Proteins, the workhorses of biology, are fundamental to virtually every process that occurs within living organisms. From catalyzing biochemical reactions to providing structural support and transporting molecules, their diverse functions are underpinned by their intricate three-dimensional structures. At their core, however, proteins are complex macromolecules, and understanding their polymeric nature is key to appreciating their biological significance. The term “polymer” itself hints at this fundamental characteristic: a large molecule composed of repeating structural units, called monomers, linked together. When we ask, “What are the polymers of proteins?”, we are delving into the very building blocks and the assembly process that gives rise to these vital biomolecules.
The Monomeric Units: Amino Acids – The Fundamental Building Blocks
Proteins are, in essence, polymers of amino acids. This statement is the cornerstone of understanding protein structure and function. Amino acids are small organic molecules that share a common structural backbone but differ in their side chains, or R-groups. This variation in R-groups is what gives each of the 20 standard amino acids its unique chemical properties, influencing how it interacts with other amino acids and the surrounding environment.
The Universal Structure of Amino Acids
Every amino acid possesses a central carbon atom, known as the alpha-carbon. Attached to this alpha-carbon are four distinct groups:
- An amino group (-NH2): This is a basic functional group that can accept a proton.
- A carboxyl group (-COOH): This is an acidic functional group that can donate a proton.
- A hydrogen atom (-H): A simple, uncharged atom.
- A side chain (R-group): This is the variable component that differentiates one amino acid from another. It can range from a simple hydrogen atom (in glycine) to complex aromatic rings or chains with various functional groups.
The amphoteric nature of amino acids, meaning they can act as both acids and bases due to the presence of both amino and carboxyl groups, is crucial for their behavior in biological systems, particularly in maintaining pH balance.
The Diverse World of Amino Acid Side Chains
The R-group is the most critical feature of an amino acid, dictating its chemical behavior and, consequently, its role within a protein. These side chains can be broadly categorized based on their properties:
- Nonpolar, Aliphatic Side Chains: These are hydrophobic (water-repelling) and tend to cluster together in the interior of proteins, away from the aqueous environment. Examples include alanine, valine, leucine, isoleucine, and methionine. Glycine, with its simple hydrogen side chain, is unique and allows for greater flexibility in the polypeptide chain. Proline, with its cyclic structure where the side chain is linked back to the amino group, introduces rigidity.
- Polar, Uncharged Side Chains: These are hydrophilic (water-attracting) and can form hydrogen bonds with water molecules and other polar residues in a protein. Examples include serine, threonine, cysteine, asparagine, and glutamine. The sulfhydryl group (-SH) in cysteine is particularly important for forming disulfide bonds, which can stabilize protein structure.
