In the rapidly evolving landscape of technology, the ability to interpret information accurately is what separates high-performing systems from those that fail to scale. At the heart of this interpretation lies the concept of data distribution. While most people are familiar with the “Bell Curve” or normal distribution, the digital age has introduced more complex patterns. One of the most significant and often misunderstood patterns is bimodal data.
In the tech sector—spanning software engineering, artificial intelligence, and digital security—recognizing bimodal data is crucial. It reveals hidden structures within datasets that a simple average would completely obscure. This article explores the technical nuances of bimodal data, its implications for machine learning, and its role in optimizing modern digital infrastructure.

Decoding the Bimodal Distribution: The Technical Foundation
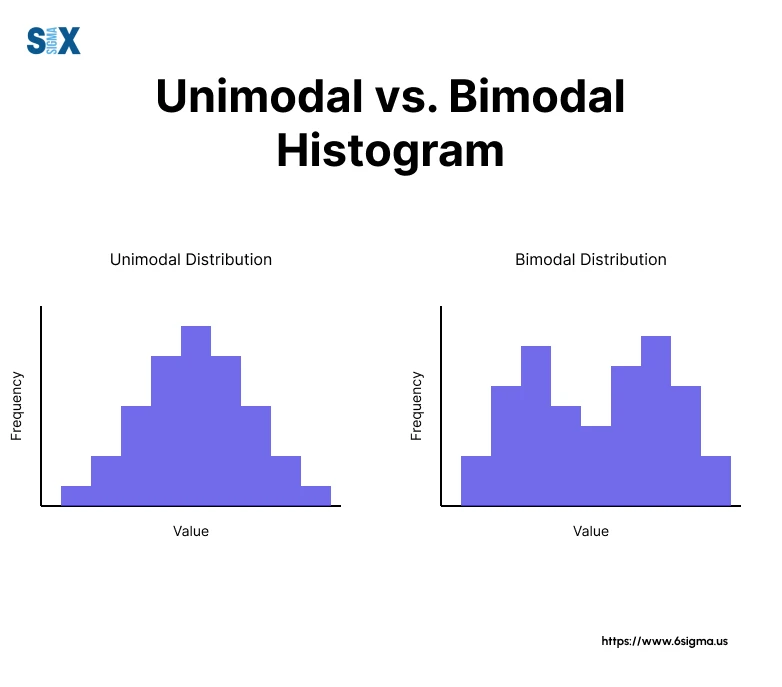
To understand bimodal data, one must first look at the frequency distribution of a dataset. In a standard unimodal distribution, there is one clear peak (the mode) where most data points cluster. In contrast, a bimodal distribution features two distinct peaks. These peaks represent two different “most frequent” values or ranges, separated by a valley.
Understanding the “Twin Peaks” Phenomenon
Mathematically, a bimodal distribution suggests that the population being sampled is not homogeneous. In technology, this often indicates that your dataset is actually a combination of two distinct groups that have been merged into one. For example, if a software engineer analyzes the “latency” of a global application, they might see one peak representing users on high-speed fiber connections and another peak representing users on 3G mobile networks.
If the engineer were to simply calculate the “average” latency, they would end up with a number that represents neither group accurately. This is known as the “flaw of averages.” In a bimodal set, the mean often falls in the “valley” between the peaks—a value that almost no actual user experiences.
Bimodal vs. Unimodal vs. Multimodal
While unimodal distributions (like the Gaussian distribution) are the bedrock of classical statistics, the digital world is increasingly multimodal. Multimodal data has more than two peaks, suggesting even higher levels of complexity. However, bimodal data is the most common “complex” distribution encountered in tech.
Distinguishing between these is vital for data integrity. In a tech stack, treating bimodal data as unimodal can lead to “over-smoothing,” where the nuances of specific user behaviors or system states are lost. Identifying the “bi” in bimodal allows developers to split the data and optimize for each peak individually.
Why Bimodal Data Matters in Software Development and AI
In the realms of Software-as-a-Service (SaaS) and Artificial Intelligence, bimodal data is more than a statistical curiosity; it is a roadmap for product optimization and algorithmic accuracy.
Data Preprocessing for Machine Learning
For AI and Machine Learning (ML) engineers, bimodal data presents a unique challenge during the feature engineering and preprocessing stages. Most standard ML algorithms—especially linear regression—assume that the underlying data follows a normal distribution. When presented with bimodal input, these models often struggle to converge or produce highly inaccurate predictions.
To solve this, tech professionals utilize “Gaussian Mixture Models” (GMMs). Instead of trying to fit one curve to the data, a GMM assumes that there are two (or more) hidden subpopulations, each with its own distribution. By identifying these two peaks, engineers can “cluster” the data, allowing the AI to recognize that it is dealing with two different types of entities. This leads to much higher precision in recommendation engines, predictive maintenance, and natural language processing.
Identifying User Behavioral Segments in SaaS
From a product tech perspective, bimodal data often reveals a “Power User” vs. “Casual User” split. If you analyze the “Time Spent in App” for a productivity tool, you will often find a bimodal distribution.
- Peak A: Casual users who log in for 2–5 minutes to check a notification.
- Peak B: Power users who keep the app open for 4–8 hours a day.
