In the rapidly evolving landscape of artificial intelligence and machine learning, technical terminology often acts as a barrier to deeper understanding. Among these terms, “logits” stands out as a fundamental concept that bridges the gap between raw mathematical computations and the intuitive predictions we see in modern AI applications. Whether you are interacting with a Large Language Model (LLM) like GPT-4 or utilizing computer vision to categorize images, logits are the silent engine driving the decision-making process.
To understand logits is to understand how a machine “thinks” before it translates its internal logic into human-readable probabilities. In this technical deep dive, we will explore the mathematical foundations of logits, their role in neural network architectures, and why they are indispensable for the development of modern software and AI tools.

The Mathematical Foundation: From Linear Algebra to Neural Outputs
At its core, a neural network is a sophisticated mathematical function that maps inputs to outputs through layers of interconnected “neurons.” Each neuron performs a weighted sum of its inputs and passes the result through an activation function. However, the final layer of a classification network behaves differently.
Defining the Logit Function
The term “logit” originates from the field of statistics, specifically as a shorthand for “logistic unit.” Mathematically, the logit function is the inverse of the standard logistic function (also known as the sigmoid function). If we consider a probability p (where p is between 0 and 1), the logit of p is defined as the natural logarithm of the odds ratio:
logit(p) = ln(p / (1 - p))
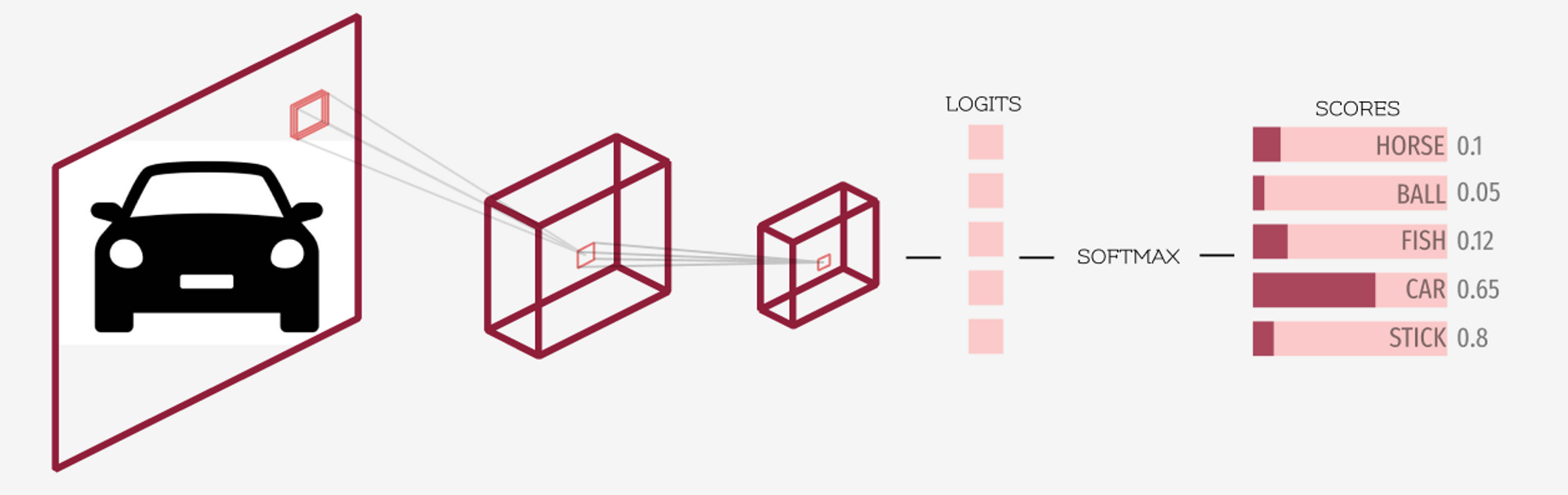
In the context of deep learning, however, the definition shifts slightly. Here, “logits” refers to the vector of raw, unnormalized scores produced by the last layer of a neural network. These scores are the result of the final linear transformation—multiplying the weights by the previous layer’s activations and adding a bias—before any normalization or probability mapping occurs.
