The intersection of biotechnology and information technology has transformed the way we perceive our own biological blueprints. A decade ago, a DNA test result might have been delivered as a static PDF or a physical packet of laboratory notes. Today, when we ask what DNA test results look like, we are really asking about the state of high-level data visualization, bioinformatics, and secure software interfaces.
In the modern tech ecosystem, DNA results are no longer just medical findings; they are dynamic, interactive data assets. They represent a sophisticated synthesis of raw genomic sequencing and cloud-based algorithmic interpretation. For the technologist and the curious consumer alike, understanding these results requires looking past the biology and into the digital architecture that makes the invisible visible.
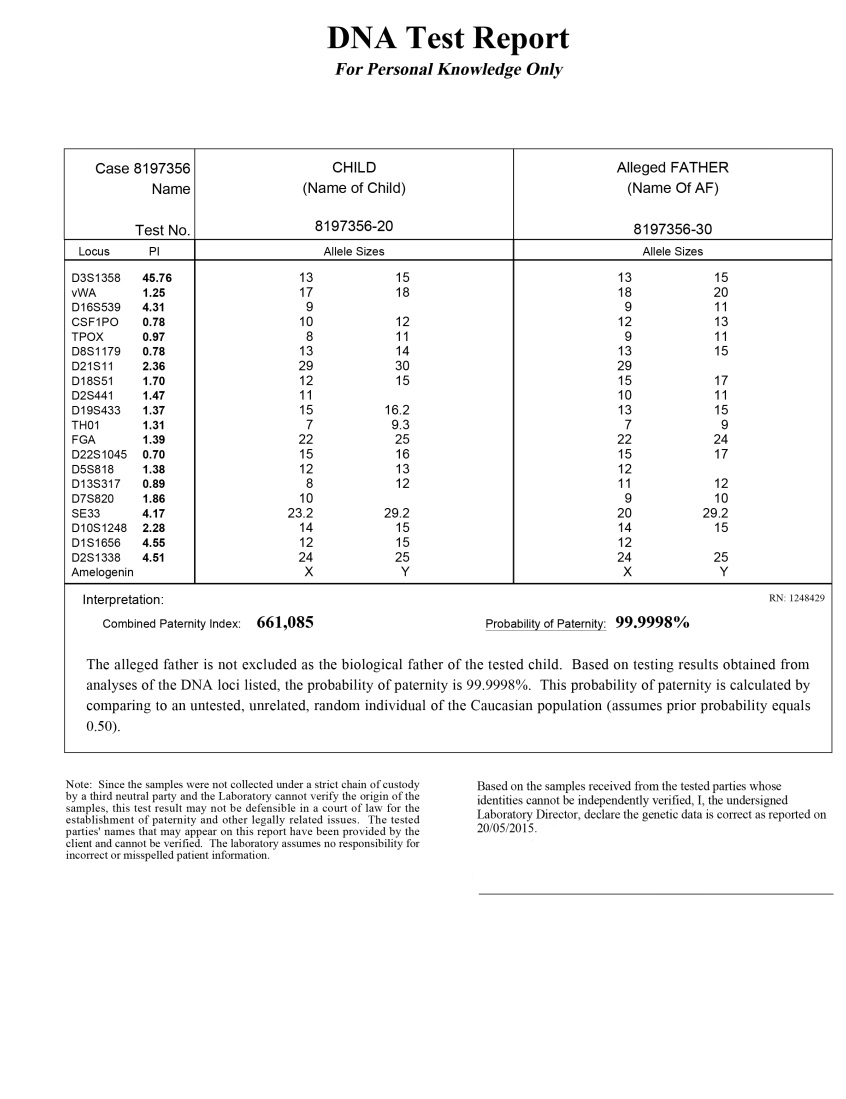
1. The Raw Data Layer: From Biological Samples to Binary Code
To understand what DNA results look like, one must first understand the “back-end” of the process. What begins as a biological sample (saliva or blood) is quickly converted into a massive digital dataset. This is the foundation upon which all user-facing interfaces are built.
From Sequencing to Digital Strings
The core of a DNA test result is the “Raw Data.” Once a laboratory completes Next-Generation Sequencing (NGS) or SNP (Single Nucleotide Polymorphism) genotyping, the biological markers are converted into text-based files. In their most primitive form, these results look like endless strings of the letters A, C, G, and T. For a developer or a bioinformatician, this data often resides in formats such as FASTQ (raw sequences), BAM (aligned sequences), or VCF (Variant Call Format). These files can be several gigabytes in size, representing the raw computational power required to map a human genome.
