In the modern enterprise landscape, the network is the central nervous system of every operation. From cloud-based applications and remote collaboration tools to internal databases and customer-facing portals, the seamless flow of data is what keeps a business alive. However, as networks grow in complexity—spanning multi-cloud environments, hybrid infrastructures, and thousands of IoT devices—the risk of failure increases. This is where network monitoring comes into play. It is not merely a reactive measure to fix things when they break; it is a proactive, strategic discipline designed to ensure the continuous health, performance, and security of a digital ecosystem.

Network monitoring is the consistent process of overseeing a computer network using specialized software tools. These tools track various metrics, such as bandwidth usage, server health, and traffic patterns, to identify bottlenecks or failures before they impact the end-user. By providing deep visibility into every packet and port, network monitoring allows IT teams to maintain an optimal state of operation.
The Mechanics of Network Monitoring: How It Works
To understand network monitoring, one must first understand how data is gathered from diverse hardware and software components. A network monitoring system (NMS) interacts with devices like routers, switches, firewalls, and servers to pull real-time data. This interaction generally happens through established protocols that act as a common language between the monitoring tool and the infrastructure.
Protocols and Data Collection
The most prevalent protocol in this space is the Simple Network Management Protocol (SNMP). Most networking hardware comes “SNMP-ready,” allowing the monitoring tool to query the device for status updates, such as CPU utilization or interface errors. Beyond SNMP, Internet Control Message Protocol (ICMP)—commonly known as “pinging”—is used to verify the availability of a device. If a device stops responding to pings, the monitoring system triggers an alert.
For more granular insights into traffic patterns, many professionals use flow-based protocols like NetFlow, J-Flow, or sFlow. These protocols don’t just tell you if a device is “up”; they tell you who is using the bandwidth, which applications are consuming the most resources, and where potential congestion is forming.
Monitoring Architecture: Agent-Based vs. Agentless
When implementing a monitoring strategy, tech teams must choose between agent-based and agentless architectures. Agent-based monitoring requires the installation of a small piece of software (the agent) on the target device. This allows for deep, specialized data collection, often including internal application metrics. Agentless monitoring, conversely, relies on built-in management protocols to observe the device from the outside. While agentless systems are easier to deploy and maintain, agent-based systems often provide the high-resolution data required for mission-critical servers.
The Role of Packet Sniffing
While protocol-based monitoring looks at the “metadata” of the network, packet sniffing involves capturing and inspecting the actual data packets traveling across the wire. This is the deepest level of monitoring, used primarily for troubleshooting complex performance issues or investigating security breaches. It allows engineers to see exactly what is happening within a transaction, identifying latency at the microsecond level.
Core Benefits: Why Proactive Surveillance is Essential
In a “tech-first” world, the cost of network downtime can reach thousands of dollars per minute. Beyond the immediate financial impact, network instability erodes customer trust and employee productivity. Network monitoring transforms IT from a “firefighting” department into a value-driven center of excellence.
Minimizing Downtime and Maximizing Performance
The primary goal of network monitoring is the reduction of Mean Time to Repair (MTTR). By providing real-time alerts, the system ensures that IT staff are notified the moment a metric deviates from the baseline. In many cases, modern tools can identify “silent failures” or “gray failures”—situations where a device is technically online but performing so poorly that it is functionally useless. By catching these issues early, organizations can reroute traffic or swap hardware before a total blackout occurs.
Strengthening Cybersecurity Posture
While network monitoring is often categorized under “performance,” it is an indispensable pillar of digital security. Many cyberattacks, such as Distributed Denial of Service (DDoS) attacks or data exfiltration attempts, manifest as unusual spikes in network traffic. An effective monitoring system establishes a “baseline” of normal behavior. When an anomaly occurs—such as a server suddenly sending gigabytes of data to an unrecognized external IP address—the system flags it immediately. This allows security teams to isolate compromised segments of the network before a breach spreads.

