In the biological world, a pinched nerve occurs when too much pressure is applied to a nerve by surrounding tissues, resulting in pain, tingling, numbness, or weakness. In the world of high-performance computing, enterprise software, and global networking, we encounter an almost identical phenomenon. A “pinched nerve” in a tech stack represents a critical bottleneck—a point where data flow is restricted, hardware is throttled, or software logic becomes congested, leading to systemic “pain” in the form of latency, crashes, and degraded user experiences.
As digital ecosystems become increasingly complex, moving from monolithic architectures to microservices and AI-driven processes, the risk of these technical pinched nerves increases. To maintain a healthy digital organism, IT professionals and developers must understand how to diagnose these obstructions and apply the right “treatment” to restore full functionality. This article explores the multifaceted approach to identifying and curing the pinched nerves of the modern technology landscape.
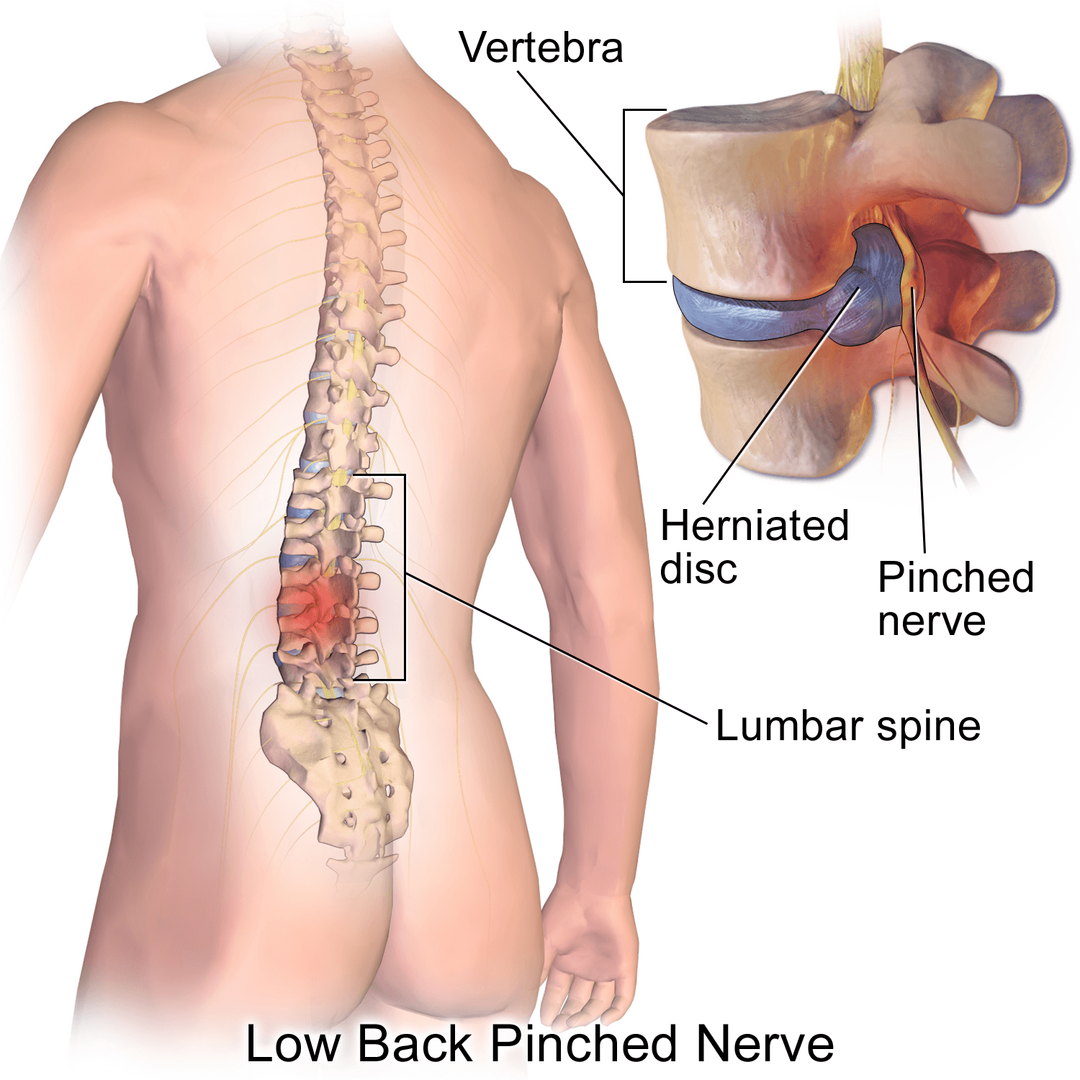
Identifying the Pinched Nerve: Diagnosis of Systemic Bottlenecks
Before a cure can be administered, a precise diagnosis is required. In a complex tech environment, a pinched nerve often manifests as intermittent performance drops that are difficult to pin down. The first step in “treatment” is establishing a robust observability framework that allows engineers to see exactly where the pressure is being applied.
