In the world of enterprise software architecture, we often encounter components that mirror biological organs. Some are the heart of the system—the central processing units and primary databases that keep the lifeblood of data flowing. Others are the brain—the AI logic and decision-making engines. However, there is a specific class of legacy services that function much like the human gallbladder: they serve a purpose, often related to storage, caching, or intermediate processing, but they are not strictly “vital” for the system’s survival.
When these components become “inflamed”—characterized by high technical debt, frequent outages, or compatibility bottlenecks—the CTO must make a surgical decision: the removal of the legacy service. This article explores the technological repercussions, system adaptations, and long-term optimization strategies that occur in a high-scale environment after a “digital gallbladder” is removed.
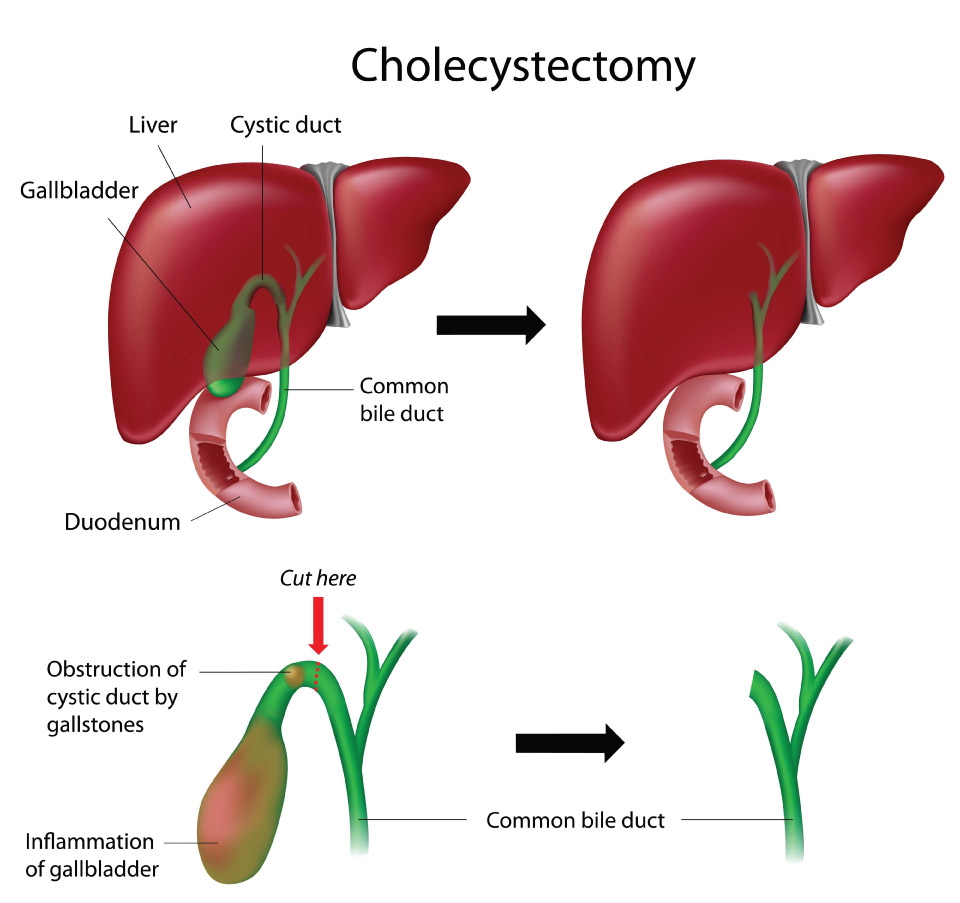
1. The Anatomy of Tech Debt: Identifying the Digital Gallbladder
In a technical ecosystem, a “gallbladder” component is typically a legacy intermediary. It might be an outdated caching layer, a specialized file-storage microservice that has been superseded by cloud-native solutions, or a middleware component that once optimized data flow but now merely adds latency.
Understanding the “Storage Tank” Metaphor
In human biology, the gallbladder stores bile to help digest fats. In technology, these components often store state or metadata to assist the primary database (the liver) in delivering information to the frontend (the digestive tract). When we remove this component, the system loses its “buffer.” The data flow becomes direct. Understanding why this component became redundant is the first step in a successful “cholecystectomy” of your software stack.
The Symptoms of Systemic Failure
Before removal, these legacy components often exhibit “stones”—hardened blocks of unmaintainable code or proprietary formats that no longer integrate with modern APIs. These symptoms include:
- Increased Latency: The “organ” takes longer to process requests than a direct connection would.
- Security Vulnerabilities: Older components often lack the patches and encryption standards required by modern security protocols.
- Scaling Bottlenecks: While the rest of the cloud environment scales horizontally, the legacy component remains a vertical monolith, threatening to crash the entire system under load.
The Decision to Decommission
The move toward “serverless” and “stateless” architectures often renders these intermediary components obsolete. The decision to remove them is rarely about cost alone; it is about reducing the “blast radius” of potential failures. By identifying which services are non-essential “storage tanks,” architects can begin the process of streamlining the codebase.
