At first glance, the intricate world of deoxyribonucleic acid (DNA) and its close relative, ribonucleic acid (RNA), might seem exclusively the domain of biology laboratories. However, the principles governing these fundamental molecules of life, and the technologies that help us understand and manipulate them, surprisingly intersect with the core themes of our digital age: Tech, Brand, and Money. Just as DNA and RNA are the blueprints and messengers for biological systems, understanding their commonalities can shed light on how we build, communicate, and invest in the information that shapes our world, both natural and artificial.

While DNA and RNA are distinct entities with unique roles, their shared heritage and fundamental molecular structures offer a fascinating starting point. They are the very essence of genetic information transfer, the foundation upon which all living organisms are built. By examining their commonalities, we can gain a deeper appreciation for the elegance of biological design and, in turn, draw parallels to the information architectures that power our technological innovations, the branding strategies that define our identities, and the financial systems that fuel our economies.
The Shared Architecture: Unpacking the Nucleotide Foundation
The most profound commonality between DNA and RNA lies in their fundamental building blocks: nucleotides. These are not just random molecules; they are precisely structured units that form the chains of genetic code. Each nucleotide consists of three key components:
- A Phosphate Group: This negatively charged component is crucial for linking nucleotides together, forming the backbone of the nucleic acid strand. Think of it as the essential connector, the recurring element that provides structural integrity.
- A Pentose Sugar: This five-carbon sugar is where DNA and RNA diverge slightly, but the concept of a sugar backbone remains a shared feature. In DNA, it’s deoxyribose; in RNA, it’s ribose. This seemingly small difference has significant implications for their stability and function, but the presence of a sugar in the core structure is a common thread.
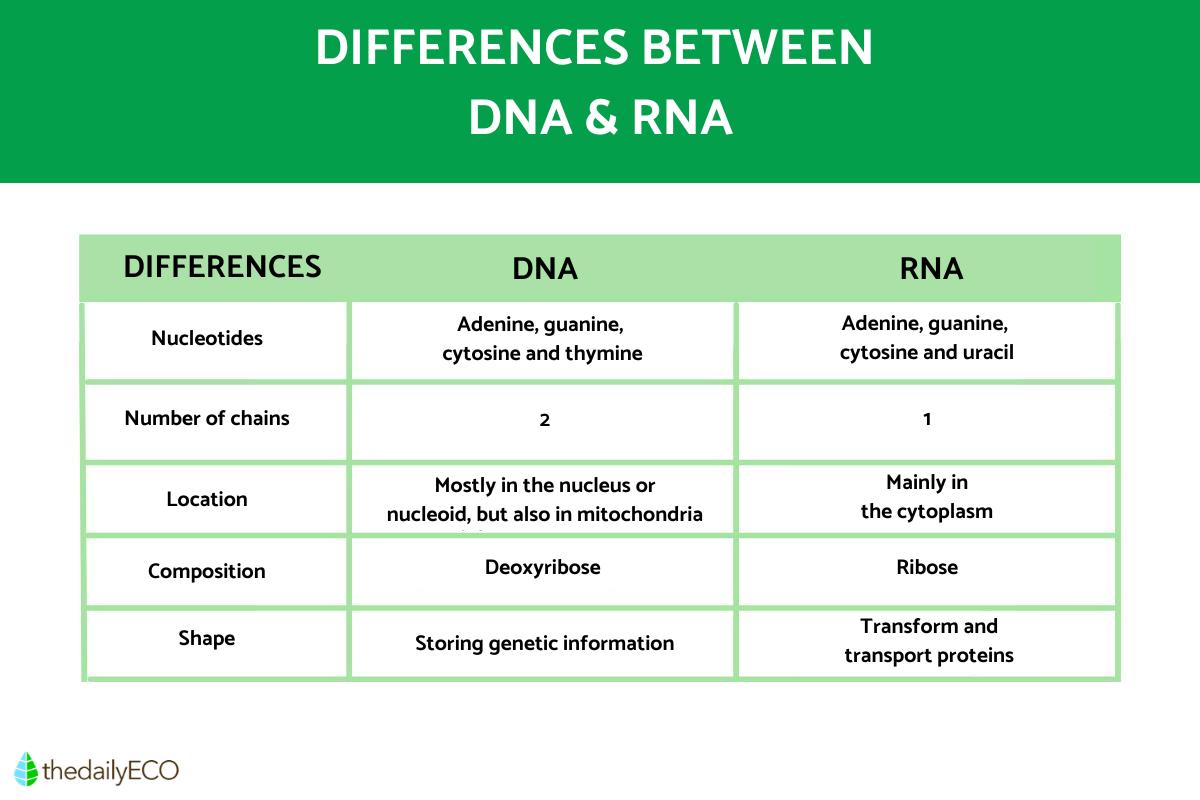
- A Nitrogenous Base: This is the “alphabet” of the genetic code. Both DNA and RNA utilize four distinct nitrogenous bases, although with one key difference.