The Silent Performance Killer: Network Congestion and Latency
Just as a physical pinched nerve disrupts the signals between the brain and the limbs, network congestion disrupts the flow of packets between servers and end-users. This is often the most common form of a tech-based pinched nerve. Latency issues frequently arise at the edge of the network or within the “last mile” of delivery.
Diagnosis involves looking at Round Trip Time (RTT) and packet loss metrics. When a network “nerve” is pinched, it is often due to an over-reliance on a single point of failure or a misconfigured router that cannot handle the throughput of modern high-definition data. Curing this requires implementing Content Delivery Networks (CDNs) to distribute the load and using protocols like HTTP/3 to streamline communication.
Hardware Thermal Throttling: When the Physical “Nerve” Fails
Sometimes the “nerve” is literal hardware. When a CPU or GPU is pushed beyond its thermal limits, the system’s firmware initiates “throttling”—artificially slowing down the processor to prevent permanent damage. This is a physical pinched nerve in the infrastructure.
From a technical perspective, this often happens in high-density data centers or poorly ventilated edge computing units. The cure involves advanced cooling solutions—such as liquid cooling or improved airflow management—and the implementation of predictive maintenance sensors that can detect rising temperatures before the system “numbness” (throttling) sets in.
Database Deadlocks and I/O Wait Times
In software architecture, the database is often the central nervous system. A “pinched nerve” occurs here when too many concurrent processes attempt to access the same data row, leading to a deadlock. Similarly, high I/O wait times act as a blockage, where the processor is ready to work but is “waiting” for the storage medium to provide the necessary data. Curing this involves optimizing query execution plans, implementing read-replicas, and shifting to high-speed NVMe storage to alleviate the pressure on data retrieval.
Treating the Source: Software Refactoring and Algorithmic Efficiency
Once the bottleneck is identified, the focus shifts to the “surgery”—the process of refactoring code and optimizing algorithms to ensure that data flows without resistance. In many cases, the pinched nerve is caused by “technical debt,” where old, inefficient code creates friction for new, high-speed features.
Eliminating Technical Debt: The Proactive Cure
Technical debt is the accumulation of “good enough” solutions that eventually become major obstacles. Like scar tissue pressing against a nerve, technical debt restricts the flexibility of a system. To cure this, organizations must commit to regular “refactoring sprints.”
This involves simplifying complex class structures, removing redundant API calls, and ensuring that the codebase follows DRY (Don’t Repeat Yourself) principles. By thinning out the “tissue” of unnecessary code, the system’s core logic can operate with less overhead, effectively decompressing the digital nerve.

Optimizing AI Inference: Reducing the Computational Load
With the rise of Generative AI and Large Language Models (LLMs), a new type of pinched nerve has emerged: inference latency. When a user sends a prompt to an AI, the “nerve” is the time it takes for the model to process the request and return a response. If the model is too large for the available VRAM (Video RAM), the system stutters.
The cure here is found in techniques such as quantization (reducing the precision of the model’s weights to save memory) and pruning (removing unnecessary parameters). By making the model “leaner,” developers can alleviate the computational pressure, allowing for near-instantaneous responses that feel seamless to the end-user.
