The seemingly simple question, “what is which part of speech?”, takes on profound new meaning in the age of artificial intelligence and sophisticated software. While traditionally a fundamental concept taught in elementary language arts, understanding the role of nouns, verbs, adjectives, and adverbs is no longer solely the domain of human grammarians. Today, this foundational linguistic knowledge is a critical gateway for machines to comprehend, process, and generate human language, unlocking a universe of technological possibilities.
In an increasingly digitized world, where data is king and communication is paramount, the ability of technology to grasp the nuances of natural language is not just an advantage—it’s a necessity. From the intelligence powering our search engines and virtual assistants to the precision of advanced content creation tools and cybersecurity protocols, the underlying principle of recognizing “which part of speech” a word represents is often at the heart of their functionality. This article delves into how technology interprets and leverages this core linguistic concept, bridging the gap between human expression and machine understanding.

The Foundational Role of Parts of Speech in Human Communication
Before we explore the technological implications, it’s essential to briefly revisit why parts of speech are so crucial for human communication. They are the building blocks, the structural framework upon which all meaningful sentences are constructed, allowing us to convey complex ideas, emotions, and information with clarity and precision.
A Quick Grammar Refresher
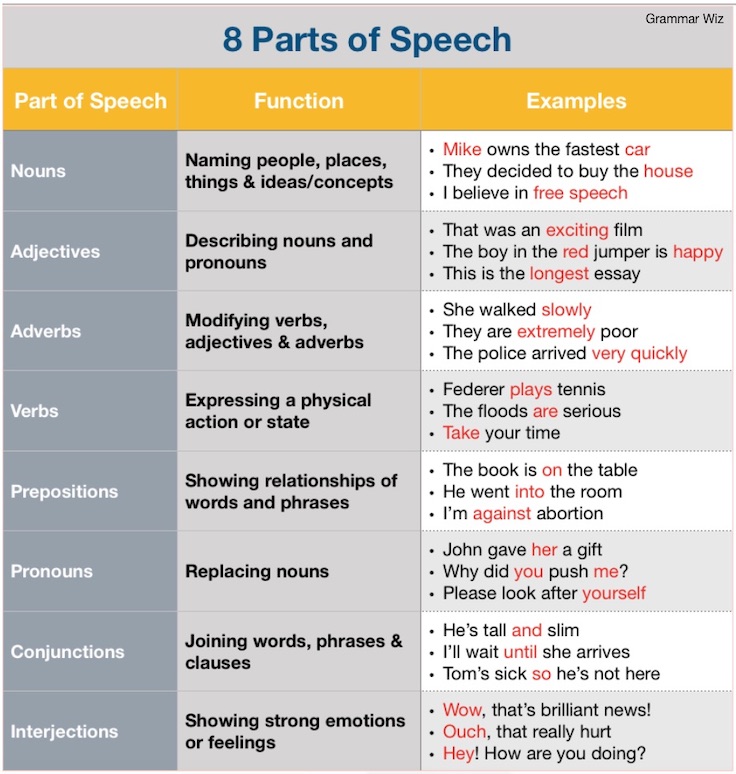
At its core, a “part of speech” (often abbreviated as POS) is a category assigned to words based on their syntactic function and semantic meaning within a sentence. The eight traditional parts of speech are:
- Nouns: Represent people, places, things, or ideas (e.g., engineer, Silicon Valley, algorithm, innovation).
- Pronouns: Replace nouns to avoid repetition (e.g., he, she, it, they, which).
- Verbs: Describe actions or states of being (e.g., develop, compute, analyze, is).
- Adjectives: Modify nouns or pronouns, providing more detail (e.g., cutting-edge, efficient, complex).
- Adverbs: Modify verbs, adjectives, or other adverbs, indicating how, when, where, or to what extent (e.g., rapidly, digitally, very).
- Prepositions: Show the relationship between a noun/pronoun and other words in a sentence (e.g., in, on, with, for).
- Conjunctions: Connect words, phrases, or clauses (e.g., and, but, or, because).
- Interjections: Express strong emotion (e.g., Wow!, Oh!, Alas!).
Understanding these categories allows us to parse sentences, identify subjects and objects, and determine the logical flow of information.
