In the early days of the internet, the World Wide Web was primarily a collection of documents—HTML pages designed to be read by humans. However, as the digital landscape evolved, the need for machines to understand the relationship between data points became paramount. This necessity gave birth to the Resource Description Framework (RDF).
RDF is not just a file format; it is a standard model for data interchange on the Web. Managed by the World Wide Web Consortium (W3C), RDF serves as the foundational layer of the “Semantic Web.” It allows for the integration of data from disparate sources, even if those sources use different underlying schemas. In this technical deep dive, we will explore the architecture of RDF, its various serializations, its role in modern AI, and why it remains a critical technology for the future of linked data.
Understanding the Fundamentals: The Triple Model
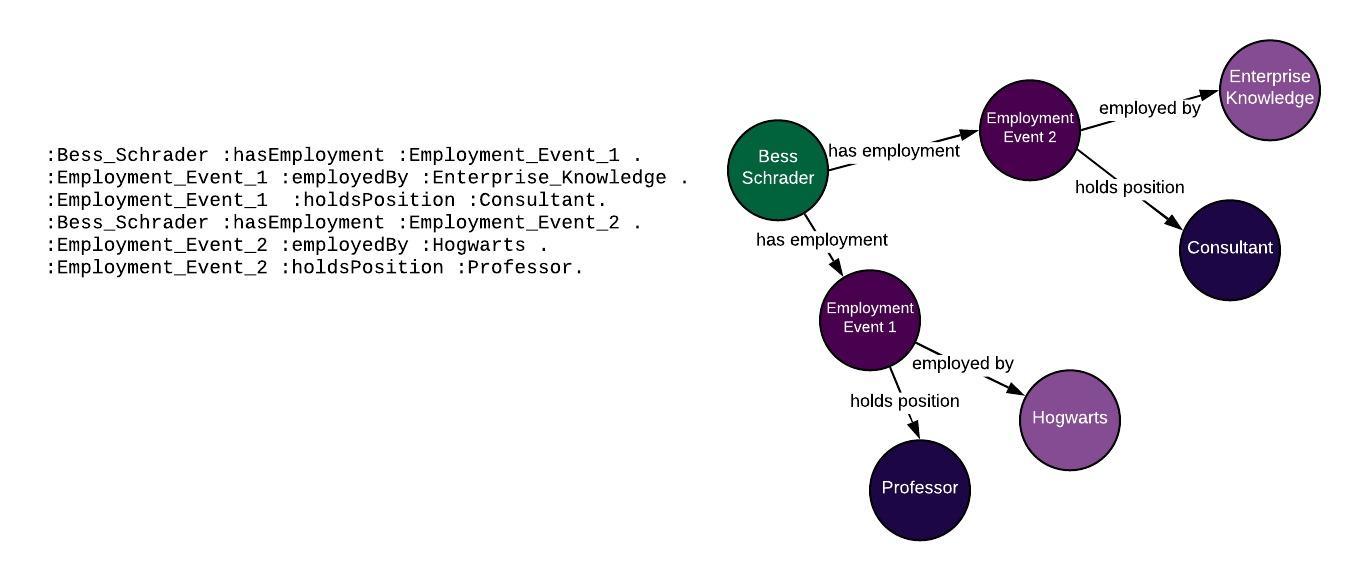
At its core, RDF is deceptively simple. Unlike relational databases that store data in tables or JSON files that use hierarchical trees, RDF uses a graph-based model. This model is built upon a fundamental unit known as a “triple.”
The Subject-Predicate-Object Structure
Every piece of information in RDF is expressed as a statement consisting of three parts:
- Subject: The resource being described (e.g., “The Eiffel Tower”).
- Predicate: The property or relationship (e.g., “is located in”).
- Object: The value or the related resource (e.g., “Paris”).
This structure mimics the way natural language works, making it a powerful tool for representing complex knowledge. When millions of these triples are connected, they form a directed, labeled graph. In this graph, subjects and objects are nodes, and predicates are the edges connecting them.
