In the rapidly evolving landscape of technology, particularly within the realms of Artificial Intelligence (AI) and Data Science, the ability to predict outcomes is not just a mathematical curiosity—it is a foundational requirement. At the heart of predictive modeling, machine learning, and algorithmic efficiency lies a fundamental concept of probability: the Sample Space.
To the uninitiated, probability might seem like a series of guesses. However, in tech, probability is a rigorous framework used to manage uncertainty. Understanding the sample space is the first step in building robust software systems, securing digital networks, and training neural networks that can drive autonomous vehicles or generate human-like text.
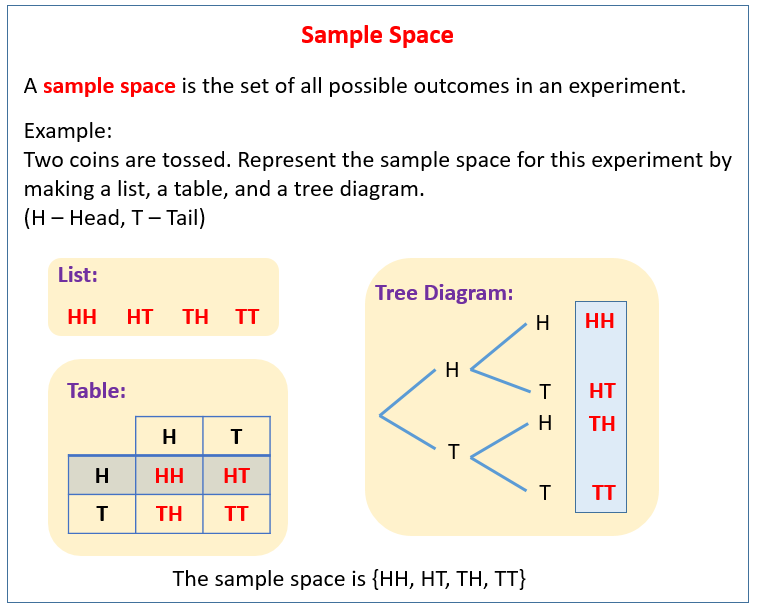
Defining the Foundation: What is Sample Space in Modern Tech?
In the context of probability theory, a sample space (often denoted by the symbol S or Ω) is the set of all possible outcomes of a random experiment or process. When we translate this into the tech world, an “experiment” could be anything from a user clicking a button on a website to a server receiving a packet of data or an AI model predicting the next word in a sentence.
The Core Definition of a Sample Space
Mathematically, if you are tossing a coin, the sample space is {Heads, Tails}. If you are rolling a six-sided die, it is {1, 2, 3, 4, 5, 6}. In software engineering, if you are testing a Boolean function, the sample space is {True, False}. The sample space must be “collectively exhaustive,” meaning it includes every possible result, and “mutually exclusive,” meaning only one outcome can happen at a time during a single trial.
For developers and data scientists, identifying the sample space is the “scoping” phase of a project. Before you can write an algorithm to handle data, you must understand the universe of possible values that data can inhabit.
Discrete vs. Continuous Sample Spaces
In technology, we categorize sample spaces into two main types:
- Discrete Sample Spaces: These contain a finite or countably infinite number of outcomes. For example, the number of users logged into a server (0, 1, 2…) or the possible HTTP status codes (200, 404, 500).
- Continuous Sample Spaces: These contain an uncountably infinite number of outcomes, usually representing measurements. For example, the exact latency of a network request in milliseconds (e.g., 12.453… ms) or the voltage levels in a hardware sensor.
Understanding this distinction is critical for choosing the right tech stack. For instance, discrete outcomes are often handled via classification algorithms, while continuous outcomes require regression models.
Why Sample Space Matters in Software Engineering and AI
The sample space is not merely a theoretical construct; it is a practical blueprint for building intelligent systems. When we move from simple mathematics to complex software architecture, the sample space dictates how we handle logic and edge cases.
Powering Machine Learning Algorithms
Machine Learning (ML) is essentially the study of patterns within a sample space. When you train a model to recognize images of cats versus dogs, the sample space consists of every possible configuration of pixels in a given resolution. The model’s job is to partition this massive sample space into regions: “This region of pixel configurations likely represents a cat, and this region represents a dog.”
If the sample space is poorly defined—for example, if you haven’t accounted for “neither cat nor dog” outcomes—the model will struggle with “Out-of-Distribution” (OOD) data. This is why data scientists spend significant time on feature engineering, which is essentially the process of refining the sample space to make it more manageable for the algorithm.
