Kafka, a distributed event streaming platform, has become a cornerstone of modern data architecture, enabling real-time data pipelines, streaming analytics, and microservices communication. At the heart of this powerful ecosystem lies the Kafka Broker, a fundamental component responsible for the management and distribution of data within a Kafka cluster. Understanding the role and functionality of a Kafka broker is crucial for anyone looking to leverage Kafka effectively. This article delves deep into what a Kafka broker is, its responsibilities, its architectural significance, and how it contributes to the overall resilience and scalability of the Kafka platform.
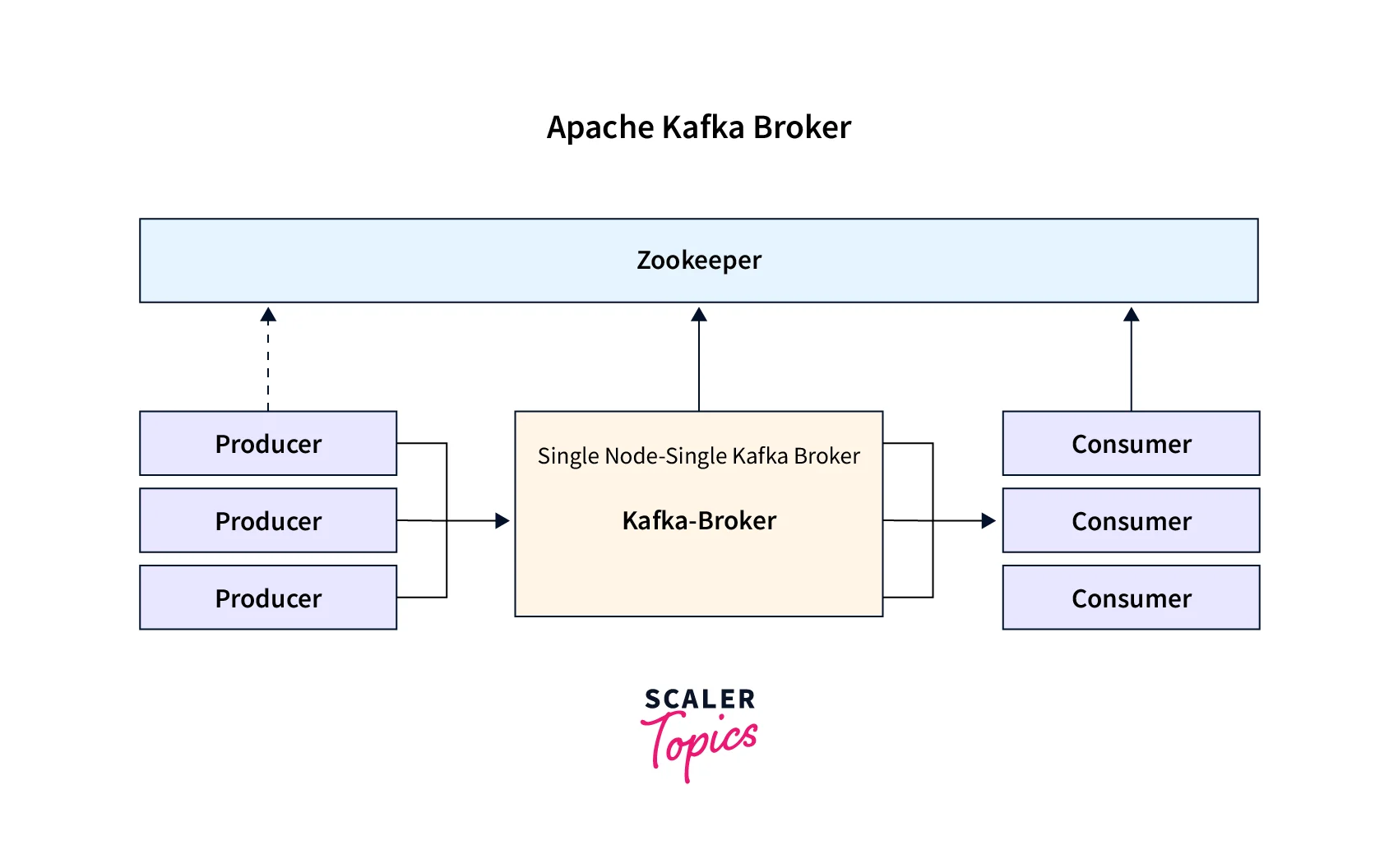
The Core Functionality of a Kafka Broker
At its most basic, a Kafka broker is a server that forms part of a Kafka cluster. It’s the workhorse that handles the heavy lifting of data ingestion, storage, and retrieval. When data producers send messages, it’s brokers that receive and store them. When consumers want to read data, it’s brokers they interact with. This fundamental role makes brokers the central nervous system of any Kafka deployment.
