In the world of technology, the “back-end” is the skeletal structure and nervous system of every digital application. It is the invisible architecture that supports the user interface, processes data, and ensures that the digital experience remains upright and functional. When a developer or a CTO says their “back has gone out,” they aren’t talking about physical therapy or spinal alignment—they are referring to a critical failure in the back-end infrastructure.
When your back-end goes out, the consequences are immediate and often catastrophic. The sleek, polished front-end interface becomes a hollow shell, unable to fetch data, process transactions, or authenticate users. In an era where 99.99% uptime is the expected standard, a “slipped disc” in your server cluster can result in millions of dollars in lost revenue and irreversible damage to brand reputation. This article explores the anatomy of a back-end collapse, the immediate symptoms of infrastructure failure, and how modern organizations can “strengthen their core” to prevent digital paralysis.
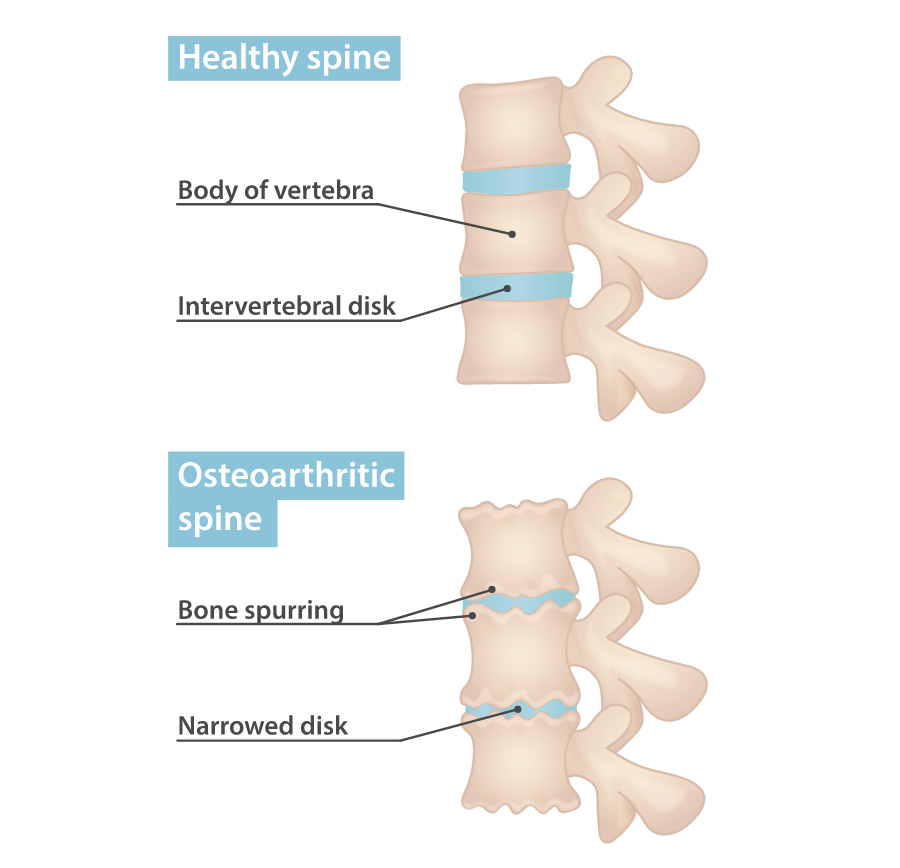
The Anatomy of a System Collapse: Understanding the Back-End
To understand what happens when the back-end fails, one must first understand the complexity of the modern tech stack. The back-end is not a single entity; it is a symphony of interconnected parts including servers, databases, Application Programming Interfaces (APIs), and middleware.
The Backbone: Server Infrastructure and Cloud Nodes
The physical or virtual servers are the vertebrae of your system. Whether you are using on-premise hardware or cloud providers like AWS, Azure, or Google Cloud, these nodes provide the computational power required to run your logic. When a server “goes out,” it is often due to hardware failure, hypervisor glitches, or connectivity issues within the data center. Without these vertebrae, the application has no support structure upon which to stand.
The Nervous System: APIs and Database Connections
If servers are the bones, APIs and database connections are the nerves. They transmit signals between the user’s device and the data storage layer. A failure here is often more subtle but equally debilitating. If the database connection string is broken or an API rate limit is exceeded, the “brain” of the application (the logic layer) cannot communicate with the “limbs” (the front-end). This results in a system that is technically “online” but functionally paralyzed.
