In the rapidly evolving landscape of technology, particularly within the realms of Artificial Intelligence (AI) and Machine Learning (ML), the ability to make decisions under uncertainty is what separates primitive software from sophisticated, human-like systems. At the heart of this decision-making capability lies a statistical concept known as “posterior probability.” While it may sound like a term relegated to dusty academic journals, posterior probability is the engine driving everything from your email’s spam filter to the navigational systems of autonomous vehicles.
To understand posterior probability is to understand how modern machines “learn.” Unlike traditional software that follows rigid “if-then” logic, modern AI uses Bayesian inference to update its understanding of the world as new data arrives. This article explores the technical intricacies of posterior probability, its mathematical foundation, and its indispensable role in the current tech ecosystem.

The Mechanics of Bayesian Inference in Modern Computing
To grasp posterior probability, one must first understand the framework of Bayesian inference. In tech development, we often deal with systems that must estimate a “state” based on “evidence.”
The Fundamental Equation: Bayes’ Theorem
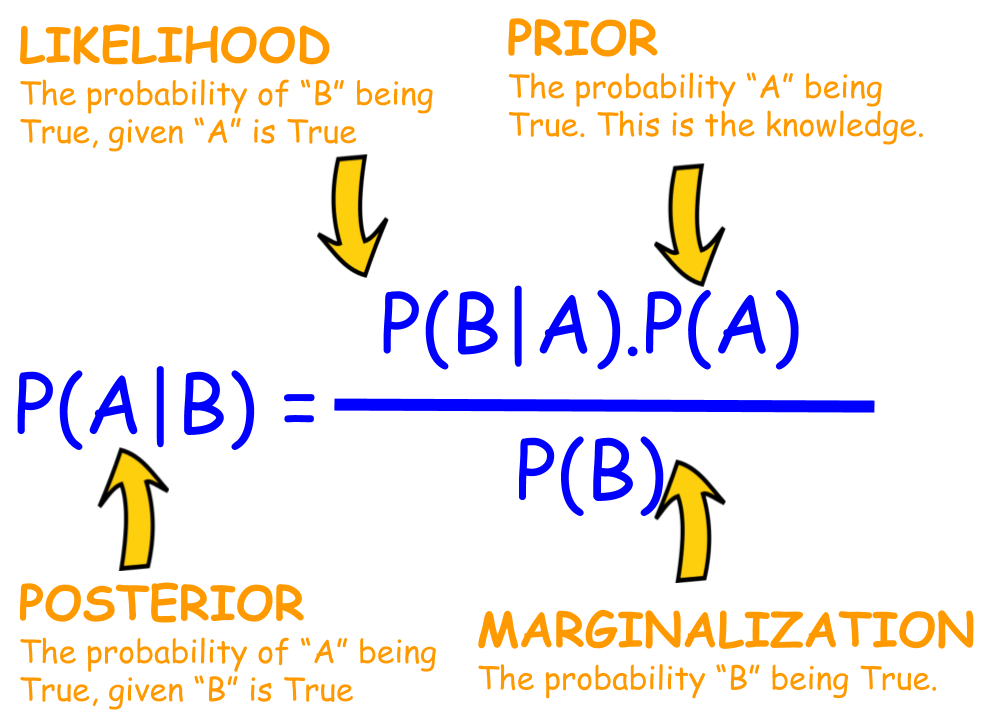
In technical terms, posterior probability is the revised or updated probability of an event occurring after taking into consideration new information. It is derived from Bayes’ Theorem, which is mathematically expressed as:
P(H|E) = [P(E|H) * P(H)] / P(E)
Where:
- P(H|E) is the Posterior Probability: The probability of hypothesis (H) being true given the evidence (E).
- P(E|H) is the Likelihood: The probability of seeing the evidence if the hypothesis is true.
- P(H) is the Prior Probability: The initial strength of our belief in the hypothesis before seeing the evidence.
- P(E) is the Marginal Likelihood: The total probability of the evidence under all possible hypotheses.
The Logic of “Updating Beliefs”
In software engineering, specifically in predictive modeling, the “Prior” represents our existing dataset or historical knowledge. When a new packet of data (the “Evidence”) enters the system, the algorithm calculates the “Likelihood” of that data occurring. By multiplying the Prior by the Likelihood and normalizing it, the system produces the “Posterior.” This new Posterior then becomes the Prior for the next calculation, creating a continuous loop of learning. This iterative process allows AI tools to refine their accuracy over time, adapting to changing user behaviors or environmental shifts.
Real-World Tech Applications: From NLP to Robotics
Posterior probability isn’t just a theoretical construct; it is a practical tool used across various tech niches to solve complex problems that involve noise, ambiguity, and massive datasets.
Natural Language Processing (NLP) and Large Language Models
In the world of Generative AI and Large Language Models (LLMs) like GPT-4, posterior probability is used to predict the next token in a sequence. When you type a prompt, the model isn’t just guessing words at random; it is calculating the posterior probability of word “B” appearing, given that word “A” was just used.
In sentiment analysis—a subset of NLP—Bayesian classifiers determine whether a product review is “positive” or “negative.” The algorithm starts with a prior (e.g., the general frequency of positive reviews in the database) and updates it based on the presence of specific keywords (the evidence), eventually arriving at a posterior probability that dictates the final classification.