The Power of URIs and IRIs
In a standard spreadsheet, “Paris” is just a string of text. In RDF, to ensure that machines know exactly which “Paris” we are talking about (Paris, France vs. Paris, Texas), we use Internationalized Resource Identifiers (IRIs) or Uniform Resource Identifiers (URIs).
By using URIs as identifiers, RDF ensures that data is globally unique and linkable. If two different datasets use the same URI for a concept, they are automatically integrated. This is the “Tech” magic behind linked data—it allows information to transcend the silos of individual applications.
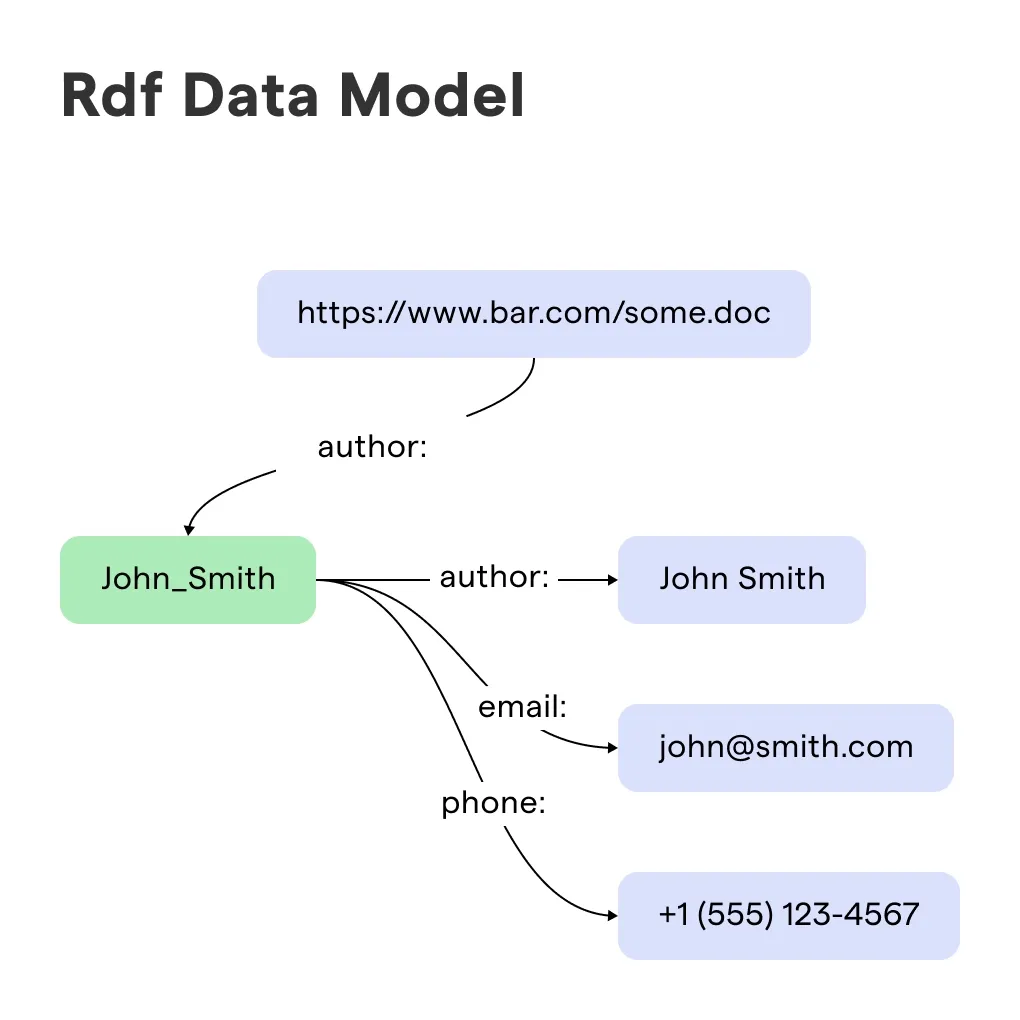
Literals and Blank Nodes
While many objects in a triple are URIs pointing to other resources, some are “literals”—plain text, dates, or numbers. For example, a triple could state that a specific book (Subject) has a “publication date” (Predicate) of “2023-10-01” (Literal). Additionally, RDF accounts for “Blank Nodes,” which represent resources that don’t have a specific URI but are necessary to group related properties together.