The Log-Odds Connection
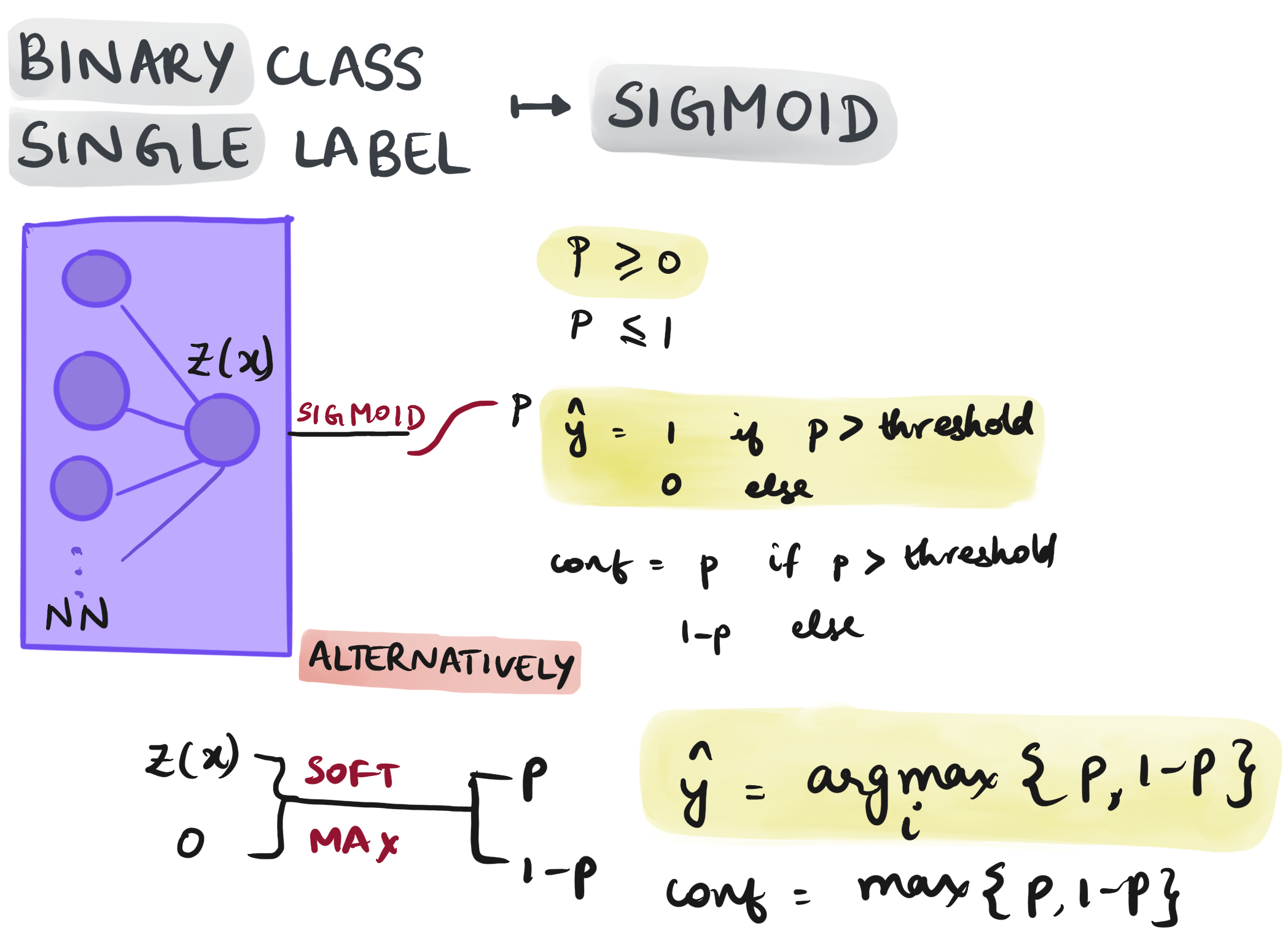
To grasp why these raw scores are called logits, one must look at the “log-odds.” In binary classification, the network tries to predict the likelihood of an event occurring versus not occurring. The “odds” of an event is the ratio of the probability of success to the probability of failure. By taking the logarithm of these odds, we map a probability range of [0, 1] to a real number range of [-∞, +∞].
This infinite range is critical for the optimization process. During the training phase, a neural network uses gradient descent to adjust its weights. If the network were forced to output values strictly between 0 and 1 at every step, the gradients would become extremely small as the output approached the boundaries, leading to the “vanishing gradient” problem. Logits allow the network to express its “confidence” on an open-ended scale, making the mathematical optimization much more stable.
The Role of Logits in Machine Learning Architecture
In a standard classification pipeline, the movement of data is a one-way street from input to output. Logits represent the final stop of internal computation before the data is formatted for human consumption or loss calculation.