Asynchronous Processing and Message Queues
One of the most effective ways to cure a pinched nerve in a distributed system is to stop trying to do everything at once. Synchronous processing, where one task must finish before the next begins, is a recipe for congestion. By implementing asynchronous processing via message queues like RabbitMQ or Apache Kafka, developers can “decompress” the system. This allows tasks to be handled in the background, ensuring that the user-facing “nerve” remains responsive even while heavy lifting occurs behind the scenes.
The Role of Cloud Orchestration in Alleviating Infrastructure Pressure
In the modern era, the “body” of our tech stack often lives in the cloud. Cloud orchestration tools like Kubernetes serve as the chiropractor for digital infrastructure, constantly adjusting and realigning resources to ensure that no single component is being “pinched” by excessive demand.
Auto-scaling as a Dynamic Decompression Method
Manual scaling is reactive and often too slow to prevent a system crash. Auto-scaling, however, acts as a dynamic cure. When a specific service experiences a spike in traffic—applying pressure to the CPU and memory—the orchestration layer automatically spins up new “nodes” or containers to share the load. This effectively spreads the pressure across a wider surface area, preventing any single point from becoming a “pinched nerve” that brings down the entire application.
Multi-Cloud Strategies: Distributing the Load to Prevent Failure
Relying on a single cloud provider (like AWS, Azure, or Google Cloud) can lead to a systemic pinched nerve if that provider experiences a regional outage. A multi-cloud strategy ensures that the “nervous system” of a business is distributed. If one path is blocked, the traffic can be rerouted through another provider’s infrastructure. While this adds complexity, it provides the ultimate safeguard against the kind of total system paralysis that occurs when a primary infrastructure nerve is severed.
Microservices vs. Monoliths: Segmenting the Nervous System
In a monolithic architecture, a single bug can act as a pinched nerve that affects the entire body of the application. By moving to a microservices architecture, organizations segment their “nerves.” If the payment processing service is experiencing high latency (a “pinch”), the search and browsing services remain unaffected. This isolation ensures that localized pain does not lead to systemic failure, allowing for targeted “treatment” of the specific service in distress.
Preventive Care: Building Resilient and Elastic Architectures
The best way to cure a pinched nerve is to prevent it from ever occurring. In technology, this means moving away from reactive fixes and toward a culture of “resiliency by design.” This involves building systems that are not only strong but elastic—capable of bending under pressure without breaking.
Chaos Engineering: Testing for “Pinched Nerves” Before They Occur
Chaos Engineering, a discipline popularized by Netflix, involves intentionally introducing failures into a system to see how it responds. By “pinching the nerve” on purpose in a controlled environment—such as shutting down a server or injecting network latency—engineers can identify weaknesses before they cause a real-world outage. This proactive approach allows teams to build “calluses” and redundancies that make the system immune to common stresses.
Monitoring and Observability: The Digital Nervous System
You cannot fix what you cannot see. Modern observability goes beyond simple “up/down” monitoring. It involves deep tracing, where every single request is tracked as it moves through various microservices. Tools like Datadog, New Relic, or Prometheus act as the sensory receptors of the digital nervous system. They provide the real-time feedback necessary to see where pressure is building, allowing for “preventive adjustments” before the user ever feels the effects of a pinched nerve.
The Human Element: Training and Documentation
Finally, the “cure” for many tech bottlenecks is often human. When a system fails, the speed of recovery depends on the “muscle memory” of the DevOps team. Clear documentation, automated runbooks, and regular training ensure that when a pinched nerve is detected, the response is swift and accurate. The human element is the final layer of the digital nervous system, providing the cognitive oversight needed to manage increasingly autonomous and complex tech stacks.
In conclusion, a “pinched nerve” in technology is an inevitable byproduct of growth and complexity. However, by employing a combination of advanced diagnostic tools, algorithmic optimization, cloud orchestration, and proactive testing, organizations can ensure that their digital systems remain fluid, responsive, and resilient. Just as physical health requires constant attention and adjustment, the health of a tech stack requires a commitment to removing the “pinches” that hinder performance and innovation.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.