In the rapidly evolving landscape of technology, programming serves as the bedrock of innovation. Whether you are interacting with an AI-driven chatbot, navigating a mobile application, or managing a complex cloud infrastructure, the underlying logic of these systems relies on a few fundamental concepts. Chief among these is the “variable.” To the uninitiated, a variable might seem like a dry mathematical term, but in the realm of software development, it is a dynamic and essential tool that allows programs to process information, make decisions, and interact with the physical world.
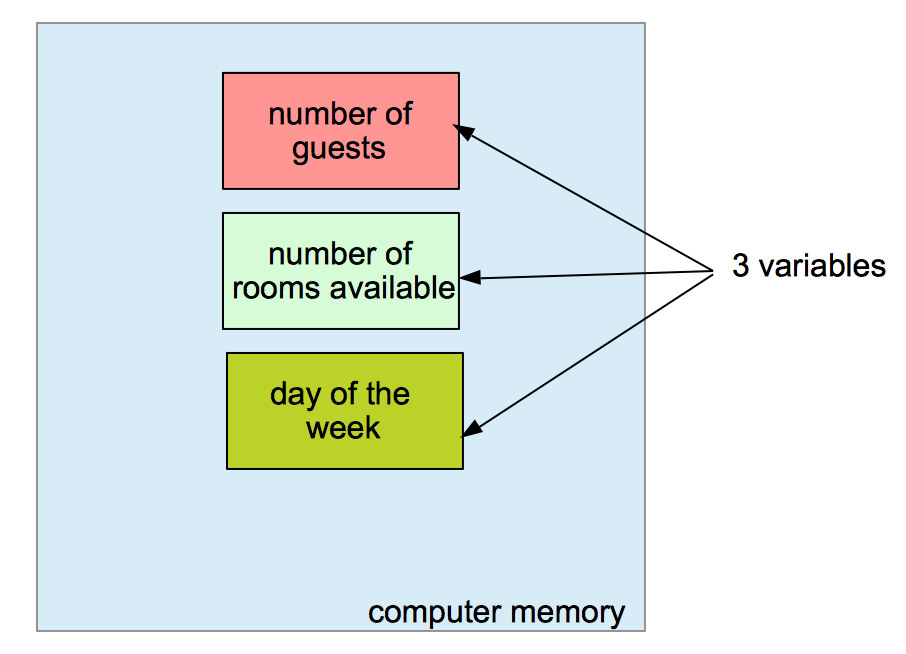
Understanding variables is the first step toward digital literacy in the 21st century. This guide explores the technical intricacies of variables, their role in memory management, and why they are indispensable to the tech industry.
Understanding the Core Concept: The Digital Storage Unit
At its simplest level, a variable is a symbolic name for a value that can change. However, from a technical perspective, a variable is a reference to a specific location in a computer’s memory (RAM). When you create a variable, you are essentially asking the operating system to reserve a “bucket” or a slot in its memory banks where you can store a piece of information to be retrieved or modified later.
The Container Metaphor
Think of a variable as a labeled box in a massive warehouse. The warehouse represents the computer’s memory. If you want to keep track of a user’s score in a video game, you take a box, write “UserScore” on the side, and put a piece of paper with the number “0” inside it. Whenever the user earns points, you find the box labeled “UserScore,” take out the old paper, and replace it with a new one reflecting the updated total. Without the label (the variable name), you would have thousands of boxes and no way of knowing which one contains the data you need.
How Computers Manage Memory
Modern software requires efficient memory management to ensure high performance. When a programmer defines a variable, the computer’s compiler or interpreter translates that high-level name into a hexadecimal memory address (e.g., 0x7fff5fbff610). By using variables, developers don’t have to track these complex addresses manually. The programming language handles the “mapping” between the human-readable name and the machine-readable location, allowing for faster development and fewer errors in complex software architectures.