The Hidden Layer Pipeline
Before reaching the logit stage, data passes through several hidden layers. In a convolutional neural network (CNN) used for image recognition, these layers extract features—edges, textures, shapes, and finally complex objects. By the time the data reaches the final fully connected layer, it has been transformed into a high-dimensional feature vector.
The final layer’s job is to distill these features into a set of scores for each possible class. If you are training a model to distinguish between “Cat,” “Dog,” and “Bird,” the final layer will produce three distinct numbers. These three numbers are your logits. They are not probabilities; they can be negative, and they do not sum to one. They simply represent the raw evidence the model has found for each category.
The Final Layer: Why Raw Scores Matter
For developers and data scientists, working directly with logits is often more beneficial than working with probabilities. When calculating “loss”—the measure of how far off a model’s prediction is from the truth—most frameworks (like PyTorch or TensorFlow) prefer logits.
The standard loss function for classification is Cross-Entropy Loss. When this function is calculated using logits rather than probabilities, it is more numerically stable. This is because the mathematical combination of the log-sum-exp trick and the cross-entropy formula avoids the precision errors that occur when dealing with very small floating-point numbers (probabilities close to zero).
Transitioning from Logits to Probabilities: Softmax and Beyond
While logits are perfect for machines, they are unintuitive for humans. If a model says the logit for “Cat” is 8.2 and the logit for “Dog” is 1.5, we know it prefers the cat, but we don’t know by how much. To solve this, we use the Softmax function.
The Softmax Transformation
The Softmax function acts as a bridge. It takes the vector of logits and transforms them into a probability distribution. It does this by exponentiating each logit (making it positive) and then dividing it by the sum of all exponentiated logits.
The result is a set of values that:
- Are all between 0 and 1.
- Sum up exactly to 1 (or 100%).
In our previous example, the logit of 8.2 would likely translate to a probability of over 99%, while 1.5 would represent a fraction of a percent. This normalization is what allows an AI tool to tell a user, “I am 99% certain this image is a cat.”
Why We Don’t Stop at Logits
If logits are so great for training, why do we bother with the conversion? Beyond human readability, probabilities are necessary for “decision thresholds.” In digital security, for instance, an AI-powered firewall might flag an IP address as “malicious” only if the probability exceeds a specific threshold (e.g., 95%). Logits are too abstract for this type of logic-gating; probabilities provide a standardized metric for risk assessment and automated action.
Practical Applications and Challenges in Modern AI
In the era of Generative AI and Large Language Models, the concept of logits has moved from the back-end of research papers to the front-end of developer APIs.
Large Language Models (LLMs) and Token Sampling
When you prompt an AI like ChatGPT, the model doesn’t just “pick” a word. It generates a logit score for every single word (token) in its massive vocabulary—often 50,000 to 100,000 words. These logits represent how likely each word is to come next in the sentence.
Modern AI tools allow developers to manipulate these logits using a parameter called Temperature.
- A low temperature (e.g., 0.2) makes the model more deterministic by sharpening the logit distribution. The highest logit becomes much more likely to be picked, resulting in factual, repetitive text.
- A high temperature (e.g., 0.8 or 1.2) flattens the distribution. The gap between the top logit and the others shrinks, allowing the model to take “creative risks” by picking less likely tokens.
Calibration and Temperature Scaling
A major challenge in current AI trends is “overconfidence.” Often, a model will produce a very high logit for an incorrect answer. This is a failure of calibration. Developers use techniques like Temperature Scaling—a post-processing step—to divide the logits by a constant before applying Softmax. This doesn’t change which class is the winner, but it softens the probability, ensuring that the model’s confidence level more accurately reflects its actual accuracy rate.
Why Understanding Logits is Crucial for Developers
For anyone building software in the 21st century, understanding the “raw scores” of AI is no longer optional. As we move toward more complex AI integrations—such as autonomous agents and real-time security scanners—the ability to interpret and manipulate logits allows for finer control over system behavior.
Logits provide the “why” behind the “what.” By examining logits, developers can debug models to see if they were “torn” between two categories or if they were confidently wrong. In the realm of digital security, analyzing logit variance can even help detect “adversarial attacks,” where an attacker slightly modifies an input to trick a model. If the logits for a “safe” file are unusually close to the logits for “malware,” it may indicate a sophisticated bypass attempt.
In conclusion, logits are the raw, unvarnished thoughts of a machine. They are the mathematical expression of uncertainty and evidence. By mastering this concept, tech professionals can better navigate the transition from traditional software logic to the probabilistic world of artificial intelligence, building tools that are not only powerful but also nuanced and reliable.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.