Capacity Planning and Resource Optimization
Tech infrastructure is expensive. Without network monitoring, companies often fall into the trap of “over-provisioning”—buying more bandwidth or hardware than they actually need just to be safe. Monitoring provides historical data that shows exactly how much capacity is being used. This data allows for informed decision-making regarding upgrades. If a 10Gbps link is only hitting 20% utilization during peak hours, the company can defer expensive upgrades. Conversely, if growth trends show a steady 10% increase month-over-month, the IT department can proactively budget for expansion.
Essential Features of Modern Monitoring Tools
Not all monitoring tools are created equal. As we move into the era of software-defined networking (SDN) and the “Internet of Things” (IoT), the requirements for an NMS have evolved. Today’s tools must be as dynamic as the networks they oversee.
Real-Time Visualization and Dashboards
Data is only useful if it is interpretable. Modern network monitoring tools offer sophisticated “Single Pane of Glass” dashboards. these provide a high-level overview of the entire network’s health through color-coded maps and graphs. Visualization helps technicians quickly spot geographical patterns; for example, if all reported issues are originating from a specific branch office, the problem likely lies with a local ISP rather than a central server.
Intelligent Alerting and Thresholds
The bane of any IT professional’s existence is “alert fatigue.” If a system sends 500 emails for every minor fluctuation, the important alerts will eventually be ignored. Intelligent monitoring tools utilize dynamic thresholds. Instead of a static “alert if CPU > 90%,” they use machine learning to understand that 90% usage might be normal during a Friday afternoon backup but highly unusual at 3:00 AM on a Tuesday. By reducing noise, these tools ensure that when an alarm sounds, it actually requires human intervention.
Automated Discovery and Mapping
In the age of virtualization, networks change hourly. New virtual machines are spun up, and containers are deployed and destroyed. Manual inventory management is impossible. Advanced network monitoring solutions feature “Auto-Discovery,” which constantly scans the network for new devices. Once a device is found, the system automatically adds it to a topology map, showing how it is interconnected with other assets. This visual representation is crucial for understanding “dependency chains”—knowing that if Switch A fails, it will take down Servers B, C, and D.
Best Practices for Implementing a Monitoring Strategy
Buying the most expensive software on the market does not guarantee a healthy network. Success lies in how the technology is implemented and integrated into the broader IT workflow.
Defining Critical Metrics and KPIs
A common mistake is trying to monitor everything at once. This leads to information overload. Tech leaders should identify Key Performance Indicators (KPIs) that align with their specific needs. Common metrics include:
- Latency: The time it takes for data to travel from source to destination.
- Jitter: Variation in packet delay, which is critical for VoIP and video conferencing.
- Packet Loss: The percentage of data packets that fail to reach their destination.
- Bandwidth Utilization: The percentage of available network capacity currently in use.
Establishing an Escalation Matrix
Monitoring is only effective if there is a clear plan for when an alert is triggered. An escalation matrix defines who is responsible for different types of failures. A minor latency issue might trigger a ticket for the junior network admin, while a “Core Switch Down” alert might trigger an automated phone call to the Head of Infrastructure. By automating the notification process based on severity, organizations ensure a faster response time.
Future-Proofing with AIOps
The next frontier of network monitoring is Artificial Intelligence for IT Operations (AIOps). As networks become too large for humans to monitor manually, AI-driven tools are stepping in to provide “predictive analytics.” These systems can analyze years of historical data to predict when a hard drive is likely to fail or when a specific network link will reach its breaking point. Moving from proactive monitoring to predictive monitoring is the ultimate goal for any modern tech department, as it allows for maintenance to be scheduled during planned windows, virtually eliminating emergency outages.