The Language of Life: Adenine, Guanine, Cytosine, and Thymine/Uracil
The nitrogenous bases are where the magic of information storage happens. Both DNA and RNA share three bases:
- Adenine (A): A purine base, always pairing with its complementary base.
- Guanine (G): Another purine base, also with a specific pairing partner.
- Cytosine (C): A pyrimidine base, part of the fundamental quartet.
The crucial difference emerges with the fourth base. DNA utilizes Thymine (T), another pyrimidine. RNA, however, substitutes Thymine with Uracil (U). This is a critical distinction, influencing how these molecules interact and function, but the underlying principle of using a set of distinct bases to encode information is a powerful commonality.
This shared nucleotide structure, this fundamental chemical language, is the bedrock of their relationship. It’s akin to how different programming languages (like Python and Java) might share common syntax elements or data structures, allowing developers to translate concepts between them. In the realm of Tech, understanding these foundational elements can inform the design of new algorithms, data storage solutions, and even methods for information retrieval.
The Double Helix vs. The Single Strand: Structural Parallels and Divergences
Beyond the individual nucleotide components, the way these nucleotides are organized into larger structures also reveals important commonalities, as well as key differences that dictate their functions.
The Information Carrier: From Blueprint to Messenger
The most significant functional difference between DNA and RNA stems from their typical structural forms.
- DNA: Generally exists as a double helix, two complementary strands wound around each other. This double-stranded structure provides exceptional stability and serves as the master blueprint for all genetic information. The pairing rules (A with T, and G with C) ensure accurate replication and long-term storage of genetic instructions. Think of DNA as the ultimate, unalterable master document.
- RNA: Typically exists as a single strand. While it can fold and interact with itself to form complex three-dimensional structures, it lacks the inherent stability of the double helix. This single-stranded nature makes RNA more dynamic and versatile, allowing it to perform a wider range of functions. RNA acts as a messenger, a builder, a regulator, and even an enzyme. It’s the active participant in translating the DNA blueprint into tangible cellular machinery.
This structural divergence has profound implications. The stability of DNA is crucial for its role as the permanent repository of genetic information, passed down through generations. The transient and adaptable nature of RNA allows it to be the workhorse of the cell, carrying instructions from the nucleus, building proteins, and controlling gene expression.
Implications for Tech and Information Management
The DNA-double helix/RNA-single strand dynamic offers compelling analogies for concepts in Tech. Consider:
- Databases vs. APIs: DNA’s double helix is akin to a robust, well-structured database – the ultimate source of truth, designed for stability and integrity. RNA, in its single-stranded, dynamic form, can be compared to an Application Programming Interface (API) – a flexible interface that allows different systems to access and interact with the data without directly manipulating the underlying database.
- Version Control Systems: In software development, version control systems (like Git) manage different versions of code. DNA is like the master branch, while RNA represents specific feature branches or releases that are actively being worked on and deployed.
- Data Encryption and Security: The double-stranded nature of DNA offers a built-in redundancy and error-checking mechanism. This parallels robust encryption methods where data is encoded and protected, ensuring its integrity and preventing unauthorized access.

The Interplay of Information: Replication, Transcription, and Translation
While DNA and RNA have distinct primary roles, their existence is intrinsically linked through a series of elegant processes that transfer and utilize genetic information. These processes highlight their shared purpose in maintaining and propagating life.
Replication: Copying the Master Blueprint
DNA’s primary function is to replicate itself, ensuring that genetic information is passed accurately from one cell to another during cell division. This process is incredibly precise, relying on the complementary base pairing to create two identical DNA molecules from a single parent molecule.
Transcription: From DNA to RNA
This is where DNA and RNA directly interact. Transcription is the process by which a specific segment of DNA is copied into a complementary RNA molecule. RNA polymerase, an enzyme, reads the DNA sequence and synthesizes a single-stranded RNA molecule. This is akin to making a working copy or a specific instruction manual from the master blueprint. This RNA copy, often messenger RNA (mRNA), then leaves the nucleus (where DNA resides) to carry its genetic message to other parts of the cell.
