In biological terms, the gallbladder is a small but vital organ that stores and concentrates bile, releasing it exactly when the body needs to digest fats. While it might seem a world away from silicon chips and cloud clusters, the “gallbladder” function is one of the most fundamental concepts in information technology. In the tech niche, we refer to this as the “Buffer Strategy” or “Caching Layer.” Just as the human body requires a specialized storage unit to handle the sudden influx of complex nutrients, a high-performance computing system requires sophisticated mechanisms to manage data bursts, prevent bottlenecks, and ensure the seamless digestion of information.
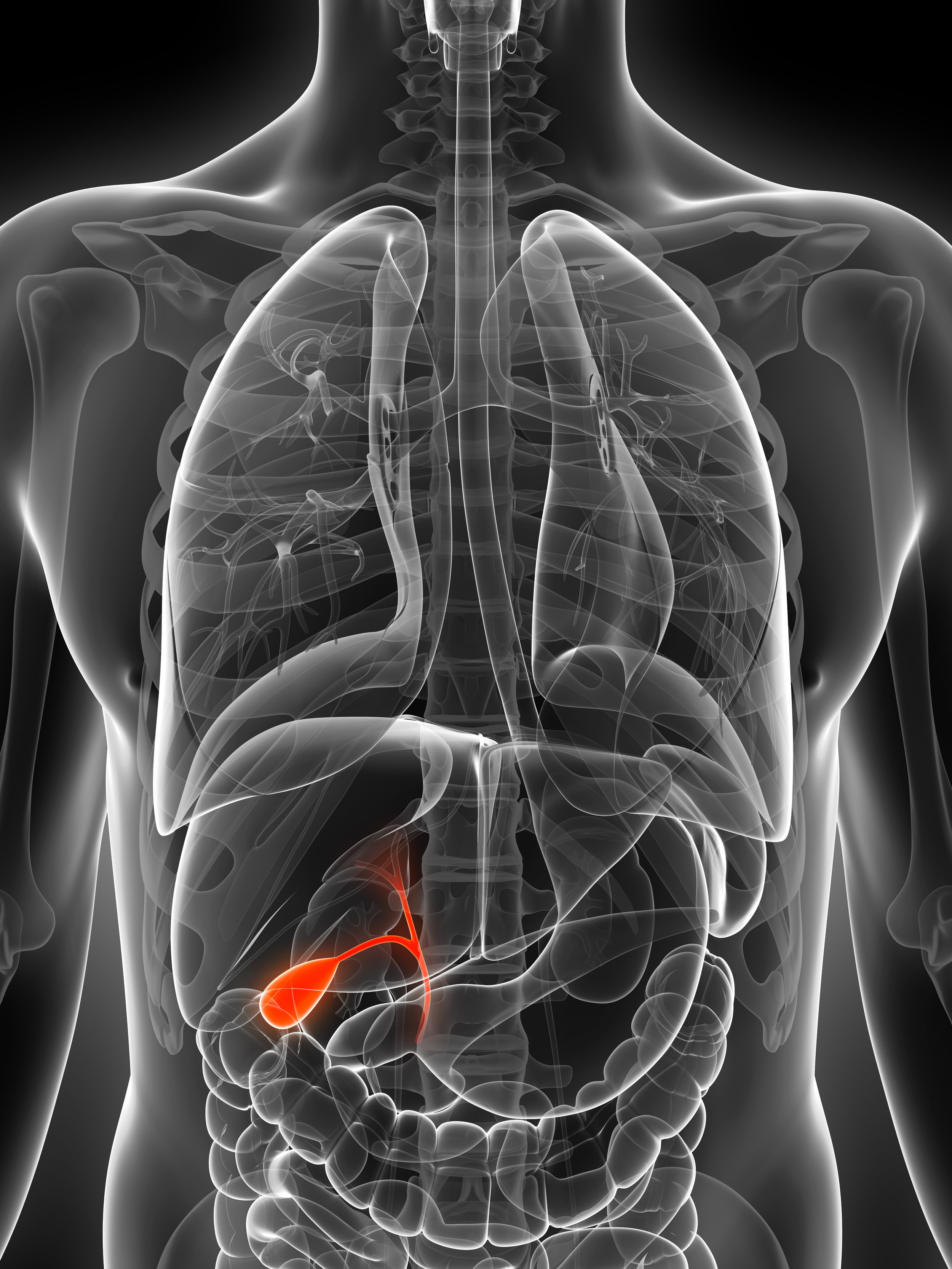
Understanding the “gallbladder” of a technical system allows developers, architects, and hardware engineers to build platforms that are not only fast but resilient. In this deep dive, we will explore how tech infrastructure mimics biological storage, the evolution of caching mechanisms, and how modern AI tools manage the “metabolic” load of massive datasets.
The Biology of Efficiency: Mapping the Gallbladder to System Architecture
To understand what a gallbladder does in the context of technology, we must first look at the concept of asynchronous processing. In the body, the liver produces bile constantly, but the stomach doesn’t always have food to digest. The gallbladder acts as the intermediary storage. In technology, this is the exact role of the Buffer.