Common RDF Serializations: Translating Concepts into Code
RDF is an abstract model, which means there are several ways to actually write it down in a file. These different formats are known as serializations. Depending on your tech stack—whether you are working with web development, big data, or legacy systems—you might choose one over the other.
RDF/XML: The Original Standard
When RDF was first introduced, XML was the dominant data format on the web. Consequently, RDF/XML became the first official serialization. While it is highly structured and compatible with many legacy tools, it is notoriously difficult for humans to read and write. It is also quite verbose, which can lead to larger file sizes than necessary.
Turtle (Terse RDF Triple Language)
Turtle is perhaps the most popular serialization for developers who need to manually inspect or write RDF data. It is designed to be concise and human-readable. By using prefixes to shorten long URIs, Turtle makes the Subject-Predicate-Object structure clear at a glance. It is the go-to format for educational purposes and for configuring many modern graph databases.
JSON-LD (JSON for Linked Data)
In the modern tech ecosystem, JSON is king. JSON-LD was developed to bring the benefits of RDF to the world of JavaScript and web development. It looks like a standard JSON object but includes a @context header that maps keys to URIs.
JSON-LD has seen massive adoption because of Search Engine Optimization (SEO). Google and other search engines use JSON-LD (often via the Schema.org vocabulary) to understand the content of websites, powering “rich snippets” and knowledge panels. If you have ever seen a recipe or a product price directly in search results, you have seen JSON-LD in action.
N-Triples and N-Quads
For high-performance computing and large-scale data processing, N-Triples is the format of choice. It is a very simple format where each line represents exactly one triple. Because it lacks the complexity of XML or the nesting of JSON, it is incredibly fast for machines to parse and serialize, making it ideal for moving billions of data points between systems.
The Role of RDF in the Semantic Web and Linked Data
To understand why RDF is a cornerstone of modern information technology, we must look at the vision of the Semantic Web. Proposed by Tim Berners-Lee, the inventor of the Web, the Semantic Web is an extension of the existing web in which information is given well-defined meaning.
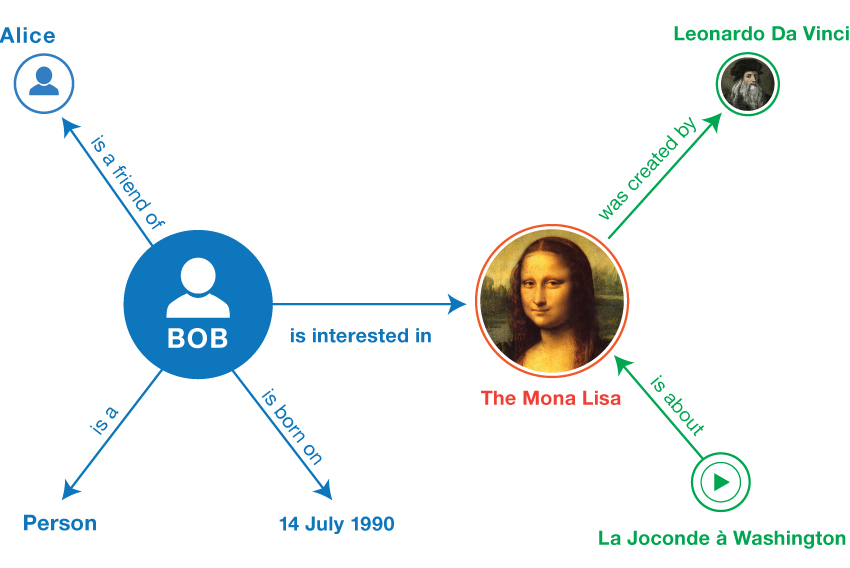
Breaking Down Data Silos
Most data today is trapped in “silos”—proprietary databases that don’t talk to each other. If a tech company wants to merge data from a CRM, a logistics system, and a marketing tool, they often face a nightmare of data transformation. RDF solves this by providing a universal language for data. Because RDF data points are globally identified via URIs, different datasets can be merged simply by putting them in the same graph.