The Role of Bioinformatic Pipelines
Before a user sees a single pie chart, the raw data must pass through a bioinformatic pipeline. These pipelines are software suites that use reference genomes to identify variations. When you look at your results, you are viewing the output of complex algorithms that have compared your 700,000+ genetic markers against global databases. This process—known as “calling” variants—is where the transition from “data” to “insight” begins.
Data Portability and the .TXT Format
Many consumer tech platforms allow users to download their “raw data.” In this context, the result looks like a simple tab-delimited text file. It typically contains columns for the RSID (Reference SNP cluster ID), the chromosome number, the specific position on that chromosome, and the genotype (the specific pair of alleles you carry). While unreadable to the average person, this digital file is the “source code” of the individual, capable of being uploaded into various third-party AI tools for further analysis.
2. Data Visualization and the User Interface (UI)
The “front-end” of DNA test results is where technology meets storytelling. Modern genomic platforms invest heavily in UI/UX design to ensure that complex statistical probabilities are presented in an intuitive, digestible format.
Interactive Geographic Dashboards
One of the most recognizable features of DNA results is the ethnicity breakdown. From a tech perspective, this is a masterpiece of data visualization. Results usually look like a multi-layered interactive map. These interfaces utilize SVG (Scalable Vector Graphics) and heat maps to show regional concentrations. Users can zoom into specific coordinates, where the software dynamically adjusts the “confidence intervals.” This is not just a static image; it is a real-time rendering of a user’s genetic proximity to reference populations.
Health and Trait Visualization
For health-related DNA results, the interface shifts toward risk modeling and comparative analytics. Instead of maps, results look like a series of cards or dashboards. These displays often use color-coded scales—ranging from “typical” to “increased” risk—to communicate polygenic risk scores. The tech behind this involves complex data modeling, where the software calculates the user’s percentile compared to a broader dataset. These results are often interactive, allowing users to toggle between different environmental factors to see how their genetic predisposition might interact with lifestyle choices.
The “Genetic Tree” and Graph Theory
When DNA tests are used for relative matching, the results utilize graph theory to visualize connections. Most platforms present a “DNA Relatives” list, which is essentially a sorted database view. However, the more advanced features include “Relationship Path” visualizations. These look like nodes and edges in a network graph, illustrating how two individuals share segments of Identical By Descent (IBD) DNA. The software calculates “centimorgans” (a unit of genetic linkage) to programmatically determine the likely branch on a family tree.
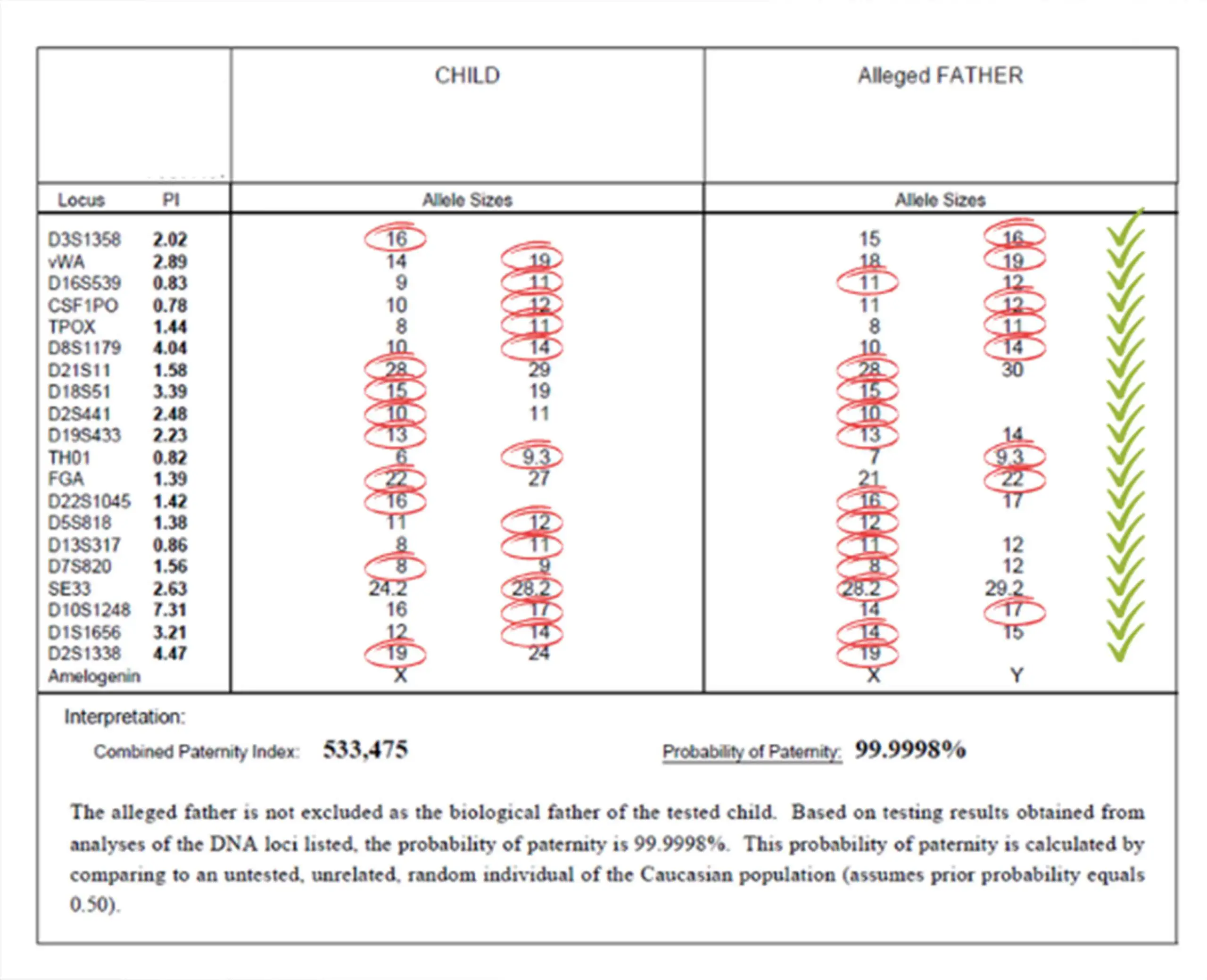
3. The Role of AI and Machine Learning in Interpretation
The most profound shift in what DNA results “look like” is the move from descriptive data to predictive insights. This transition is powered almost entirely by Artificial Intelligence (AI) and Machine Learning (ML).
Pattern Recognition in Ancestry
Ancestry results are not fixed; they evolve as the underlying machine learning models improve. When a company updates its “DNA breakdown,” the user’s results change. This is because the AI has been retrained on a larger reference panel, allowing for more granular classification. In this sense, a DNA result looks like a “living document”—a version-controlled dataset that is updated as the platform’s algorithms become more sophisticated.