Why Grammatical Structure Matters
Without parts of speech, language would be a chaotic jumble of words. They provide the necessary structure for meaning. Consider the words “run,” “fast,” and “track.” Individually, they carry meaning. But only when their parts of speech are correctly arranged and understood can we differentiate between “He will run fast on the track” (verb, adverb, noun) and “The track team needs a fast runner” (noun, adjective, noun). The ability to differentiate these structures is not just academic; it’s fundamental to extracting intent and context, a capability increasingly vital for machines interacting with human users.
Bridging the Human-Machine Language Gap: Introduction to NLP
The real challenge for technology lies in replicating this innate human ability to understand grammatical structure. Unlike humans who acquire language intuitively, computers need explicit rules and sophisticated algorithms to process natural language. This is the domain of Natural Language Processing (NLP), a branch of AI that enables computers to understand, interpret, and generate human language in a valuable way.
The Challenge of Unstructured Data
Most of the world’s digital information—web pages, emails, social media posts, documents—exists as unstructured text. This means it doesn’t fit into predefined databases or spreadsheets. For a machine to make sense of this deluge of words, it must first break down and categorize the language components, much like a child learning to identify nouns and verbs. The inherent ambiguity, vast vocabulary, and complex grammatical rules of human languages make this an incredibly difficult task. “Fly” can be a verb or a noun, “bank” can refer to a financial institution or the side of a river. Without understanding context and grammatical role, a machine cannot accurately interpret the meaning.
Tokenization and Lexical Analysis
The first step in any NLP pipeline is typically tokenization, where a continuous stream of text is broken down into individual units called “tokens” (usually words, but also punctuation marks). For example, the sentence “AI is transforming industries.” would be tokenized into [“AI”, “is”, “transforming”, “industries”, “.”].
Following tokenization, lexical analysis often involves looking up these tokens in dictionaries or lexicons to understand their base form (lemmas) and potential meanings. However, a word’s meaning and function are heavily dependent on its context within a sentence. This is precisely where the concept of “which part of speech” becomes critical for machines. Knowing that “bank” is a noun in “river bank” but a verb in “bank the money” is essential for accurate processing.
Part-of-Speech (POS) Tagging: A Cornerstone of Language Understanding
The process by which computers identify the grammatical category of each word in a text is known as Part-of-Speech (POS) Tagging. It’s a foundational step in many NLP applications, serving as a linguistic Rosetta Stone that helps machines translate human language into a structured format they can understand and analyze.

How POS Tagging Works (Algorithms, Machine Learning)
Early POS taggers relied on rule-based systems, using hand-crafted grammatical rules to assign tags. For instance, a rule might state: “If a word follows a determiner (like ‘the’ or ‘a’) and precedes a verb, it is likely a noun.” While effective for simpler cases, these systems struggled with ambiguity and the sheer complexity of natural language.
Modern POS tagging primarily uses statistical and machine learning approaches. These models are trained on massive corpora (large datasets of text) that have been manually annotated with correct POS tags. By analyzing patterns in these annotated texts, the models learn to predict the most likely part of speech for a given word in a given context. Common algorithms include:
- Hidden Markov Models (HMMs): These models calculate the probability of a word appearing with a specific tag and the probability of one tag following another.
- Conditional Random Fields (CRFs): CRFs consider a broader range of contextual features, making them more robust than HMMs.
- Recurrent Neural Networks (RNNs) and Transformers: More recently, deep learning architectures, particularly Transformers (like those powering ChatGPT), have achieved state-of-the-art results. They can capture long-range dependencies in sentences, understanding how words far apart can influence each other’s grammatical roles.
The Importance of Context in POS Tagging
The key to accurate POS tagging, whether by humans or machines, is context. Words are rarely unambiguous in isolation. Take the word “lead”:
- “The metal lead is heavy.” (Noun)
- “She will lead the team.” (Verb)
- “We found a lead in the investigation.” (Noun)
A sophisticated POS tagger uses the surrounding words, punctuation, and even the overall sentence structure to determine the correct tag. It understands that “the” often precedes a noun, and “will” often precedes a verb. Deep learning models take this contextual understanding to a new level, learning subtle semantic and syntactic relationships that help resolve ambiguities with remarkable accuracy.
Real-World Applications of POS Tagging in Technology
POS tagging is not merely an academic exercise; it underpins a vast array of technological applications that we interact with daily, often without realizing the intricate linguistic processing happening behind the scenes.