The Anatomy of a Variable: Name, Value, and Type
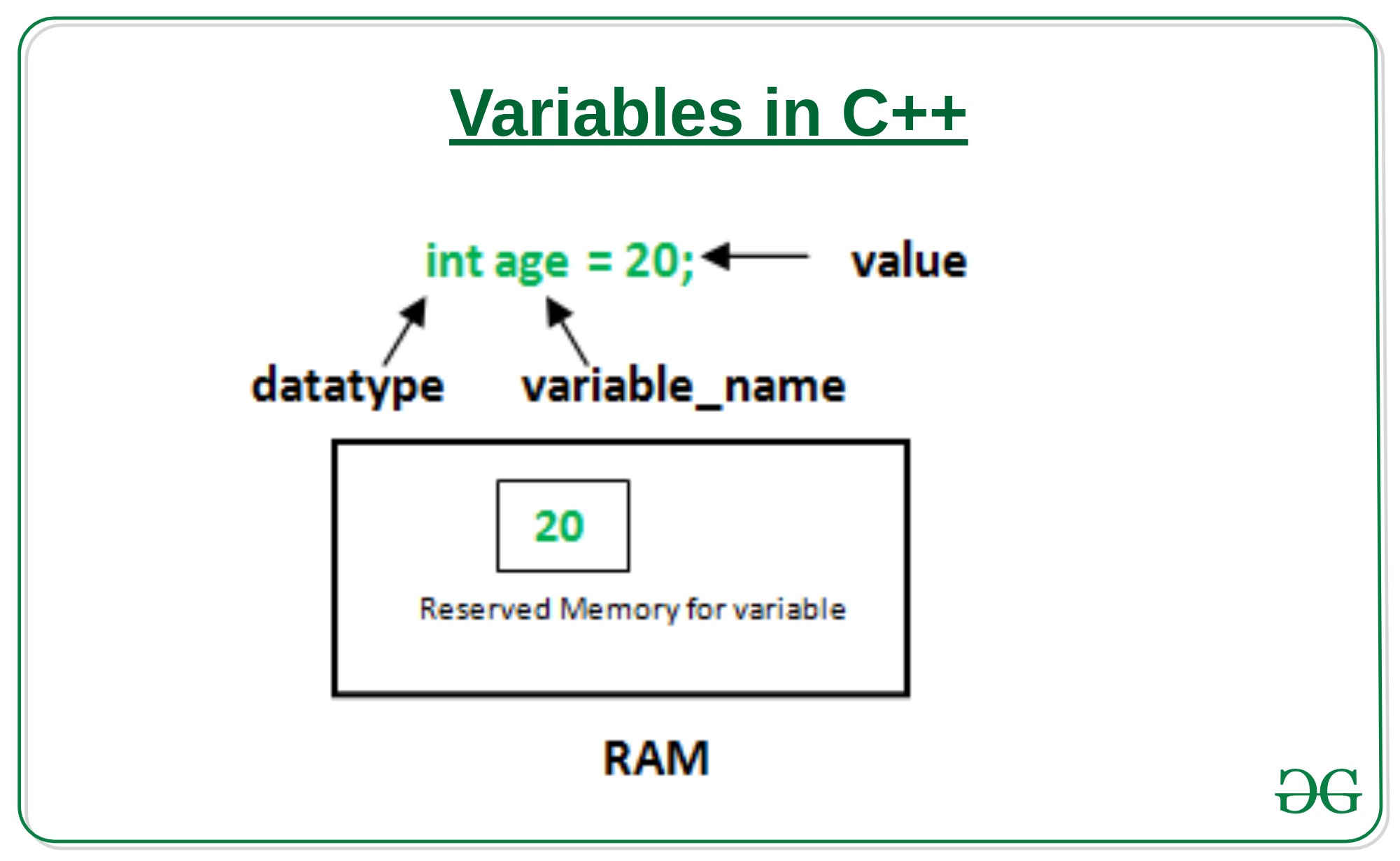
To use a variable effectively, one must understand its three primary components: the identifier (name), the value (the data held), and the data type (the nature of the data). These components define how the computer treats the information and how much space it allocates in memory.
Identifying Data via Naming (Identifiers)
The name of a variable, known as an identifier, is how developers interact with the data. Choosing clear, descriptive names is a hallmark of professional software engineering. In a tech environment where teams collaborate on massive codebases, a variable named u_email is significantly more useful than one named x. Most programming languages have strict rules for identifiers: they usually cannot start with a number, cannot contain spaces, and are often case-sensitive.
Data Types: The Taxonomy of Information
Not all data is created equal. A computer needs to know whether it is dealing with a whole number, a decimal, a single letter, or a sequence of characters. This classification is known as a “Data Type.” Common types include:
- Integers: Whole numbers (e.g., 5, -42).
- Floats/Doubles: Numbers with decimal points (e.g., 3.14).
