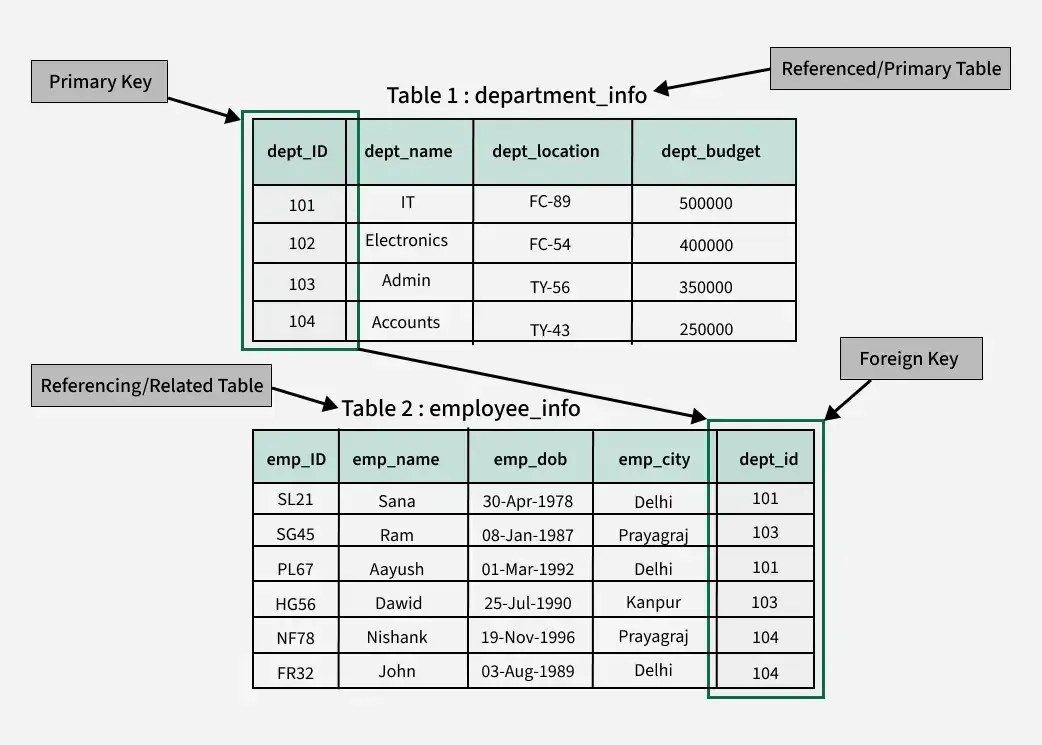
The Foundation of Relational Databases
Relational databases, such as PostgreSQL, MySQL, and Microsoft SQL Server, are designed to store data in tables consisting of rows and columns. Unlike flat files or simple spreadsheets, these systems excel at organizing complex information by breaking it down into logical, manageable pieces. The foreign key is the mechanism that allows these pieces to talk to one another.
Bridging the Gap Between Tables
In a well-designed database, “normalization” is the process of organizing data to reduce redundancy. For example, instead of storing a customer’s name and address every time they place an order, a developer will create one table for Customers and another for Orders.
The foreign key acts as the bridge. In the Orders table, rather than repeating all the customer’s details, you simply store a CustomerID. This column is the foreign key. it “points” back to the unique identifier in the Customers table, establishing a formal link between the two entities.
Primary Key vs. Foreign Key: The Dynamic Duo
To understand a foreign key, one must first understand the primary key. A primary key is a unique identifier for a record within its own table. No two rows can have the same primary key, ensuring that every piece of data is reachable and distinct.
The foreign key is essentially a primary key’s representative in another table. While the primary key identifies a record at its source, the foreign key references that record from a destination. This relationship is what creates the “relational” aspect of relational databases. Without these keys, a database would be nothing more than a collection of isolated islands of information.
The Concept of “Parent” and “Child” Tables
In technical terms, the relationship established by a foreign key creates a hierarchy. The table containing the primary key (the source of truth) is referred to as the “parent” table or the referenced table. The table containing the foreign key is the “child” table or the referencing table. This hierarchy is vital for maintaining order, as it dictates how data can be inserted, updated, or deleted without causing a systemic breakdown.
Maintaining Referential Integrity: The Rules of Engagement
The primary purpose of a foreign key is to enforce referential integrity. This is a set of rules that ensures the relationship between tables remains consistent. If a foreign key exists, the database engine will prevent any action that would break the link between the child and parent tables.
Preventing “Orphan” Records
One of the most significant risks in database management is the creation of “orphan” records. Imagine a scenario where an order exists in a database, but the customer associated with that order has been deleted. This results in data that is logically impossible and functionally useless.
Foreign keys prevent this by ensuring that you cannot enter a value in the child table if that value does not already exist in the parent table. If you try to create an order for CustomerID 999, but your Customers table only goes up to ID 500, the database will reject the entry, maintaining the logic of the system.
Referential Actions: ON DELETE and ON UPDATE
Database administrators have several tools at their disposal to manage what happens when data in a parent table changes. These are known as referential actions, and they define the behavior of the foreign key constraint:
- CASCADE: If a record in the parent table is deleted or updated, the corresponding records in the child table are automatically deleted or updated. This is useful for keeping data synchronized.
