In the modern technological landscape, data is often described as the “new oil.” However, this analogy is incomplete. Much like crude oil pulled from the earth, raw data is rarely useful in its primary state. It is often messy, disorganized, and riddled with impurities. To power the sophisticated engines of artificial intelligence, machine learning, and enterprise analytics, data must undergo a rigorous refinement process. This process is known as data cleaning.
But what does cleaning data mean in a practical, technical sense? Beyond simple “tidying up,” data cleaning (or data scrubbing) is a complex technical workflow that involves identifying and correcting errors, inconsistencies, and inaccuracies within a dataset. In an era where software decisions govern everything from medical diagnoses to autonomous driving, data cleaning is the thin line between a revolutionary insight and a catastrophic system failure.

1. The Technical Foundation: Defining Data Cleaning
At its core, data cleaning is the process of fixing or removing incorrect, corrupted, incorrectly formatted, duplicate, or incomplete data within a dataset. When combining multiple data sources, there are many opportunities for data to be duplicated or mislabeled. If data is incorrect, outcomes and algorithms are unreliable, even though they may look correct.
The “Garbage In, Garbage Out” (GIGO) Principle
In computer science, the GIGO principle is a fundamental law. If the input data is flawed, the output—no matter how advanced the software—will be equally flawed. A high-performance neural network trained on “dirty” data will produce biased or nonsensical results. Therefore, data cleaning is not a secondary task; it is the most critical step in the data science pipeline, often consuming up to 80% of a data professional’s time.
The Lifecycle of Data Quality
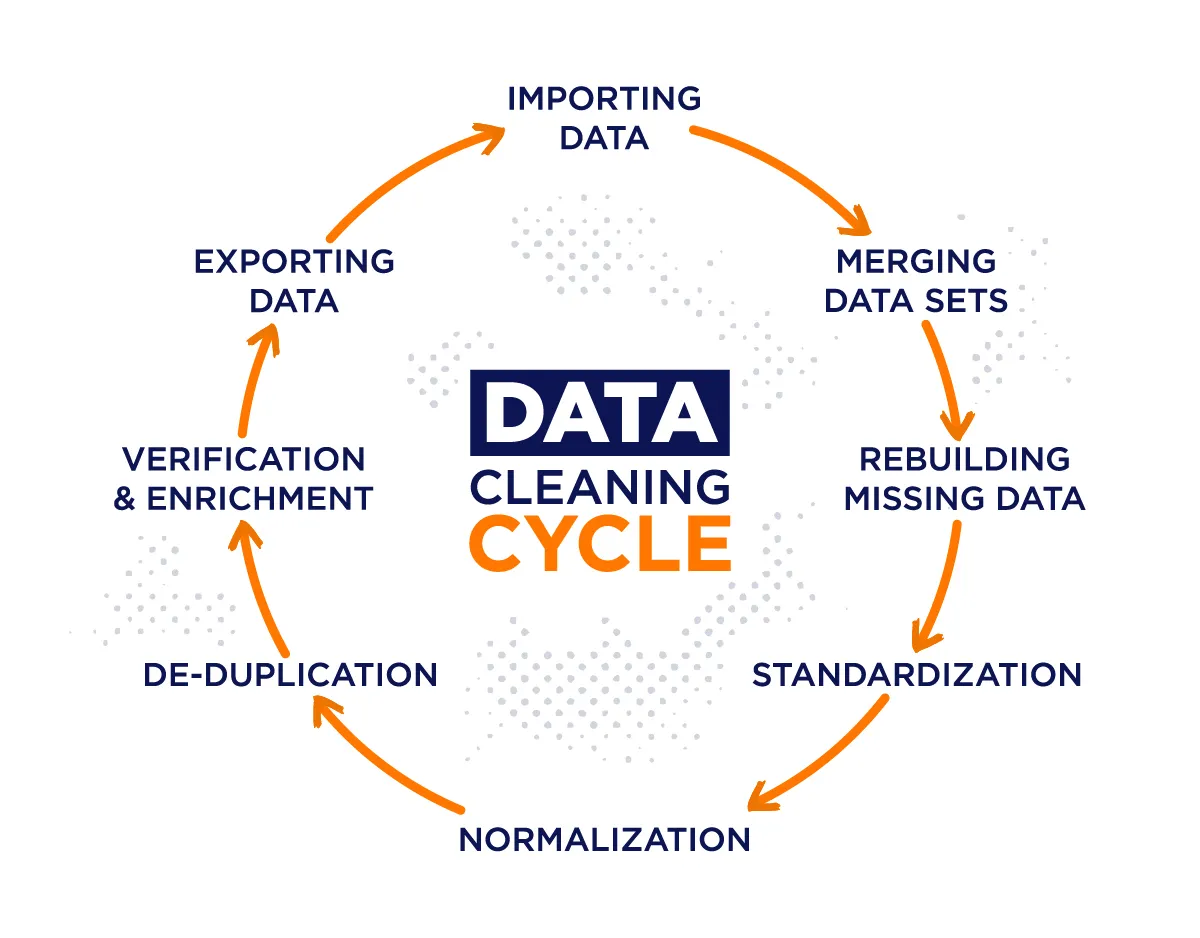
Data cleaning is part of the broader Data Quality Management (DQM) framework. It involves a cycle of:
- Profiling: Inspecting the data to understand its structure and quality.
