In the vast landscape of information technology, the term “parsable” serves as a cornerstone for how machines communicate, how software interprets instructions, and how data is transformed into actionable insights. At its most fundamental level, for something to be “parsable,” it must be capable of being broken down into its constituent parts by a specialized program—a parser—which then analyzes those parts for meaning, structure, and validity.
While the concept might sound academic, it is the invisible force that allows your web browser to render a website from raw HTML, enables your smartphone to understand a voice command, and ensures that financial transactions between different banking servers occur without error. Understanding what makes data parsable is essential for developers, data scientists, and technology enthusiasts alike.
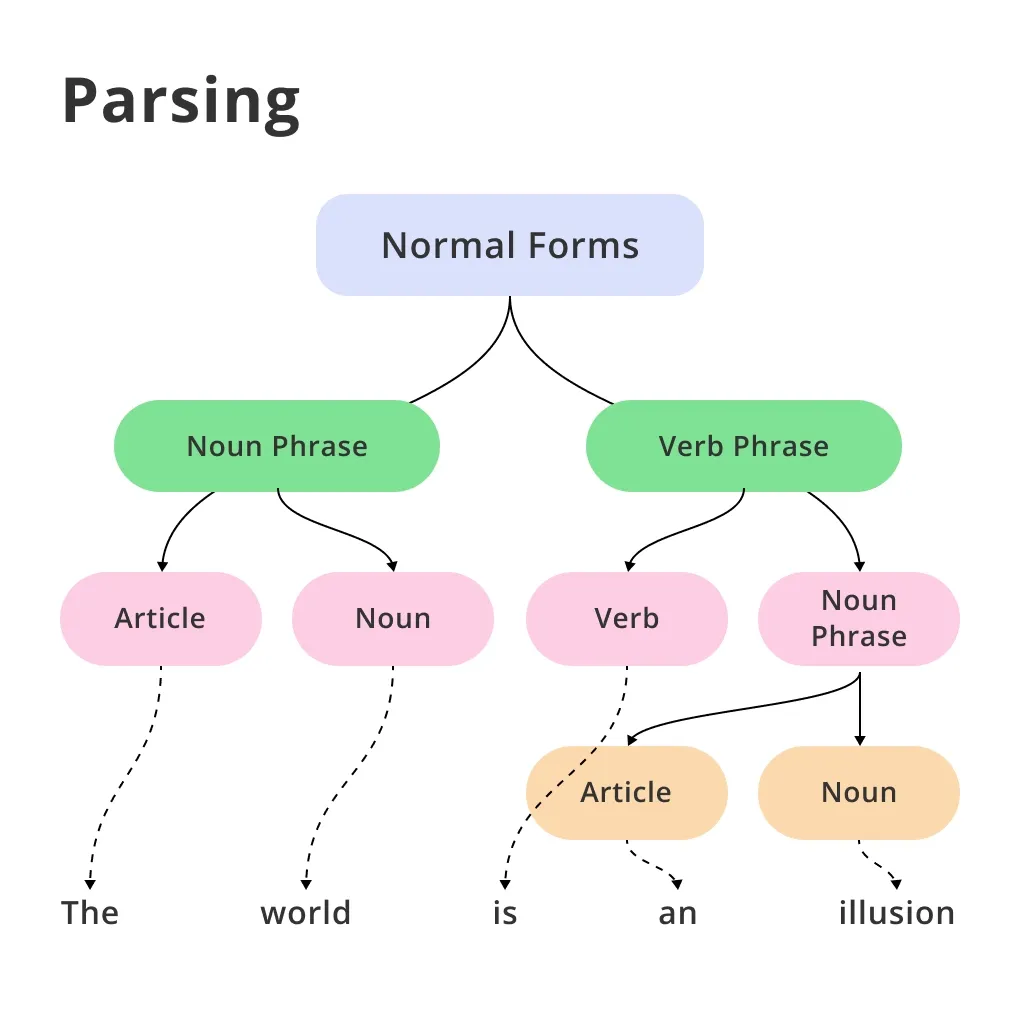
The Mechanics of Parsing: How Machines Read Data
To understand what “parsable” means, one must first understand the act of parsing. Parsing is the process of taking input data (usually text) and building a data structure—often a tree-like representation—that gives a structural representation of the input while checking for correct syntax.
The Difference Between Lexical Analysis and Syntactic Analysis
The process of determining if data is parsable typically happens in two distinct stages. The first is lexical analysis (or “lexing”). During this phase, the parser reads the stream of characters and groups them into meaningful units called “tokens.” For example, in a line of code like x = 5 + 10, the tokens would be x, =, 5, +, and 10.
The second phase is syntactic analysis. This is where the true “parsing” occurs. The parser takes the tokens and determines if they follow the rules of the language’s grammar. If the tokens are arranged in a way that violates these rules (e.g., 5 + = x 10), the data is deemed “unparsable,” and the system throws a syntax error.
From Raw Strings to Abstract Syntax Trees (AST)
When a piece of data is successfully parsed, it is often converted into an Abstract Syntax Tree (AST). The AST is a hierarchical representation of the data that the computer can easily traverse and execute. For a piece of software to be efficient, the data it receives must be easily convertible into this tree format. If the input is ambiguous or poorly structured, the “parsability” score drops, leading to increased computational overhead or outright failure.