- Aromatic Side Chains: These contain ring structures and can be nonpolar (phenylalanine, tryptophan) or polar (tyrosine). They contribute to hydrophobic interactions and can also participate in pi-pi stacking.
- Positively Charged Side Chains (Basic): These are hydrophilic and carry a net positive charge at physiological pH, allowing them to form ionic bonds with negatively charged residues. Examples include lysine, arginine, and histidine.
- Negatively Charged Side Chains (Acidic): These are hydrophilic and carry a net negative charge at physiological pH, allowing them to form ionic bonds with positively charged residues. Examples include aspartate and glutamate.
This vast diversity in side chain chemistry provides the raw material for the incredible variety of protein structures and functions observed in nature.
The Polymerization Process: Peptide Bonds – The Links in the Chain
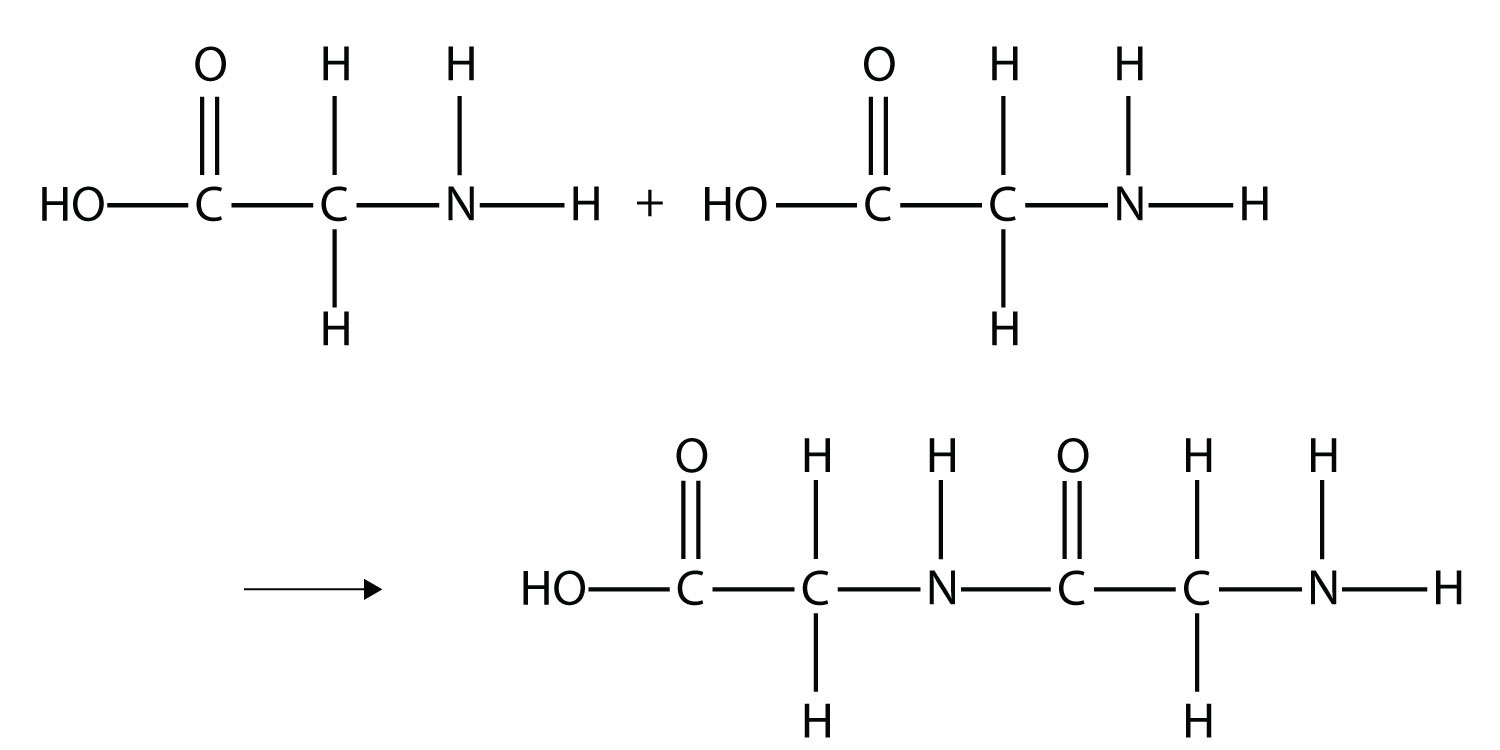
The formation of proteins from amino acids is a process of polymerization, where individual amino acid monomers are linked together covalently. This linkage occurs through a specific type of bond known as a peptide bond. This reaction is a classic example of a dehydration synthesis (or condensation) reaction, where a molecule of water is removed as the bond is formed.
Formation of the Peptide Bond
When the carboxyl group of one amino acid reacts with the amino group of another amino acid, a peptide bond is formed. The hydroxyl (-OH) group is removed from the carboxyl group, and a hydrogen atom (-H) is removed from the amino group, releasing a molecule of water (H2O). The resulting covalent bond links the alpha-carbon of the first amino acid to the alpha-nitrogen of the second amino acid.
The Polypeptide Chain: A Linear Sequence
As this process repeats, a long chain of amino acids linked by peptide bonds is formed. This chain is called a polypeptide. The sequence of amino acids in a polypeptide is determined by the genetic code carried within DNA. This linear sequence is known as the primary structure of the protein. The directionality of the polypeptide chain is defined by the free amino group at one end (the N-terminus) and the free carboxyl group at the other end (the C-terminus).
The Significance of the Peptide Bond
The peptide bond is a relatively stable covalent bond, resistant to hydrolysis under normal physiological conditions. However, it can be broken down by enzymes called proteases during processes like digestion or protein turnover. The planar nature of the peptide bond, due to partial double-bond character, restricts rotation around the bond, influencing the overall folding of the polypeptide chain.
The Hierarchy of Protein Structure: From Linear Chain to Functional Form
While the primary sequence of amino acids is fundamental, it is not the sole determinant of a protein’s function. The polypeptide chain undergoes intricate folding and coiling to adopt a specific three-dimensional structure, which is essential for its biological activity. This hierarchical folding process involves several levels of structural organization.