- Standardization: Ensuring that data follows a consistent format.
- Validation: Checking that the “cleaned” data meets specific technical requirements.
2. The Core Workflow: How Data is Scrubbed
To understand what cleaning data means, one must look at the specific technical operations performed during the process. This isn’t just about deleting rows; it’s about surgical precision in data manipulation.
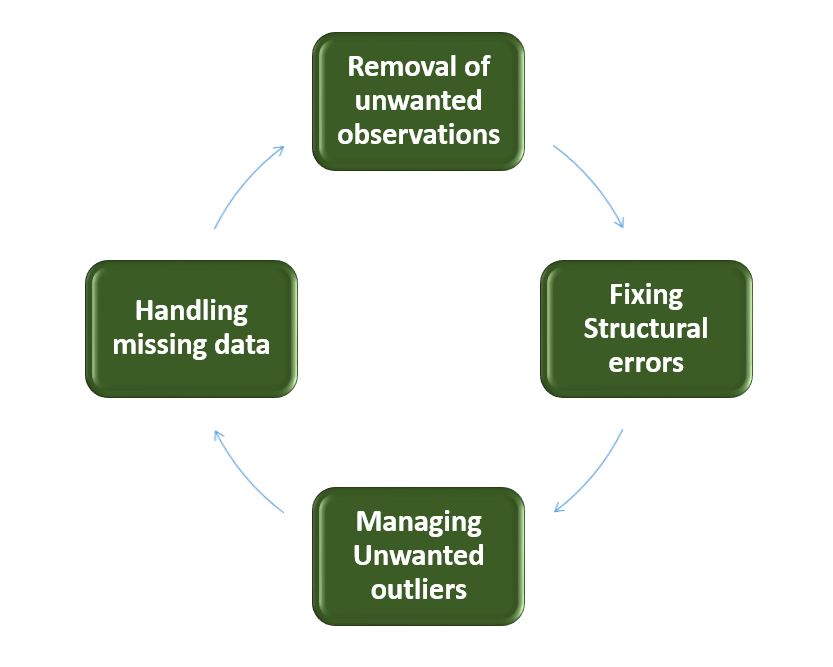
Removing Duplicates and Irrelevant Observations
When you aggregate data from various software tools or scrapers, duplicates are inevitable. This often happens during the ETL (Extract, Transform, Load) process. Deduplication involves identifying identical records and merging them or removing the redundant copies. Similarly, “irrelevant” observations are those that do not fit the specific problem the software is trying to solve. For example, if you are analyzing the battery life of IoT sensors, data regarding the color of the sensor’s casing is “noise” that must be filtered out to optimize processing speed.
Fixing Structural Errors
Structural errors occur when data is labeled or categorized inconsistently. This is common in “string” data (text). For instance, a database might have “N/A,” “Not Applicable,” and “na” all representing the same thing. A technical cleaning script would use regular expressions (Regex) or mapping functions to normalize these into a single, machine-readable format.
Handling Missing Values
Missing data is a common plague in software development. You cannot simply ignore empty cells, as many algorithms will crash if they encounter a null value. Tech professionals use two main strategies:
- Deletion: Removing the record entirely (only if the dataset is large enough).