Predictive Trait Modeling
AI is also used to predict phenotypic traits—how you look or behave—based on your genotype. Modern results include sections that look like a “Genetic Profile,” predicting everything from your likelihood of hair loss to your preference for cilantro. These predictions are the result of training models on millions of phenotypes and genotypes. The software presents a “probability score,” which is a classic example of probabilistic computing being brought to the consumer market.
Sorting the Noise: The Algorithmic Filter
The human genome is massive, and much of it is “noise” in the context of commercial testing. The software’s primary job is to act as a filter. What the user finally sees is a curated subset of data that has been filtered for significance. Behind the scenes, the tech is performing billions of comparisons to ensure that the “matches” and “risks” presented are statistically significant, reducing the “false discovery rate” that can plague raw genomic analysis.
4. Security, Privacy, and the Digital Vault
Because DNA data is the most sensitive form of PII (Personally Identifiable Information), what DNA results look like from a security perspective is a fortress of encryption and decentralized protocols.
Data Encryption and Hashing
When you access your results online, you are looking at data that is typically encrypted “at rest” and “in transit.” From a technical standpoint, your results look like an encrypted hash. Top-tier genomic companies use AES-256 encryption and follow strict HIPAA-compliant protocols. Even the developers of the platform often cannot see the link between a user’s name and their genetic markers; the two are “de-identified” and stored in separate database silos.
Blockchain and Personal Data Ownership
A new trend in the DNA tech space is the use of blockchain technology to house results. In these ecosystems, a DNA result looks like a private key or a digital asset on a ledger. This allows users to grant temporary “smart contract” access to researchers or doctors without ever giving up ownership of the underlying data. This shift transforms DNA results from a service provided by a company into a digital sovereign asset owned by the individual.
API Integrations and the Ecosystem
Finally, modern DNA results look like an “integratable API.” Many platforms now allow users to “Sign in with DNA” or export their data to third-party apps for fitness, nutrition, or pharmaceutical research. This interoperability means that your genetic results can be “called” by other software tools to customize your experience in a variety of digital environments, from personalized workout apps to precision medicine portals.

Conclusion: The Biological API
In summary, what DNA test results look like depends entirely on the lens through which you view them. To the average user, they look like a beautifully designed, interactive web application filled with maps, charts, and social connections. To the data scientist, they look like high-throughput sequencing files and VCF outputs. To the security expert, they look like an encrypted, de-identified vault of high-value information.
As we move further into the era of personalized technology, DNA results will become increasingly integrated into our digital lives. They are no longer a one-time report, but a dynamic, evolving stream of data. The future of genomics is not just in the lab; it is in the software, the interface, and the algorithms that translate our biological essence into the digital language of the 21st century.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.