2. The Surgery: Strategic Decoupling and the Risks of Systemic Shock
Removing a core, albeit non-vital, component from a production environment is a complex engineering feat. It requires more than just deleting a repository or turning off a server; it requires a surgical approach to decoupling.
Decoupling Dependencies
The greatest risk during the removal of a legacy component is “referred pain”—a failure in a seemingly unrelated part of the system. To prevent this, engineers must map out every dependency.
- API Refactoring: Transitioning from the legacy service’s proprietary endpoints to standardized REST or GraphQL interfaces.
- Traffic Shadowing: Running the new architecture in parallel with the old one to ensure that the “body” (the system) can handle the data flow without the gallbladder’s assistance.
Managing the “Bile” (Data Migration)
If the component being removed was responsible for caching or intermediate data transformation, that “bile” must now be handled elsewhere.
- Direct-to-Consumer Data: In many modern architectures, the “liver” (main database) is powerful enough to handle the “digestion” (querying) directly.
- Edge Computing: Offloading the Gallbladder’s tasks to the edge (Cloudflare Workers, Lambda@Edge) allows for faster processing without the need for a centralized intermediary service.
Post-Operative Monitoring and Observability
Once the component is removed, the system enters a critical “recovery” phase. This is where observability tools like Datadog, New Relic, or Prometheus become essential. Engineers must monitor for “Post-Cholecystectomy Syndrome” in the tech stack—instances where the system struggles to adapt to the absence of the buffer, leading to spikes in CPU usage or memory leaks in the primary database.
3. Re-routing the Flow: Data Digestion in a Post-Legacy Environment
What happens once the gallbladder is gone? In a human, the liver secretes bile directly into the small intestine. In a tech stack, the primary data source now communicates directly with the consumer or through a much thinner abstraction layer. This shift necessitates a change in how the system “digests” information.
Transitioning to Statelessness
The most significant change after removing a legacy state-management component is the transition to a stateless architecture. Without the “storage tank,” each request must carry its own context or retrieve it directly from the primary source.
- JWT and Session Management: Moving session storage from a legacy local cache to a distributed Redis cluster or using stateless JSON Web Tokens (JWT).
- Event-Driven Architecture: Implementing Kafka or RabbitMQ to ensure that even without the intermediate “buffer,” data packets reach their destination through a robust, asynchronous messaging system.
Adapting the “Digestive” Load
The primary database often feels the initial strain of the gallbladder’s removal. Without the intermediary to pre-process or “concentrate” the data, the database must be optimized for a higher volume of smaller queries.
- Indexing Strategies: Updating database indexes to handle the new query patterns that were previously masked by the legacy cache.
- Read Replicas: Deploying read replicas to distribute the load that was once managed by the intermediate service.
The Role of Micro-Caches
While the “gallbladder” (the large, centralized legacy cache) is gone, the system may still need “micro-caches.” This involves implementing localized, short-lived caching at the application level. This ensures that the system doesn’t “over-digest,” leading to performance exhaustion.
4. Long-term Maintenance: Scaling with Leaner Architecture
In the months following the removal of a legacy component, the benefits of a “leaner” architecture begin to manifest. However, just as a patient must adjust their diet after gallbladder surgery, a technical team must adjust their development lifecycle.
Embracing “Low-Fat” Code
A “low-fat” code environment is one where unnecessary abstractions and “just-in-case” storage layers are avoided.
- Continuous Refactoring: Instead of letting components grow into “organs” that are difficult to remove, teams should practice continuous refactoring.
- Modular Design: Ensuring that every new service is “pluggable.” If a service needs to be removed in the future, the “surgery” should be a minor procedure, not a major operation.
The Efficiency Dividend
The removal of legacy “storage tanks” almost always results in a significant reduction in cloud spend and operational overhead.
- Lower Infrastructure Costs: Fewer VMs or containers to manage, lower inter-zone data transfer costs, and reduced licensing fees for legacy software.
- Improved Developer Velocity: New engineers don’t have to learn the quirks of a 10-year-old intermediary service. They can work with modern, direct protocols.
Preparing for Future Decommissioning
The cycle of technology dictates that today’s modern solution is tomorrow’s legacy gallbladder. To maintain systemic health, organizations must establish a “Lifecycle Management” policy. This involves:
- Regular Tech Debt Audits: Identifying components that are becoming more “expensive” to maintain than they are “valuable” to operate.
- Sunset Protocols: Creating a standardized playbook for removing services, ensuring that data is preserved, dependencies are rerouted, and stakeholders are informed.
Conclusion: The Resilience of the Streamlined System
What happens after a gallbladder is removed? The system becomes more direct, more efficient, and ultimately more resilient. While the “surgery” to remove legacy tech components is fraught with risks—from data loss to systemic downtime—the result is a software architecture that is better suited for the demands of modern, high-speed digital commerce.
By viewing legacy components not as permanent fixtures but as biological-style organs that can be outgrown, tech leaders can foster an environment of constant evolution. A system without a gallbladder may have to “eat” (process data) more carefully at first, but in the long run, it runs faster, scales further, and is far less likely to suffer from the chronic pains of technical debt. The key to success lies in the preparation, the precision of the decoupling, and the relentless monitoring of the “patient” during its transition to a leaner, more modern state.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.