- Imputation: Using statistical methods or AI to “guess” the missing value based on other data points (e.g., using the mean or median).
Managing Outliers
Outliers are data points that deviate significantly from the rest of the set. While some outliers are legitimate, others are the result of sensor errors or “fat-finger” data entry. Technical analysis involves using visualizations (like box plots) or statistical methods (like Z-scores) to identify these anomalies and determine if they should be removed to prevent skewed results.
3. Tools of the Trade: The Tech Stack for Data Cleaning
Modern data cleaning has evolved from manual Excel filtering to automated, code-driven workflows. The choice of tools depends on the scale of the data and the specific requirements of the application.
Python and R: The Programming Powerhouses
For developers and data engineers, Python is the gold standard. Libraries like Pandas and NumPy provide robust functions for handling missing data, merging datasets, and performing complex transformations. R, a language built for statistics, offers the Tidyverse ecosystem, which is specifically designed around the philosophy of “tidy data.”
Specialized Data Preparation Software
For enterprise-level tasks, dedicated software like OpenRefine (formerly Google Refine) allows for the cleaning of large, messy datasets through a browser-based interface. Other tools like Trifacta or Alteryx use machine learning to suggest “recipes” for cleaning data, allowing non-developers to perform complex data transformations.
AI-Driven Automation
The newest trend in tech is the use of AI to clean data for AI. Automated Machine Learning (AutoML) tools now include “auto-cleaning” features. These tools can automatically detect data drift, identify outliers using isolation forests, and even suggest the best imputation methods without human intervention. This significantly reduces the time-to-insight for tech companies.
4. Data Cleaning and Digital Security: A Critical Intersection
The importance of cleaning data extends beyond performance—it is a cornerstone of digital security and privacy compliance.
Mitigating Security Risks
“Dirty” data can lead to security vulnerabilities. For example, if an application’s data cleaning process fails to sanitize user inputs, it could be susceptible to SQL injection attacks, where malicious code is inserted into a database. Clean data ensures that the input types expected by the software are the only ones processed, creating a more secure digital environment.
Ensuring Privacy and Compliance (GDPR/CCPA)
In the world of digital security, data cleaning is synonymous with data minimization. Under regulations like the GDPR, companies are required to delete data that is no longer necessary for the purpose it was collected. Data cleaning scripts can be programmed to automatically identify and purge PII (Personally Identifiable Information) that is outdated or redundant, ensuring that the tech stack remains compliant and the company’s “attack surface” is minimized.
Integrity in Algorithmic Decision-Making
When software is used for sensitive tasks like credit scoring or security clearances, “biased” data is a major technical failure. Data cleaning includes the process of auditing datasets for bias—ensuring that certain demographics aren’t over-represented or under-represented in a way that would lead to discriminatory software outputs.
5. The Future of Data Cleaning: Real-Time Pipelines
As we move toward the “Internet of Everything,” the concept of cleaning data is shifting from batch processing to real-time streaming.
From Static to Streaming
Traditionally, data was cleaned in batches—usually at the end of the day or week. However, for technologies like high-frequency trading apps or real-time cybersecurity monitors, data must be cleaned as it is generated. This requires “Data Observability” tools that monitor the health of data pipelines in real-time, catching errors the moment they enter the system.
The Rise of the Data Engineer
The increasing complexity of data cleaning has birthed a new specialized role: the Data Engineer. While Data Scientists focus on building models, Data Engineers focus on the “plumbing”—building the automated pipelines that clean, transform, and transport data. This reflects the tech industry’s realization that the infrastructure behind data is just as important as the data itself.
Conclusion: Data Cleaning as a Continuous Discipline
In conclusion, cleaning data is the rigorous technical process of ensuring that digital information is accurate, consistent, and secure. It is the fundamental bridge between raw, chaotic input and the sophisticated software outputs we rely on every day.
As AI tools continue to permeate every aspect of our lives, the demand for clean data will only grow. For developers, engineers, and tech enthusiasts, mastering the art of the “clean” is not just a housekeeping task—it is a vital skill in the quest for digital excellence. Without the meticulous work of data scrubbing, the most advanced algorithms in the world would be nothing more than expensive engines running on sludge. By prioritizing data integrity, we ensure that the future of technology is built on a foundation of truth.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.