Immediate Symptoms: From Latency to Total Blackout
When a human’s back goes out, the first sign is often a sharp pain followed by limited mobility. In technology, the symptoms follow a similar trajectory. Systems rarely fail in a vacuum; they usually exhibit warning signs before a total blackout occurs.
The Silent Creep of High Latency
One of the first signs that your back-end is struggling is increased latency. This is the digital equivalent of a “stiff back.” Users might notice that pages take an extra two seconds to load, or that the “submit” button spins for an eternity. Under the hood, this is often caused by database locks, slow queries, or a bottleneck in the network throughput. High latency is a precursor to a crash; it indicates that the system is straining under its current load and is one spike away from a complete collapse.
Cascading Failures and the “Thundering Herd” Problem
When one component of the back-end fails, it often triggers a “cascading failure.” Imagine a load balancer that directs traffic to three servers. If one server goes out, the load is redistributed to the remaining two. This increased pressure causes the second server to overheat and fail, leaving the third server to face 300% of its intended capacity. This is known as the “Thundering Herd” problem. Within minutes, the entire infrastructure collapses like a house of cards because the remaining components cannot compensate for the initial injury.
Diagnosing the Root Cause: The MRI of Tech
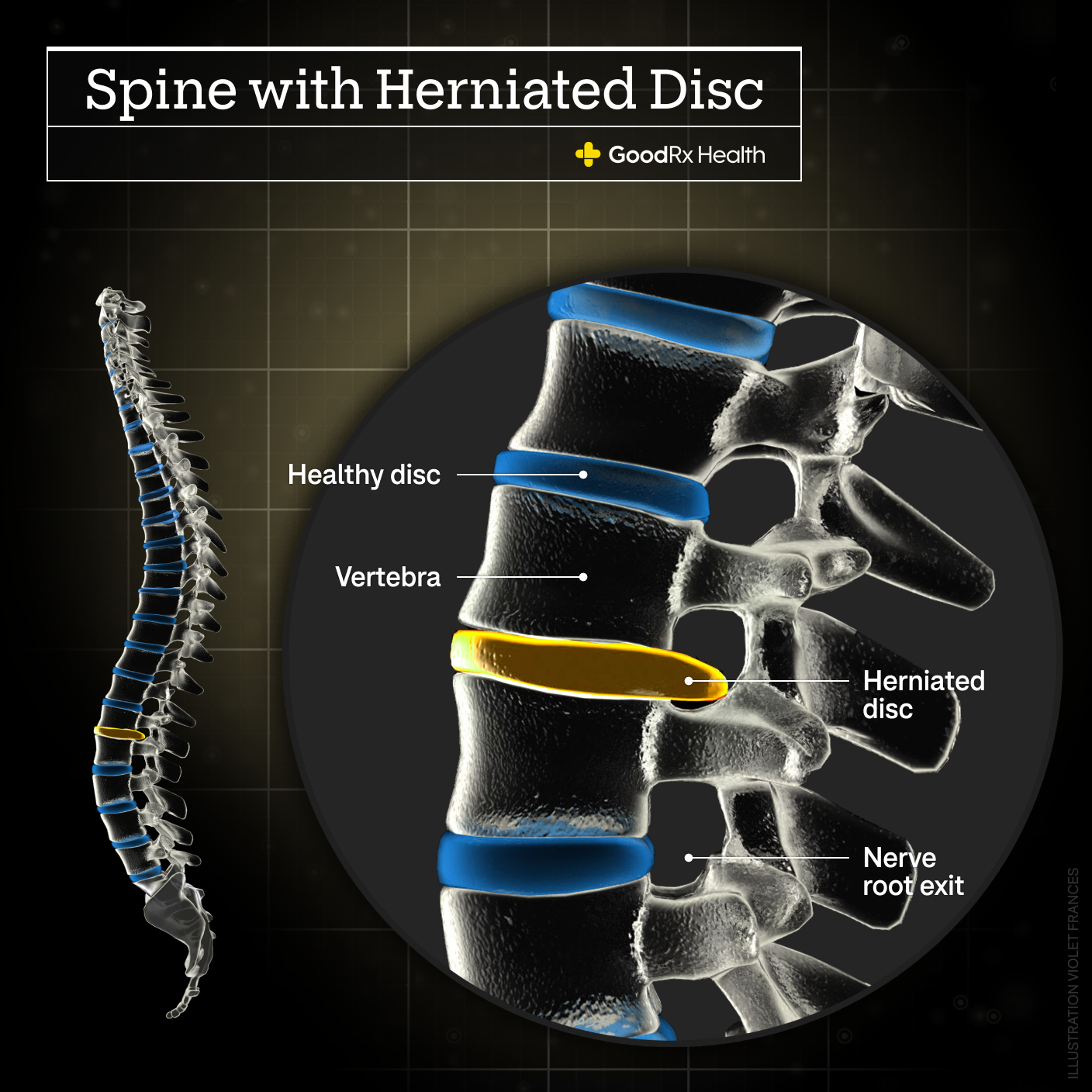
Once the system has “gone out,” the immediate priority is diagnosis. In tech, this involves deep-dive observability and monitoring to find the specific “disc” that has slipped.