The Storage Logic: Concentrating Data for High-Demand Moments
In a software ecosystem, data is often generated at a rate that the primary processing unit (the CPU) or the end-user interface cannot immediately handle. For instance, in video streaming, the “gallbladder” is the pre-loaded segment of the video that sits in your device’s RAM. By concentrating this “bile” (data), the system ensures that when the “fatty meal” (a high-bitrate action scene) arrives, the resources are already staged and ready for deployment. Without this concentrated storage, the system would suffer from latency, much like how the body would struggle with indigestion without concentrated bile.
Just-in-Time Delivery: Why Buffering Prevents System Crashes
The gallbladder’s primary genius is its “Just-in-Time” (JIT) release mechanism. It doesn’t dump all the bile at once; it responds to hormonal signals. Modern tech stacks use similar triggers—interrupts and event-driven architectures—to release stored resources. For a high-traffic e-commerce website during Black Friday, the “gallbladder” is the load balancer and the distributed cache. These systems hold the most requested “nutrients” (product pages and images) and release them only when the demand spikes, preventing the “stomach” (the primary database) from becoming overwhelmed and crashing.
Caching Mechanisms: The Tech World’s Bile Duct
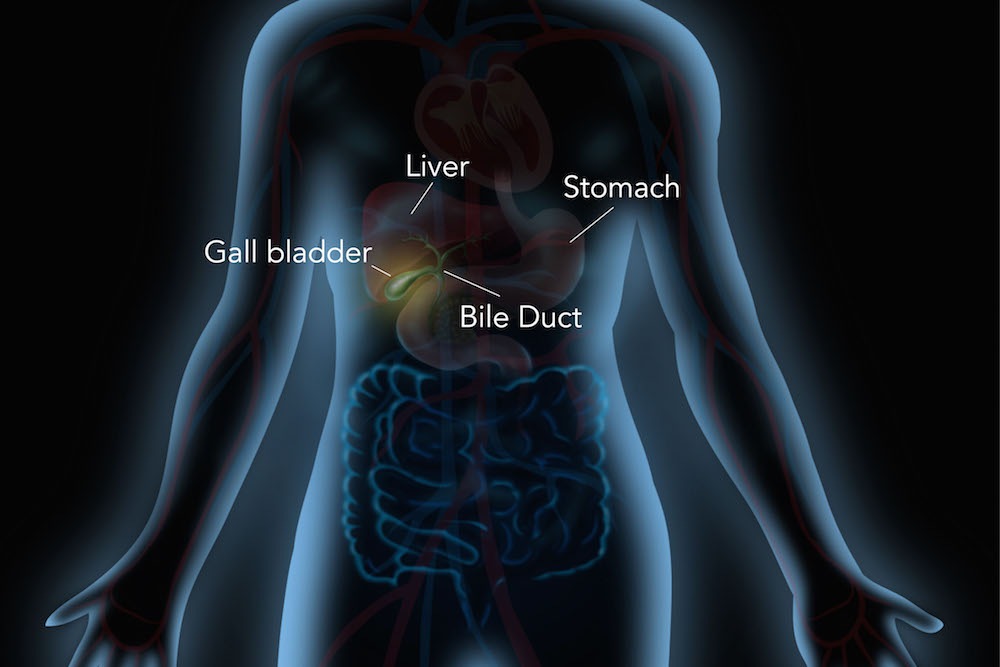
If the gallbladder is the storage unit, the bile duct is the delivery system. In technology, we see this manifest through various layers of caching. Caching is perhaps the most direct technological equivalent to the gallbladder’s function, acting as a high-speed storage layer that sits between the slow, voluminous storage (the liver/HDD) and the active processing unit.
L1, L2, and L3 Caches: Layered Storage for Rapid Retrieval
Inside a computer’s processor, there isn’t just one “gallbladder,” but a hierarchy of them. The L1 cache is the smallest and fastest, providing the CPU with immediate access to essential instructions. As we move to L2 and L3, the capacity increases but the speed slightly decreases. This mimics the body’s ability to store different concentrations of digestive enzymes. Tech professionals must optimize these layers to ensure that the most “expensive” operations (those that take the most time or power) are minimized by keeping frequently used data as close to the “digestive” center as possible.
Content Delivery Networks (CDNs) as Global Gallbladders
On the macro scale of the internet, Content Delivery Networks (CDNs) like Cloudflare or Akamai act as regional gallbladders. Instead of every user requesting data from a central server in Virginia (the liver), the data is “cached” or stored in edge servers closer to the user. This reduces the distance the “bile” must travel. When you click a link in London, you aren’t waiting for a trans-Atlantic data transfer; you are receiving a release of stored data from a local node. This geographical buffering is what allows the modern internet to function without massive systemic lag.