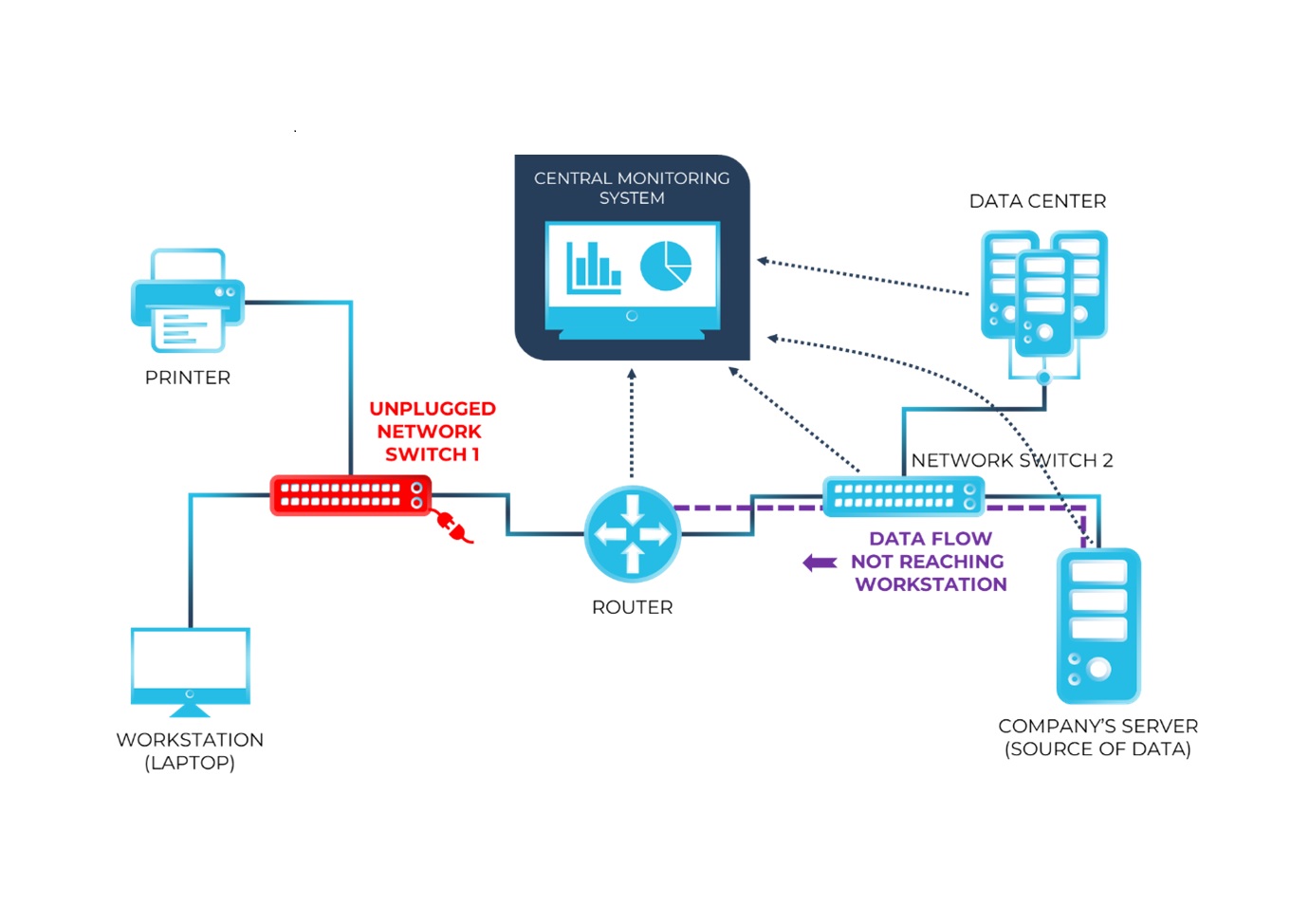
Conclusion
Network monitoring is no longer a luxury reserved for giant corporations with massive data centers. In an era where every business is essentially a technology business, the ability to see, analyze, and optimize network traffic is a fundamental requirement. By implementing robust monitoring protocols, focusing on intelligent alerting, and leveraging the latest in AI-driven analytics, organizations can ensure their digital infrastructure remains resilient, secure, and ready for future growth. The network is the backbone of the modern enterprise; monitoring is the pulse check that ensures that backbone remains strong.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.