Enhancing Search Engines and Information Retrieval
When you type a query into a search engine, POS tagging helps the system understand your intent. If you search for “apple stock,” the engine knows “apple” is likely a proper noun (company) and “stock” is a noun (financial asset), not a verb (to stock shelves) or an adjective (stock car). This allows for more relevant search results by distinguishing between homographs and focusing on the semantic meaning of your query. In more advanced information retrieval, POS tagging can help identify key phrases, named entities (people, organizations, locations), and relationships between them.
Powering Smart Assistants and Chatbots
Virtual assistants like Siri, Alexa, and Google Assistant, as well as customer service chatbots, rely heavily on understanding the grammatical structure of your commands and questions. When you say, “Set a timer for ten minutes,” the system must identify “set” as a verb, “timer” as a noun (the object of the verb), and “ten minutes” as a temporal adverbial phrase. This grammatical breakdown allows the AI to correctly interpret the command and execute the appropriate action, rather than getting confused by the word “set” as in “a set of dishes.”
Improving Grammar Checkers and Content Creation Tools
Tools like Grammarly or built-in spell and grammar checkers in word processors are direct beneficiaries of robust POS tagging. They use the identified parts of speech to detect grammatical errors such as subject-verb agreement issues (“He run fast” vs. “He runs fast”), incorrect pronoun usage, or misplaced modifiers. Beyond error correction, advanced content creation AI can leverage POS information to generate grammatically correct and stylistically appropriate text, ensuring that nouns are used where nouns should be, and verbs where verbs should be.
Sentiment Analysis and Text Summarization
In sentiment analysis, understanding the part of speech helps differentiate between positive and negative opinions. For example, “I like the new feature” (verb, adjective, noun) expresses a positive sentiment. If “like” were an adverb (“like he said”), the sentiment would be different. In text summarization, POS tagging aids in identifying the most critical phrases and sentences by recognizing key nouns, verbs, and their modifiers, allowing algorithms to condense information while retaining core meaning.
The Future of Semantic Understanding: Beyond Simple Tagging
While POS tagging remains a fundamental component, the frontier of AI’s language capabilities is moving towards deeper semantic and contextual understanding. The goal is not just to know what a word is, but what it means in its entire linguistic environment.
Deep Learning and Contextual Embeddings
Recent advancements in deep learning, particularly with models like BERT, GPT-3, and their successors, have revolutionized NLP. These models utilize “contextual embeddings,” which are numerical representations of words that capture not just their inherent meaning but also their meaning in the context of the surrounding words. Unlike older methods where “bank” might have two separate embeddings (financial institution, river’s edge), contextual embeddings generate a unique representation for “bank” depending on the sentence it appears in. This allows for a much richer and nuanced understanding of language, moving beyond simple grammatical categorization to true semantic comprehension.
The Evolving Role of Grammar in Advanced AI
Even with contextual embeddings and sophisticated neural networks, the underlying principles of grammar, including parts of speech, remain crucial. They provide the structural scaffolding that deep learning models still implicitly or explicitly learn from. As AI models become more powerful, they don’t discard grammar; rather, they learn its rules in more sophisticated and flexible ways, often discovering patterns that human grammarians might not have explicitly defined. The distinction between noun and verb, for instance, is still a vital feature for these models to effectively process and generate coherent language.
Ethical Considerations and Bias in Language Models
As AI’s language capabilities grow, so do the ethical considerations. The training data used for these models, often scraped from the internet, can contain societal biases, stereotypes, and problematic language patterns. If a model learns that certain professions are predominantly associated with masculine pronouns or certain attributes with feminine ones, it can perpetuate these biases in its outputs. Understanding parts of speech and how they are used in different contexts is crucial for identifying and mitigating such biases, ensuring that AI-generated language is fair, inclusive, and accurate.
In conclusion, the seemingly straightforward question, “what is which part of speech?”, is far more than a grammar exercise. It represents a fundamental challenge and a pivotal achievement in the realm of technology. By enabling machines to dissect and understand the grammatical roles of words, we unlock their potential to interact with human language in ways that were once confined to science fiction. As AI continues to evolve, its grasp of these linguistic fundamentals will only deepen, leading to ever more intelligent, intuitive, and impactful technological innovations.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.