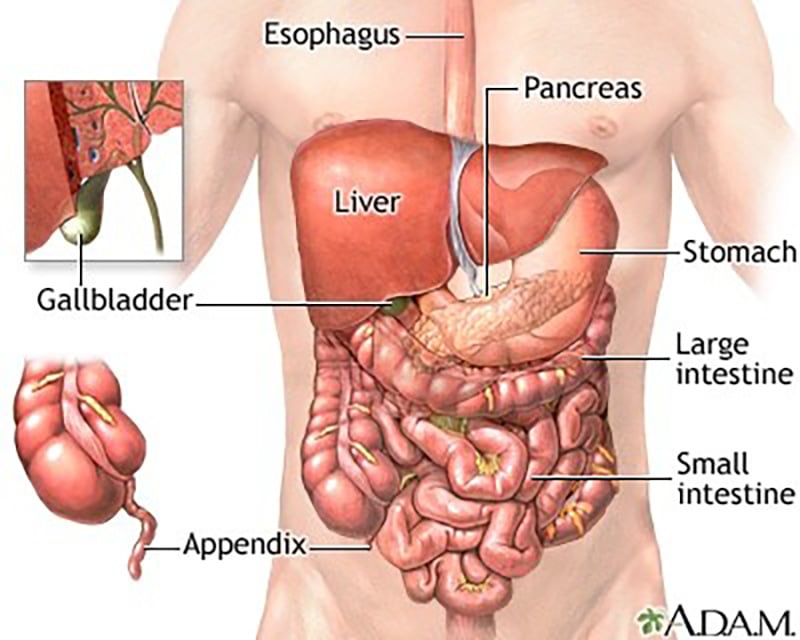
AI and Neural Networks: Managing the Flow of Computational “Digestion”
The rise of Artificial Intelligence (AI) and Large Language Models (LLMs) has introduced a new level of complexity to technological “digestion.” Processing billions of parameters requires a sophisticated understanding of data flow and temporary storage.
Data Pre-processing: Preparing Raw Information for Consumption
Before an AI model can “digest” a dataset, the data must be cleaned and tokenized. This is the tech equivalent of the liver producing bile before it reaches the gallbladder. Modern AI pipelines use “Data Lakes” and “Feature Stores” to hold this pre-processed information. By keeping this data in a specialized state, the AI can perform “inference” (the act of making a prediction or generating text) much faster. If the AI had to start from raw, uncleaned data every time, the “metabolic cost” in terms of electricity and GPU time would be unsustainable.
Memory Management in Large Language Models (LLMs)
In models like GPT-4 or Claude, “context windows” act as a temporary gallbladder. The model stores the immediate history of your conversation in its active memory so it can provide coherent answers. However, just as the gallbladder has a limited capacity, these models have a token limit. Once the “gallbladder” is full, the system must either purge old data or move it to a “long-term memory” solution (like a Vector Database). Tech innovators are currently focused on expanding this “gallbladder capacity” to allow AI to remember thousands of pages of text simultaneously, effectively increasing its digestive efficiency.
Security and Fault Tolerance: When the “Gallbladder” Fails
In medicine, a gallbladder that develops stones or fails can cause significant pain and systemic issues. In the tech world, a failure in the buffering or caching layer can lead to catastrophic system-wide outages and security vulnerabilities.
Buffer Overflows and Security Vulnerabilities
One of the most famous security flaws in tech history is the “Buffer Overflow.” This occurs when a system tries to put more “bile” into the “gallbladder” than it can hold. The excess data spills over into other memory segments, allowing hackers to inject malicious code. Just as a physical blockage causes inflammation, a digital buffer overflow can corrupt the entire operating system. Modern software engineering utilizes “memory-safe” languages like Rust to prevent these overflows, essentially building a more resilient, “unbursting” gallbladder for our digital lives.
Redundancy Strategies: Operating Without a Primary Cache
Sometimes, a tech system must undergo a “cholecystectomy”—the removal of a primary cache for maintenance or due to failure. High-availability systems are designed with “failover” mechanisms. If the primary caching server goes down, the system must know how to route requests directly to the database without causing a total collapse. This often results in slower performance (systemic “indigestion”), but it keeps the business alive. Understanding these architectural trade-offs is a hallmark of senior-level DevOps and Site Reliability Engineering (SRE).
Conclusion: The Vital Role of Specialized Storage in Evolution
The answer to “what does a gallbladder do in your body” is that it provides the efficiency required for high-energy survival. In the tech niche, we have adopted this biological blueprint to manage the explosive growth of data. From the tiny L1 cache in your smartphone’s processor to the massive edge computing nodes that power global streaming services, the principle remains the same: store, concentrate, and release.
As we move toward an era of decentralized computing and even more complex AI, the “gallbladder” of our systems will become even more critical. Engineers are no longer just building faster processors; they are building smarter “storage and release” systems. By mastering the art of the buffer, the tech industry ensures that our digital organisms can digest the massive “fatty” datasets of the future without skipping a beat. Whether it is through optimizing a CDN or securing a memory buffer, the lesson is clear: it’s not just about what you produce, but how you store and deploy it when it matters most.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.