Data Ingestion and Storage
Producers, which are applications that generate data streams, send messages to specific Kafka topics. These topics are logical channels for organizing data. The broker’s primary responsibility during ingestion is to receive these messages and append them to the end of a designated partition within a topic. A partition is an ordered, immutable sequence of records that is continually appended to. Brokers are designed for high-throughput, low-latency data writes, ensuring that incoming data is processed efficiently.
The data is stored durably on the disk of the broker. This durability is a key feature of Kafka, ensuring that data is not lost even in the event of hardware failures. Brokers store data in logs, where each message is assigned a sequential offset within its partition. This offset acts as a unique identifier for each message and is used by consumers to track their position in the data stream.
Data Serving and Consumption
When consumers, which are applications that read data streams, request data from a topic, they interact with the brokers that host the partitions for that topic. Consumers specify which topic and partition they are interested in, and they often provide an offset to indicate where they want to start reading. Brokers then serve the requested messages from their local storage.
Crucially, brokers do not actively push data to consumers. Instead, consumers poll brokers for new messages. This pull model gives consumers control over their consumption rate, allowing them to process data at their own pace and preventing them from being overwhelmed by high-volume data streams. This also simplifies the broker’s architecture, as it doesn’t need to manage individual connections and delivery states for each consumer.
Partition Management
Kafka topics are divided into partitions to enable parallel processing and horizontal scalability. Each partition is replicated across multiple brokers to ensure fault tolerance. A broker can host multiple partitions for different topics, or multiple partitions for the same topic. The assignment of partitions to brokers is a critical aspect of cluster management.
For each partition, one broker is designated as the “leader,” and others are designated as “followers.” The leader broker is responsible for all read and write requests for that partition. If a consumer or producer sends a request, it will be directed to the leader. Followers passively replicate the data from the leader. This leader-follower model is central to Kafka’s high availability.
The Role of Brokers in Kafka Architecture
The architecture of Kafka is inherently distributed, with brokers working in concert to form a cluster. This distributed nature is what provides Kafka with its impressive scalability and fault-tolerance capabilities. The interplay between brokers is managed through a coordination service, typically Apache ZooKeeper, although newer versions of Kafka are moving towards an internal Raft-based quorum controller.
Cluster Coordination and Metadata Management
While brokers are the data handlers, they rely on a coordination service to manage the cluster’s state and metadata. This metadata includes information about which brokers are alive, which topics exist, which partitions belong to each topic, the leader and follower status of partitions, and consumer group offsets.
The coordination service ensures that all brokers in the cluster have a consistent view of the cluster’s state. When a broker joins or leaves the cluster, or when a partition leader fails, the coordination service is updated, and this information is propagated to all other brokers. This distributed consensus is vital for maintaining the integrity and availability of the Kafka cluster.
Leader Election and Replication
The leader-follower model is fundamental to Kafka’s fault tolerance. If a leader broker fails, the coordination service detects this failure and initiates a leader election process for the affected partitions. A follower broker that has the most up-to-date replica of the partition is elected as the new leader. This process is designed to be quick, minimizing downtime and ensuring that data continues to be available.
Replication is the mechanism by which data is copied across multiple brokers. Producers can configure their desired “acknowledgment” level, specifying how many replicas must acknowledge a write before it is considered successful. This configuration allows for a trade-off between durability and latency. A higher acknowledgment level provides stronger durability guarantees but can increase write latency.
Broker Discovery and Load Balancing
Producers and consumers do not need to know the specific physical location of all brokers. They typically connect to a list of bootstrap servers, which are a subset of the brokers in the cluster. The brokers then act as discovery points. For example, when a producer connects, the broker it initially connects to can provide it with metadata about which brokers are leaders for the partitions of the target topic. This metadata allows the producer to connect directly to the appropriate leader brokers for subsequent requests.
This distributed metadata and discovery mechanism inherently provides a form of load balancing. Producers and consumers will naturally distribute their connections across available brokers, and the leader election process ensures that even if some brokers are heavily loaded, responsibilities can shift to less busy ones during failures.