Computer Vision and Probabilistic Robotics
For hardware gadgets like drones and self-driving cars, the environment is never 100% certain. Sensors (LiDAR, cameras, ultrasonic) are often “noisy”—they might misinterpret a shadow for a solid object or vice versa.
Engineers use a technique called the Kalman Filter, which relies heavily on posterior probability, to track the position of objects. The car has a “prior” of where it thinks it is. When the sensors provide new “evidence,” the system calculates the “posterior” position. This allows the vehicle to maintain a smooth path even if a sensor momentarily glitches, as the system balances its historical data against the new, potentially flawed evidence.
Predictive Maintenance in IoT
In the Industrial Internet of Things (IIoT), posterior probability is used to predict equipment failure. By analyzing the prior frequency of hardware breakdowns and combining it with real-time sensor data (vibration, heat, power consumption), AI tools can calculate the posterior probability of a machine failing in the next 24 hours. This allows tech teams to perform maintenance before a catastrophic shutdown occurs.
Posterior Probability in Machine Learning Model Training
When data scientists build models, they often face a choice between different estimation methods. Understanding the role of posterior probability is crucial for optimizing these models for production environments.
MAP vs. MLE: Choosing the Right Approach
There are two primary ways to estimate parameters in machine learning: Maximum Likelihood Estimation (MLE) and Maximum A Posteriori (MAP).
- MLE looks only at the data (the evidence) and ignores any prior knowledge.
- MAP incorporates the posterior probability by including a “prior.”
In many tech applications, MAP is preferred because it acts as a safeguard. For instance, if a startup is building a medical diagnostic tool but only has a small dataset, MLE might lead to wild, inaccurate conclusions. By using MAP and incorporating a “prior” (established medical knowledge), the model produces a posterior probability that is much more grounded and reliable.
Regularization and Preventing Overfitting
One of the biggest challenges in software development is “overfitting,” where an AI model becomes so attuned to its training data that it fails when presented with real-world scenarios. Posterior probability helps solve this through Bayesian regularization. By assigning a prior probability distribution to the model’s weights, developers can penalize overly complex models. This ensures that the posterior distribution favors simpler, more generalizable solutions, leading to more robust software tools.
Bayesian Neural Networks
While traditional neural networks assign fixed weights to neurons, Bayesian Neural Networks (BNNs) treat weights as probability distributions. This means that instead of giving a single output, the network provides a posterior distribution that reflects its “certainty.” For high-stakes tech—such as AI used in digital security or medical imaging—knowing how sure the AI is (via the posterior) is just as important as the prediction itself.
The Role of Probabilistic Logic in Digital Security
In an era of sophisticated cyber threats, deterministic security software is no longer sufficient. Today’s digital security tools rely on posterior probability to detect anomalies and stop zero-day exploits.
Anomaly Detection and Threat Hunting
Cybersecurity platforms monitor millions of network events per second. A single “strange” login attempt might not be enough to trigger an alarm. However, using Bayesian inference, the system can calculate the posterior probability of a breach.
- Prior: The user usually logs in from San Francisco at 9:00 AM.
- Evidence: A login attempt occurs from an unrecognized IP in Eastern Europe at 3:00 AM.
- Posterior: The probability of this being a malicious actor increases significantly.
As the actor moves through the network, each new action provides more evidence, updating the posterior probability until it crosses a threshold that triggers an automated lockout.
Spam Filtering and Phishing Protection
The classic example of posterior probability in tech is the Naive Bayes spam filter. The “prior” is the percentage of all emails that are spam. The “evidence” is the presence of words like “crypto,” “urgent,” or “win.” The “posterior” is the probability that this specific email is spam given those words. This is why spam filters get better the more you use them; every time you mark an email as “not spam,” you are updating the prior for the algorithm, allowing it to calculate a more accurate posterior in the future.
The Future of Probabilistic AI
As we move toward “Artificial General Intelligence” (AGI), the reliance on posterior probability will only grow. Future AI tools will need to manage even higher levels of uncertainty and operate in environments where data is scarce or conflicting.
Edge Computing and Real-Time Inference
With the rise of edge computing—where AI runs locally on gadgets rather than in the cloud—efficient probabilistic calculations are essential. Developers are creating lightweight Bayesian models that can calculate posterior probabilities using minimal processing power, allowing for “smart” behavior in everything from smartwatches to industrial sensors without needing a constant internet connection.

Ethical AI and Explainability
One of the major “black box” problems in tech is understanding why an AI made a certain decision. By leveraging posterior probability, developers can build “Explainable AI” (XAI). Instead of a cryptic result, the system can show the posterior distribution, essentially saying: “I am 85% sure this is a security threat because the current evidence contradicts the established prior behavior by X amount.” This transparency is vital for the adoption of AI in regulated industries like finance and healthcare.
In conclusion, posterior probability is the mathematical heartbeat of the digital age. It transforms static data into dynamic intelligence, allowing software to learn, adapt, and reason. For anyone working in tech—from software engineers to product managers—mastering the concept of the “posterior” is key to building the next generation of resilient, intelligent, and autonomous tools.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.