Translation: RNA’s Role in Protein Synthesis
Once the mRNA reaches the cytoplasm, it encounters ribosomes, which are cellular machinery responsible for translation. Here, the sequence of bases in mRNA is read in groups of three, called codons, and each codon specifies a particular amino acid. Transfer RNA (tRNA) molecules bring the correct amino acids to the ribosome, and they are linked together in the order dictated by the mRNA sequence, forming a protein. This is the ultimate execution of the genetic instructions, turning the coded information into functional molecules that perform a vast array of tasks within the cell.
Parallels in Brand and Marketing
The DNA-RNA information flow offers a powerful framework for understanding Brand strategy and Marketing:
- Brand DNA vs. Marketing Campaigns: The core values, mission, and identity of a brand can be seen as its “Brand DNA” – the fundamental, unchanging essence. Marketing campaigns, advertisements, and social media content are like the “RNA” – the messages and expressions that carry the Brand DNA to the target audience, adapted for different platforms and purposes.
- Content Strategy: A successful content strategy involves creating diverse content formats (blog posts, videos, infographics) that all stem from the core brand message. This is analogous to how RNA can be transcribed into different types of RNA (mRNA, tRNA, rRNA), each serving a specific function in protein synthesis.
- Reputation Management: Just as DNA’s accuracy is crucial for biological health, a brand’s consistent and positive messaging is vital for its reputation. Errors in translation (miscommunication, misleading campaigns) can damage the brand’s integrity, much like a mutation in DNA can lead to disease.
The Economic and Financial Echoes of Genetic Code
While the direct connection to Money might seem less obvious, the principles of information storage, replication, and transmission inherent in DNA and RNA have significant economic and financial implications, particularly in the context of the digital economy and intellectual property.
Information as Capital
In the modern economy, information itself is a valuable commodity. The genetic code, the information contained within DNA and RNA, represents the ultimate form of biological capital. Its understanding and manipulation have led to entire industries in biotechnology, pharmaceuticals, and personalized medicine.
- Intellectual Property: The patents and copyrights associated with genetic sequencing, gene editing technologies (like CRISPR), and drug development are direct manifestations of the economic value placed on understanding and utilizing genetic information. This is akin to how software code, brand assets, and unique business processes are protected as intellectual property.
- Investment in R&D: The ongoing research and development in genomics and molecular biology represent significant investments, driven by the potential for groundbreaking discoveries and profitable applications. This mirrors the investment cycles in Tech, where companies pour capital into developing new AI tools, software, or hardware.
- Personalized Services and Markets: Just as our DNA dictates our individual predispositions and characteristics, leading to personalized medicine, the digital world is moving towards personalized products and services. This is fueled by data (akin to genetic data) and sophisticated algorithms, creating new revenue streams and market segments.
The Cost of Information and its Management
The “cost” of understanding and utilizing genetic information can be high, from expensive sequencing equipment to the specialized expertise required. This resonates with the economic realities of Tech and Business Finance:
- Infrastructure and Tools: Developing and maintaining sophisticated AI tools, cloud infrastructure, or complex software requires significant financial investment. This is directly analogous to the capital expenditure needed for advanced genetic research facilities.
- Data Security and Integrity: Protecting sensitive genetic data is paramount, both ethically and financially. Breaches can lead to severe reputational damage and legal repercussions. This mirrors the immense importance of cybersecurity and data protection in the digital realm, where financial losses from breaches can be catastrophic.
- Efficiency and Optimization: Just as biological systems strive for efficiency in gene expression and protein synthesis, businesses and Tech companies constantly seek to optimize their operations, reduce costs, and maximize output. This can involve leveraging AI for predictive analytics, automating processes, or improving supply chain management – all informed by the efficient principles of information processing.
In conclusion, the seemingly distant realms of DNA and RNA share a profound kinship with the core themes of Tech, Brand, and Money. Their common nucleotide foundation, the parallels in their information-handling strategies, and the economic value derived from their understanding all serve as potent reminders that the principles of information, structure, and function are universal. By examining the commonalities between these molecules of life, we gain a richer perspective on how information shapes our world, from the microscopic to the global, and how these fundamental concepts continue to drive innovation and value creation in our interconnected, data-driven society.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.