If the product team tries to build a single UI that caters to the “average” time spent, they will likely frustrate both groups. By identifying the bimodal nature of the engagement data, the engineering team can implement “Adaptive UIs”—offering a simplified view for the casual peak and a feature-rich “Pro” dashboard for the power-user peak.
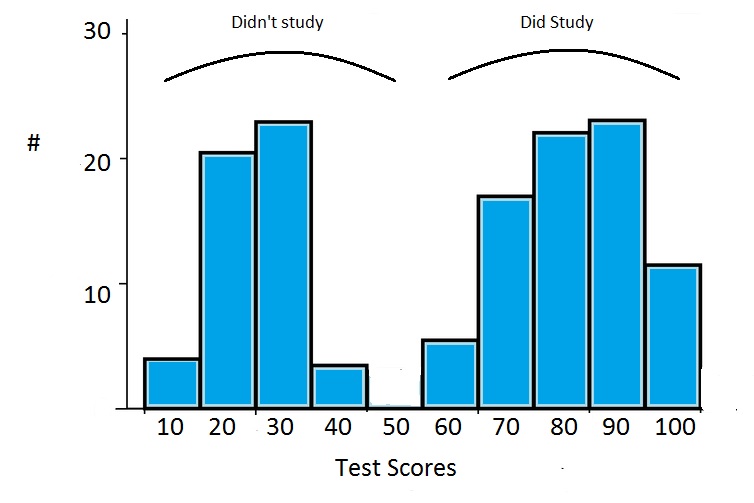
Applications in Digital Security and Network Monitoring
In the world of cybersecurity and IT infrastructure, bimodal data serves as a vital diagnostic tool. When systems are running optimally, their performance metrics usually follow a predictable pattern. A shift toward a bimodal distribution can be an early warning sign of trouble.
Detecting Anomalies through Distribution Shifts
Security Information and Event Management (SIEM) tools often monitor network traffic volume. In a healthy environment, traffic might follow a unimodal distribution based on office hours. However, during a distributed denial-of-service (DDoS) attack or a data exfiltration event, the distribution often becomes bimodal.
The first peak represents legitimate, baseline traffic, while the second, higher-intensity peak represents the malicious activity. By using algorithmic thresholding that accounts for bimodality, security software can automatically flag the second peak as an anomaly. This is far more effective than simple “limit-based” alerts, which often trigger false positives during legitimate peak usage times.
Traffic Analysis in Enterprise Systems
Hardware and cloud engineers use bimodal analysis to manage server loads. In cloud computing, “Read/Write” operations often show bimodal patterns. Smaller “Read” operations happen frequently and quickly (Peak 1), while larger, intensive “Write” or “Backup” operations happen less frequently but consume more resources (Peak 2).
By recognizing this bimodal distribution, cloud architects can implement “Tiered Storage” or “Load Balancing” strategies. They can route the “High-Frequency/Low-Payload” traffic through one set of optimized microservices and the “Low-Frequency/High-Payload” traffic through another. This ensures that the heavy processes do not bottleneck the quick responses, optimizing the overall Quality of Service (QoS).
Visualizing and Managing Bimodal Datasets
Knowing that data is bimodal is only half the battle; the other half is communicating that reality through data visualization and managing it through appropriate statistical tools.
Effective Charting: Beyond the Standard Mean
In tech reporting, the bar chart or the simple line graph can sometimes hide bimodality. To truly see the two peaks, data scientists rely on Histograms and Violin Plots.
- Histograms: By adjusting the “bin width,” a histogram clearly displays the two humps of a bimodal set.
- Violin Plots: These are particularly popular in tech tutorials and research because they combine a box plot with a kernel density plot. The “width” of the violin shows where the data clusters, making the two peaks of a bimodal set instantly visible to stakeholders.
For a CTO or a Lead Dev, seeing a violin plot with two distinct “bulges” is a signal to stop looking at the median and start looking at the segmentation.
Statistical Strategies for Accuracy
When a tech team identifies bimodal data, they must change their analytical approach. Standard deviation, for example, becomes misleading in a bimodal set because the “spread” is calculated from a mean that doesn’t actually exist in the real world.
Instead, the strategy should be “Stratification.” This involves breaking the dataset into two distinct subsets based on the identified modes. Once the data is stratified, the team can perform unimodal analysis on each subset. In software testing, this might mean running separate performance benchmarks for “Legacy Systems” and “Next-Gen Systems” rather than averaging the two, ensuring that the software is optimized for the specific constraints of each environment.
Conclusion: The Strategic Importance of Bimodal Insights
As we move deeper into the era of Big Data and autonomous systems, the complexity of our information will only increase. Bimodal data is a reminder that the world is rarely “average.” In the tech industry, where precision is the currency of success, failing to account for the “twin peaks” of a distribution can lead to flawed AI models, poor user experiences, and vulnerable security frameworks.
By embracing the reality of bimodal data, technology professionals can build more nuanced, responsive, and robust systems. Whether you are an ML engineer tuning a model, a DevOps specialist monitoring a network, or a Product Manager analyzing user behavior, the ability to see beyond the mean and identify the underlying peaks is a superpower. In a world of data, don’t just look at the middle—look at the peaks, and you’ll find the true story of your technology.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.