- SET NULL: If a parent record is deleted, the foreign key in the child table is set to NULL. This keeps the child record but severs the link.
- RESTRICT/NO ACTION: The database prevents the deletion of a parent record if child records still point to it. This is the safest default for preventing accidental data loss.
The Impact of Cascading Actions
While cascading actions are powerful, they require careful planning. In a large-scale enterprise application, a single “delete” command on a primary record could trigger a chain reaction that wipes out thousands of related entries across multiple tables. Developers must weigh the convenience of automation against the risk of unintended mass data loss, often opting for “Restrict” actions in sensitive financial or user-profile environments.
Mapping Relationships Through Foreign Keys
Not all data relationships are created equal. Depending on the software requirements, foreign keys are used to facilitate different types of logical connections.

One-to-Many: The Standard
The most common relationship in database design is the “one-to-many” relationship. In this scenario, one record in Table A can be associated with multiple records in Table B, but each record in Table B is associated with only one record in Table A. For example, one Author can write many Books, but in a standard database model, each Book is linked back to one primary AuthorID. The foreign key resides on the “many” side of the equation.
One-to-One: The Specialized Connection
A “one-to-one” relationship occurs when a record in Table A can have only one matching record in Table B. While this is less common—as such data could often just be in the same table—it is used for security or performance optimization. For instance, a User table might contain basic login info, while a User_Sensitive_Data table (containing encrypted keys or social security numbers) holds the rest. Here, the foreign key is also a unique constraint, ensuring the one-to-one link.
Many-to-Many: The Junction Table
In cases where many records in Table A relate to many records in Table B (e.g., Students and Courses), a foreign key cannot exist directly in either table. Instead, tech professionals use a “junction table” or “join table.” This middle-man table contains two foreign keys: one pointing to Students and one pointing to Courses. This architecture allows for complex, multi-layered data mapping that is essential for social networks, e-commerce platforms, and educational tools.
Foreign Keys in Modern Software Architecture
As we move toward high-performance computing and distributed systems, the role of the foreign key has evolved. While it remains a staple of SQL databases, its implementation is often discussed in the context of system performance and architectural philosophy.
Enhancing Data Quality and Consistency
For any business-critical application, data quality is paramount. Foreign keys act as a first line of defense against “dirty data.” By enforcing rules at the database level rather than the application level, developers ensure that even if there is a bug in the software code, the database remains logically sound. This “hard-coded” integrity is far more reliable than relying solely on front-end validation.
Performance Considerations and Indexing
There is a common misconception in the tech world that foreign keys slow down databases. While it is true that the database must perform a “lookup” to verify the existence of a key during an insert or update, the performance cost is usually negligible compared to the benefits.
Furthermore, foreign keys are almost always paired with indexes. Most modern RDBMS automatically index foreign key columns, which actually speeds up “JOIN” queries. When you ask a database to “find all orders for Customer X,” the index created by the foreign key allows the system to find that data in milliseconds, even across millions of rows.
When to Avoid Foreign Keys: Microservices vs. Monoliths
In the era of microservices, the traditional foreign key faces a challenge. When a system is broken into small, independent services, each service often has its own isolated database. You cannot have a physical foreign key constraint that spans across two different databases or different physical servers.
In these distributed architectures, developers use “logical foreign keys.” The application code manages the relationship, and data consistency is often handled via “eventual consistency” models. However, for monolithic applications or centralized data warehouses, the physical foreign key remains the gold standard for reliability.
Implementation and Best Practices for Developers
To leverage foreign keys effectively, software engineers follow a set of industry best practices that ensure the database remains readable and maintainable over time.
Naming Conventions for Clarity
Clear naming is essential for collaborative tech environments. A standard practice is to name the foreign key column after the table it references, followed by the name of the primary key column (e.g., user_id or account_uuid). Consistent naming makes it immediately obvious to any developer looking at the schema how the tables are interconnected, reducing the learning curve for new team members.
Handling Nullable Foreign Keys
Should a foreign key always require a value? Not necessarily. This depends on whether the relationship is “mandatory” or “optional.” For example, in a database for a corporate office, an Employee table might have a ManagerID foreign key. Since the CEO doesn’t have a manager, that column must be “nullable.” Understanding when to allow NULL values in foreign keys is a vital part of nuanced database design.
Testing and Validating Relationships
In modern DevOps workflows, database schemas are often managed through code (Migrations). It is crucial to include tests that validate foreign key constraints. Automated tests can simulate “illegal” entries to ensure the database correctly rejects them. This proactive approach to data integrity prevents small errors from ballooning into massive data corruption issues down the line.

Conclusion
The foreign key is a testament to the elegance of relational design. By providing a structured way to link disparate pieces of information, it transforms a collection of tables into a coherent, intelligent system. Whether you are building a simple mobile app or a complex global financial platform, the foreign key ensures that your data remains accurate, your relationships remain intact, and your system remains scalable. In an age where data drives every decision, the foreign key remains an indispensable tool in the technologist’s toolkit.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.