Configuration Drift and Human Error
Statistically, the most common cause of a back-end failure is not a malicious hack or a hardware malfunction, but human error. Configuration drift occurs when small, undocumented changes are made to the environment over time, leading to an unstable state. A developer might tweak a firewall rule or update a library version in production without proper testing. When the system eventually reboots or scales, these “tweaks” prevent it from coming back online. This is the digital equivalent of poor posture—over time, small bad habits lead to a major injury.
Resource Exhaustion: Memory Leaks and CPU Spikes
Sometimes the back-end goes out because it simply runs out of breath. Memory leaks occur when a program allocates memory but fails to release it back to the system. Over hours or days, the available RAM dwindles until the operating system is forced to kill the process to save itself. Similarly, a runaway process might consume 100% of the CPU, leaving no room for the system to handle incoming requests. These resource exhaustion events require a “surgical” look at the code to identify the inefficient algorithms or unclosed loops causing the strain.
The Recovery Protocol: Rehabilitation for Your Stack
Recovering from a back-end failure requires more than just “turning it off and on again.” It requires a structured rehabilitation protocol to ensure the system returns to a stable state without losing data integrity.
Disaster Recovery and Business Continuity Planning
Every enterprise-level tech organization must have a Disaster Recovery (DR) plan. This involves having “hot” or “cold” standbys—secondary systems located in different geographic regions that can take over if the primary “back” goes out. Recovery Time Objective (RTO) and Recovery Point Objective (RPO) are the metrics that define how quickly you can stand back up and how much data you might lose in the process. A robust recovery protocol ensures that even if a data center is hit by a natural disaster, the digital spine remains intact.
Implementing Redundancy and High Availability
To prevent the back from going out in the first place, engineers use redundancy. This means having multiple copies of every critical component. Instead of one database, you have a primary and several read-replicas. Instead of one server, you have an auto-scaling group that adds more “muscle” (instances) as the load increases. High Availability (HA) architecture is the physical therapy of the tech world; it builds a system that is flexible, resilient, and capable of enduring heavy stress without snapping.
Future-Proofing: Strengthening the Digital Core
Just as a person performs core exercises to prevent future back injuries, a tech company must invest in modern architectural patterns to ensure long-term stability.
Moving Toward Microservices and Serverless Architecture
The “monolithic” architecture of the past is like a single, rigid spine; if one vertebrae breaks, the whole body fails. Modern tech is moving toward microservices, where the back-end is broken into dozens of small, independent services. If the “payment service” goes out, the “search service” and “user profile service” continue to function. Furthermore, serverless computing (like AWS Lambda) allows developers to run code without managing servers at all, shifting the “back-end health” responsibility to the cloud provider.
The Role of AI in Predictive Maintenance and Self-Healing
The future of back-end resilience lies in AIOps—Artificial Intelligence for IT Operations. AI models can now monitor system telemetry in real-time, identifying patterns that precede a failure. If the AI detects a specific type of traffic spike or a slow increase in memory usage, it can automatically spin up new resources or “self-heal” by restarting compromised containers before the user ever notices a problem. By using machine learning, companies can move from reactive “emergency surgery” to proactive “wellness care.”
Conclusion
When your back goes out in the digital world, time is your greatest enemy. Every minute of downtime translates to lost data, lost revenue, and lost trust. However, by understanding the complex anatomy of the back-end, recognizing the early symptoms of failure, and implementing a rigorous “exercise” routine of redundancy and monitoring, organizations can build systems that are not just functional, but anti-fragile. In the high-stakes environment of modern technology, a strong back-end isn’t just a luxury—it is the foundation upon which every successful digital empire is built.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.