- Strings: Sequences of characters or text (e.g., “Hello, Tech World”).
- Booleans: Binary logic gates representing either
TrueorFalse.
By defining the type, the program knows which operations are valid. For example, you can multiply two integers, but you cannot logically multiply a string by a boolean.
Static vs. Dynamic Typing
In the tech world, languages are often categorized by how they handle variable types. “Statically typed” languages like C++ or Java require the programmer to declare the type of the variable explicitly before using it. This leads to safer, more predictable code. On the other hand, “dynamically typed” languages like Python or JavaScript determine the type at runtime based on the value assigned. This allows for faster prototyping and greater flexibility, which is why these languages are dominant in AI tools and web development.
The Life Cycle of a Variable: From Declaration to Deletion

A variable does not exist indefinitely. It follows a lifecycle that mirrors the execution of the program. Understanding this cycle is crucial for optimizing digital security and system performance, as “orphaned” variables can lead to memory leaks or vulnerabilities.
Declaration and Initialization
The life of a variable begins with Declaration, where the programmer tells the system, “I will need a variable named X.” This is followed by Initialization, which is the process of assigning an initial value to that variable. In many modern languages, these two steps happen simultaneously. For instance, in Python, writing price = 19.99 both declares the variable and initializes it with a float value.
Understanding Scope: Local vs. Global
“Scope” refers to the region of a program where a variable is accessible.
- Local Variables: These exist only within a specific function or block of code. Once the function finishes its task, the variable is deleted. This is critical for security; it ensures that sensitive data (like a password) doesn’t linger in memory longer than necessary.
- Global Variables: These are accessible from anywhere in the program. While powerful, tech professionals generally avoid overusing them because they can lead to “spaghetti code,” where it becomes impossible to track which part of the software changed a specific value.
Memory Management and Garbage Collection
As software grows in complexity, managing the “death” of a variable becomes a technical challenge. High-level languages utilize a “Garbage Collector”—a background process that identifies variables that are no longer being used and frees up their memory for other tasks. In low-level systems programming (like building an operating system or a high-speed gadget), developers must manually “deallocate” memory, requiring a deep understanding of the variable’s lifecycle.
Best Practices for Using Variables in Software Development
Writing code is an art as much as a science. As technology trends shift toward “Clean Code” and maintainable software, how a developer handles variables can determine the success of a project.
Meaningful Naming Conventions
Tech teams utilize specific naming conventions to keep code readable.
- CamelCase: Used frequently in Java and JavaScript (e.g.,
userAccountBalance). - Snake_case: Common in Python and Ruby (e.g.,
user_account_balance). - PascalCase: Often used for class names (e.g.,
UserAccount).
Consistent naming ensures that when a new developer joins a project, they can understand the logic of the software without needing an external manual.
Minimizing Side Effects with Constants
Sometimes, you need a variable that doesn’t change. In programming, these are called “Constants.” For example, if you are building an app that calculates sales tax, you might set a constant TAX_RATE = 0.07. By using constants, you prevent accidental changes to critical data elsewhere in the program, making the software more robust and less prone to bugs.
The Role of Variables in Modern AI and Data Science
In the current era of AI tools and Big Data, variables have taken on even greater significance. They are no longer just simple storage units; they are the building blocks of complex algorithms and neural networks.
Variables as Parameters in Machine Learning
In Machine Learning (ML), variables are often referred to as “parameters” or “weights.” An AI model, such as a Large Language Model (LLM), consists of billions of these variables. During the training process, the AI adjusts these variable values to improve its accuracy. In this context, a variable isn’t just a piece of data—it is a “knob” that the computer turns to learn how to recognize a human face or translate a language.
Handling Large-Scale Data Sets
In Data Science, developers use “Arrays” or “DataFrames,” which are essentially variables that hold thousands or millions of individual values at once. Modern tech tools like Apache Spark or Pandas allow researchers to perform a single operation on a variable containing an entire database’s worth of information. This scalability is what allows apps like Spotify or Netflix to provide personalized recommendations in real-time.
The concept of a variable is the bridge between human logic and machine execution. By mastering how variables work—from their basic definition as memory references to their advanced roles in AI—tech professionals can build software that is faster, more secure, and more intuitive. Whether you are a hobbyist looking at your first line of code or a tech enthusiast curious about how your favorite gadgets function, understanding the humble variable is the key to unlocking the power of technology.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.