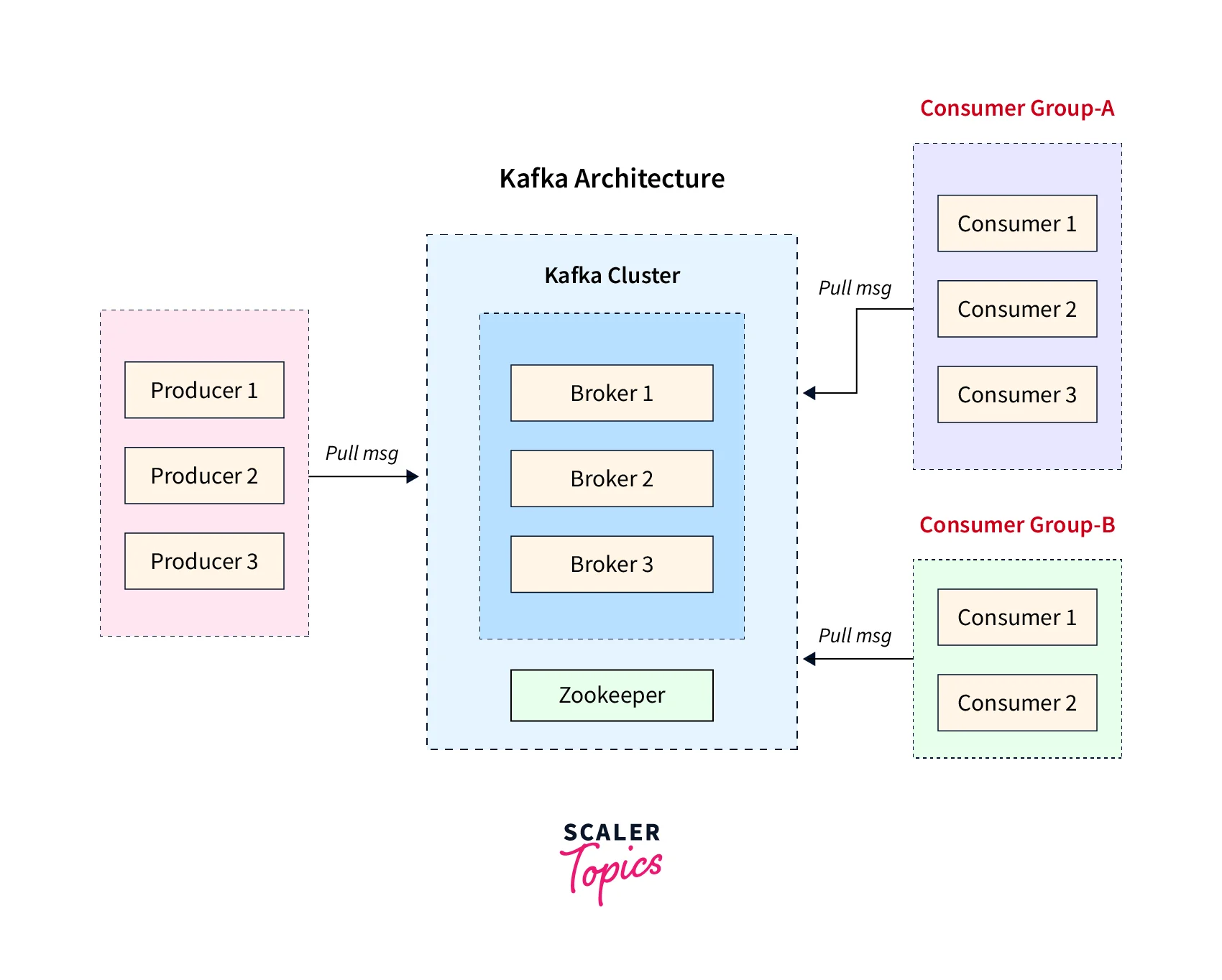
Key Responsibilities and Configurations of a Kafka Broker
Beyond the core functionalities, Kafka brokers have specific responsibilities and can be configured in numerous ways to optimize performance, durability, and security.