The Linked Data Principles
RDF is the primary vehicle for the four principles of Linked Data:
- Use URIs as names for things.
- Use HTTP URIs so that people can look up those names.
- Provide useful information using standards like RDF and SPARQL when someone looks up a URI.
- Include links to other URIs so that they can discover more things.
This creates a “Web of Data” where a machine can start at one data point (a specific pharmaceutical drug) and follow links to find its chemical properties, the companies that manufacture it, and the clinical trials associated with it—even if that data is hosted on different servers across the globe.
RDF in Modern Tech: AI, Knowledge Graphs, and SPARQL
While the “Semantic Web” as a global vision has taken time to mature, the underlying technology of RDF has exploded in popularity within the corporate and AI sectors.
Building Knowledge Graphs
Tech giants like Google, Amazon, and LinkedIn use Knowledge Graphs to power their services. A knowledge graph is essentially a massive RDF-style network of interconnected facts. For example, when you ask a virtual assistant, “Who directed the movie Inception?” the AI doesn’t just search for text; it traverses a knowledge graph where “Inception” (Subject) has a “Director” (Predicate) named “Christopher Nolan” (Object).
RDF provides the flexibility needed for these graphs. Unlike relational databases, which require a fixed “schema” (you have to define your tables and columns before adding data), RDF is schema-less. You can add new types of relationships at any time without breaking the existing database.
SPARQL: The Query Language for RDF
You cannot talk about RDF without mentioning SPARQL (Simple Protocol and RDF Query Language). If RDF is the “database,” SPARQL is the “SQL.”
SPARQL allows developers to perform complex queries across highly interconnected data. It can perform “graph pattern matching,” which means it can find data based on the shape of the relationships. For example, a SPARQL query could find “all software developers who live in cities with a population over 1 million and have contributed to open-source RDF projects.”
RDF and Artificial Intelligence
The current wave of Generative AI and Large Language Models (LLMs) has actually increased the relevance of RDF. While LLMs are great at processing natural language, they often struggle with “hallucinations”—stating false facts with confidence.
Tech companies are now using RDF-based knowledge graphs to provide “ground truth” for AI. By combining the linguistic power of an LLM with the structured, verifiable facts of an RDF graph (a process often called Retrieval-Augmented Generation or RAG), developers can create AI systems that are both conversational and factually accurate.
RDF vs. Traditional Data Formats: Choosing the Right Tool
Is RDF always the best choice? Not necessarily. To understand where RDF fits in a tech stack, we must compare it to more traditional formats.
RDF vs. Relational Databases (SQL)
Relational databases are excellent for structured, repetitive data like financial transactions or user accounts. However, they struggle with “sparse” data or data where the relationships are more important than the entities themselves. RDF excels in environments where the data is unpredictable and highly interconnected.
RDF vs. Property Graphs (Neo4j)
There is another type of graph database known as a Property Graph. While RDF is a W3C standard designed for web-scale interoperability, Property Graphs are often optimized for performance within a single application. RDF is better when you need to share data across the web or integrate with third-party standards; Property Graphs are often chosen for internal analytics where “sharing” isn’t a priority.
The Learning Curve
One of the main challenges of RDF is its technical complexity. Mastering URIs, ontologies (like RDFS and OWL), and SPARQL requires a different mindset than traditional web development. However, for organizations dealing with massive, fragmented datasets, the long-term benefits of data interoperability and machine readability far outweigh the initial learning curve.
Conclusion: The Future of Data is Connected
The RDF format is more than just a way to store data; it is a philosophy of information. In an era where data is being generated at an exponential rate, the ability to link that data and provide it with context is what turns “noise” into “knowledge.”
From the SEO-friendly JSON-LD tags on your favorite blog to the massive knowledge graphs powering the world’s most advanced AI, RDF is the invisible thread connecting the digital universe. As we move toward a more intelligent, automated future, the Resource Description Framework will continue to serve as the essential language that allows machines to understand the world as humans do—not as isolated facts, but as a rich, interconnected web of meaning.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.