Characteristics of Parsable Formats: Why Structure Matters
Not all data is created equal. For information to be considered highly parsable in a professional tech environment, it must adhere to strict formatting standards. This predictability is what allows different software systems to talk to one another without human intervention.
Standardized Formats: JSON, XML, and YAML
In modern software development, several formats have become the industry standard for parsable data.
- JSON (JavaScript Object Notation): Currently the most popular format for web APIs, JSON is prized for being lightweight and easy for both humans to read and machines to parse. Its key-value pair structure makes it incredibly predictable.
- XML (eXtensible Markup Language): Though more verbose than JSON, XML is highly structured and supports complex metadata. It remains a staple in enterprise systems and legacy integrations.
- YAML (YAML Ain’t Markup Language): Often used for configuration files (like those in Docker or Kubernetes), YAML prioritizes human readability while maintaining a strict indentation-based structure that makes it easily parsable by deployment tools.
The Role of Formal Grammars and Schemas
What makes these formats “parsable” is the existence of a formal grammar—a set of rules that define valid sequences of characters. To take it a step further, many tech stacks use “Schemas” (such as JSON Schema or XML XSD). A schema provides a blueprint for the data. It doesn’t just ask, “Is this valid JSON?” but rather, “Does this JSON contain the required ‘User_ID’ field as an integer?” When data adheres to a schema, its parsability becomes a guarantee of data integrity.
The Practical Importance of Parsability in Software Engineering
In the realm of software engineering, parsability is synonymous with reliability. If a system receives data that it cannot parse, the result is often a system crash, a security vulnerability, or a corrupted database.
API Communication and Data Exchange
Modern software architecture relies heavily on microservices—small, independent programs that work together. These services communicate via APIs (Application Programming Interfaces). For this communication to work, the “request” sent by one service and the “response” sent by another must be perfectly parsable.

If a third-party API changes its data structure without notice—perhaps by changing a date format from YYYY-MM-DD to DD-MM-YYYY—the receiving system may find the data unparsable. This highlights why versioning and strict documentation are critical in the tech industry: they ensure that the data remains “parsable” across different versions of a product.
Configuration Management and Scripting
Parsability is also vital in DevOps and system administration. Infrastructure as Code (IaC) tools like Terraform or Ansible rely on parsing configuration files to build entire cloud environments. If a single bracket is missing or an indentation is off, the file becomes unparsable. In this context, parsability is the gatekeeper of automation; without it, the scale at which modern cloud providers operate would be impossible to manage.
Parsability in the Age of AI and Natural Language Processing
One of the most exciting frontiers in technology is the attempt to make “unstructured data”—such as the human voice or handwritten notes—parsable for computers. This is the domain of Natural Language Processing (NLP).
Teaching Machines to Parse Human Language
Unlike a computer language, human language is messy, filled with slang, sarcasm, and ambiguous meanings. For an AI to understand the sentence “The fruit bats eat,” it must parse whether “fruit” is an adjective describing the bats or the object being eaten.
Modern AI tools and Large Language Models (LLMs) like GPT-4 use advanced probabilistic parsing. They don’t just look for strict grammatical rules; they use massive datasets to predict the structure of a sentence. Making human language “parsable” for a machine is the breakthrough that has allowed for the rise of virtual assistants and automated translation services.
The Challenges of Ambiguity and Context
The main obstacle to parsability in AI is context. In a programming language like Python, the word print always means the same thing. In human language, “bank” could mean a financial institution or the side of a river. For an AI to truly parse this data, it must look at the surrounding tokens to determine the most likely structure. The more “parsable” we can make human input through better algorithms, the more seamlessly we can interact with our devices.
Best Practices for Creating Parsable Systems
Whether you are a developer designing an API or a data analyst organizing a spreadsheet, ensuring your output is parsable is a professional necessity. Poorly structured data creates “technical debt,” requiring more code and more processing power to clean up later.
Prioritizing Consistency and Validation
The first rule of parsability is consistency. If you are logging errors, use a consistent timestamp format. If you are exporting a CSV, ensure that every row has the same number of columns.
Furthermore, “fail-fast” validation is a best practice in software design. Instead of trying to work with potentially unparsable data, a system should validate the data against a schema the moment it is received. If the data doesn’t fit the expected structure, it should be rejected immediately. This prevents the “garbage in, garbage out” syndrome that plagues many complex systems.
Tools and Libraries for Efficient Parsing
Developers rarely write parsers from scratch today. Instead, they use optimized libraries tailored for specific formats. For example, Python’s json module or Java’s Jackson library are highly optimized for speed and security. Utilizing these standard tools ensures that your application handles parsable data in a way that is compliant with industry standards, reducing the risk of security exploits like “injection attacks,” where malicious code is hidden inside seemingly parsable data.

Conclusion
In conclusion, “parsable” is more than just a technical jargon term; it represents the bridge between raw, chaotic data and organized, useful information. In the tech niche, something is parsable when it respects the rules of its specific “language,” allowing a computer to dissect it, understand it, and act upon it.
As we move deeper into an era defined by Big Data and Artificial Intelligence, the ability to create, maintain, and interpret parsable structures will remain the backbone of technological innovation. From the simplest configuration file to the most complex neural network, the quest for parsability is what allows us to turn the noise of the digital world into a symphony of structured logic.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.