Broker Configuration Parameters
Each Kafka broker is configured through a properties file (e.g., server.properties). This file contains hundreds of parameters that allow for fine-grained control over the broker’s behavior. Some of the most important parameters include:
broker.id: A unique integer identifier for each broker in the cluster.listeners: Defines the network interfaces and ports the broker listens on for client connections and inter-broker communication.log.dirs: Specifies the directories on disk where Kafka will store its log segments.num.partitions: The default number of partitions to create for new topics if not explicitly specified.default.replication.factor: The default replication factor for new topics.zookeeper.connect: The connection string for the ZooKeeper ensemble (or the controller quorum details in newer versions).auto.create.topics.enable: Determines whether topics can be automatically created when a producer or consumer first accesses them.
Tuning these parameters is critical for optimizing a Kafka cluster for specific workloads. For instance, adjusting log.segment.bytes and log.retention.hours can impact storage usage and data availability.
Inter-Broker Communication
Brokers within a Kafka cluster communicate with each other to replicate data, elect leaders, and synchronize cluster state. This inter-broker communication is secured and optimized for efficiency. The protocols used for this communication are internal to Kafka and are managed automatically.
When a broker acts as a leader for a partition, it receives writes from producers and then propagates those writes to its follower replicas. This replication process ensures that data is safely copied across multiple machines, providing fault tolerance. The speed and reliability of this inter-broker communication directly impact the overall performance and durability of the Kafka cluster.
Monitoring and Metrics
Effective management of a Kafka cluster relies heavily on comprehensive monitoring. Each Kafka broker exposes a wealth of metrics that provide insights into its operational status, performance, and potential issues. These metrics include:
- Request Rate and Latency: Measures the number of requests processed by the broker and the time taken to process them.
- Bytes In/Out: Tracks the amount of data being produced to and consumed from the broker.
- Under-replicated Partitions: Indicates partitions that do not have the required number of in-sync replicas.
- Leader Elections: Tracks the frequency of leader elections, which can signal instability.
- Disk Usage: Monitors the disk space utilized by the brokers for storing log segments.
Tools like Prometheus, Grafana, and Kafka’s own command-line tools can be used to collect, visualize, and alert on these metrics, enabling administrators to proactively identify and resolve issues.
Ensuring High Availability and Scalability with Brokers
The distributed nature of Kafka, with multiple brokers working together, is the key to its high availability and scalability. By understanding how brokers contribute to these aspects, organizations can design robust and performant data streaming solutions.
Fault Tolerance through Replication
As discussed, replication is the cornerstone of Kafka’s fault tolerance. Each partition can have multiple replicas distributed across different brokers, potentially in different physical locations (availability zones). If a broker hosting a partition leader fails, one of its followers can seamlessly take over, ensuring that data remains accessible and processing continues with minimal interruption. The min.insync.replicas configuration parameter plays a vital role here, ensuring that writes are only acknowledged when they are replicated to a minimum number of brokers, further guaranteeing durability.
Horizontal Scalability
The ability to scale Kafka horizontally by adding more brokers to the cluster is a major advantage. As data volumes increase or the number of producers and consumers grows, simply adding more broker nodes allows the cluster to handle the increased load. Partitions can be rebalanced across the new brokers, distributing the processing and storage responsibilities. This elasticity means that Kafka can adapt to changing demands without significant architectural overhauls.
Each broker contributes to the overall throughput and storage capacity of the cluster. By distributing topics and partitions across a larger number of brokers, the processing of individual partitions can be parallelized, leading to higher overall data ingestion and consumption rates.
Designing for Resilience
When designing a Kafka cluster, careful consideration must be given to the number of brokers, their placement across availability zones, and the replication factors for topics. A common pattern is to run at least three brokers to ensure that a single broker failure doesn’t lead to data loss or service disruption. For critical applications, a higher replication factor (e.g., 3 or 5) and strategic placement of brokers across different data centers can provide even greater resilience against more catastrophic failures.
The broker’s role in managing partitions, handling leader elections, and replicating data is fundamental to achieving these resilience goals. Without these distributed responsibilities, Kafka would be susceptible to single points of failure and would lack the capacity to handle large-scale data streams.
In conclusion, the Kafka broker is far more than just a server; it is the fundamental building block of a Kafka cluster, responsible for the reliable ingestion, storage, and serving of event streams. Its distributed nature, coupled with sophisticated mechanisms for replication, leader election, and metadata management, empowers organizations to build highly scalable, fault-tolerant, and performant data pipelines that are essential for real-time data processing and analysis in today’s data-driven world. Understanding the intricate workings of the Kafka broker is therefore paramount for any individual or organization looking to harness the full power of this transformative technology.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.