Risk Assessment in Digital Security
In cybersecurity, probability and sample spaces are used to model threats. A digital security system must evaluate the sample space of “log-in attempts.” Outcomes within this space might include “Authorized User,” “Typo by Authorized User,” “Brute Force Attack,” or “Stolen Credential Usage.”
By defining this sample space, security engineers can apply Bayesian probability to determine the likelihood of an ongoing attack. If a system sees a sequence of outcomes that falls into the “Brute Force” region of the sample space, it can trigger an automated lockout. Without a clear understanding of the possible outcomes, an AI-driven security tool would be unable to distinguish between a busy Monday morning and a distributed denial-of-service (DDoS) attack.
Mapping the Sample Space in Data Analysis

For data analysts and business intelligence (BI) professionals, the sample space serves as the boundary for data visualization and interpretation. If you don’t know what is possible, you cannot identify what is significant.
Visualizing Outcomes with Decision Trees
Decision trees are popular tools in both tech management and software logic. Each node in a decision tree represents a choice or a random event, and the branches represent the outcomes. The sum total of all terminal nodes (leaves) effectively represents the sample space for that specific process.
In tech tutorials and documentation, mapping out these trees helps developers visualize the state-space of an application. For example, in a fintech app, the sample space for a transaction might be {Success, Insufficient Funds, Timeout, Flagged for Fraud, User Cancelled}. Visualizing this allows engineers to ensure that the “catch-all” logic in their code accounts for every single possibility, preventing the dreaded “unhandled exception.”
Set Theory and Its Role in Database Management
The mathematical language used to describe sample spaces is set theory. This is the same logic used in SQL queries and NoSQL database filtering. When you perform a “JOIN” between two tables, you are essentially defining a new sample space based on the intersection or union of two existing sets of data.
Advanced data tools like Apache Spark or Google BigQuery rely on set-based logic to process petabytes of information. By understanding the sample space of a dataset, data engineers can optimize queries to ignore irrelevant “outcomes” (rows), thereby reducing cloud computing costs and increasing processing speed.
Practical Applications in Developing AI Models
As we move toward Generative AI and Large Language Models (LLMs), the concept of sample space takes on a more complex, multi-dimensional form.
NLP and Word Prediction Spaces
In Natural Language Processing (NLP), the sample space for predicting the next word is the entire vocabulary of the language (often 50,000 to 100,000 tokens). When you type a prompt into an AI tool, the model calculates a probability distribution across this massive sample space.
“Temperature” settings in AI tools directly manipulate how the model interacts with the sample space. A low temperature makes the model pick only the most likely outcome, while a high temperature allows it to explore less probable regions of the sample space, leading to more “creative” or diverse responses.
Computer Vision and Pixel Possibilities
In computer vision, the sample space is astronomically large. For a 1024×1024 RGB image, the number of possible pixel combinations is higher than the number of atoms in the observable universe. To handle this, AI tools use “Dimensionality Reduction.” This tech-heavy process involves mapping the gargantuan original sample space into a smaller “latent space” where the AI can actually perform calculations. This is how tools like Stable Diffusion or Midjourney are able to navigate the “possibility space” of art and photography to generate specific images.
The Future of Probability in Quantum Computing
As we look toward the horizon of technology, the traditional view of sample space is being challenged by quantum computing.
From Bits to Qubits: Expanding the Sample Space
In classical computing, the sample space for a bit is {0, 1}. In quantum computing, a qubit exists in a “superposition” of states. This means the sample space is not just two discrete points, but a complex mathematical sphere (the Bloch Sphere) representing all possible states the qubit can inhabit before it is measured.
This shift expands the sample space exponentially. A quantum computer with 50 qubits has a sample space of 2 to the power of 50 outcomes—all of which can be processed simultaneously. This will revolutionize digital security (breaking current encryption) and drug discovery (modeling the sample space of molecular interactions).

Conclusion: Mastering the Space
Whether you are a software developer writing your first “if-else” statement or a data scientist building a multi-layered neural network, the sample space is your playground. It defines the limits of what is possible and provides the structure needed to navigate uncertainty.
In the tech industry, we are constantly trying to turn “unknown unknowns” into “known outcomes.” By masterfully identifying and analyzing the sample space, tech professionals can build more reliable software, more accurate AI, and more secure digital futures. Understanding the sample space isn’t just a lesson in probability—it’s a lesson in the architecture of the digital world.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.