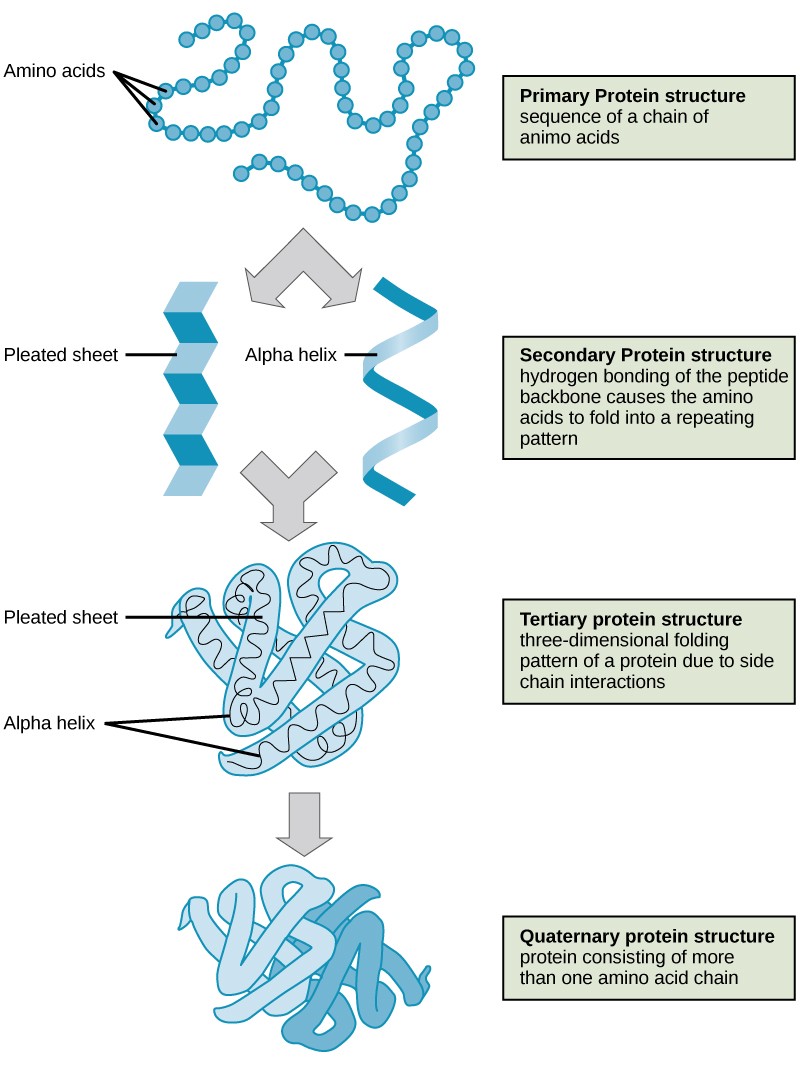
Primary Structure: The Amino Acid Sequence

As discussed, this is the linear order of amino acids in the polypeptide chain, dictated by the gene encoding the protein. Even a single change in the amino acid sequence can dramatically alter a protein’s structure and function, as exemplified by diseases like sickle cell anemia, where a single amino acid substitution in hemoglobin leads to a disease-causing protein.
Secondary Structure: Local Folding Patterns
The polypeptide chain begins to fold into regular, repeating local structures stabilized by hydrogen bonds between backbone atoms (the amino and carboxyl groups, not the side chains). The two most common types of secondary structures are:
- Alpha-helix (α-helix): A coiled, helical structure where the polypeptide backbone forms a spiral, stabilized by hydrogen bonds between the carbonyl oxygen of one amino acid and the amide hydrogen of an amino acid four residues further down the chain.
- Beta-pleated sheet (β-sheet): A sheet-like structure formed by two or more segments of the polypeptide chain lying side-by-side. These segments can be from different parts of the same polypeptide chain or from different polypeptide chains. Hydrogen bonds form between the carbonyl oxygens on one strand and the amide hydrogens on an adjacent strand.
These secondary structures provide local rigidity and shape to different regions of the protein.
Tertiary Structure: The Overall 3D Fold
The tertiary structure refers to the complete, three-dimensional conformation of a single polypeptide chain. It is formed by interactions between the side chains (R-groups) of the amino acids. These interactions are diverse and can include:
- Hydrophobic interactions: Nonpolar side chains cluster in the interior of the protein, away from water.
- Ionic bonds (salt bridges): Attractions between oppositely charged side chains.
- Hydrogen bonds: Interactions between polar side chains and also between side chains and the polypeptide backbone.
- Disulfide bonds: Covalent bonds formed between the sulfur atoms of two cysteine residues, strongly stabilizing the folded structure.
- Van der Waals forces: Weak attractions between transiently polarized atoms.
The tertiary structure is the biologically active form of many proteins, allowing them to bind to specific molecules and carry out their functions.
Quaternary Structure: The Assembly of Multiple Polypeptides
Some proteins are composed of more than one polypeptide chain. The arrangement of these individual polypeptide subunits, called monomers, to form a functional complex is known as the quaternary structure. These subunits are held together by the same types of non-covalent interactions and sometimes disulfide bonds that stabilize tertiary structure. Hemoglobin, the oxygen-carrying protein in red blood cells, is a classic example of a protein with quaternary structure, consisting of four polypeptide subunits.
The Functional Significance of Protein Polymers
The polymeric nature of proteins, from their amino acid monomers to their complex three-dimensional structures, is the foundation of their incredible functional diversity. The ability to assemble into specific shapes allows proteins to perform a vast array of tasks essential for life.
Enzymes: Catalysts of Life
The precise three-dimensional structure of enzymes creates active sites, specific pockets where substrate molecules bind and undergo chemical transformations. The amino acid sequence and arrangement within the active site are critical for catalytic efficiency and specificity.
Structural Proteins: The Scaffolding of Cells and Tissues
Proteins like collagen and keratin form the structural framework of cells, tissues, and organs. Their elongated, fibrous structures, often stabilized by extensive cross-linking, provide strength and resilience.
Transport Proteins: Moving Molecules
Proteins embedded in cell membranes, such as ion channels and transporters, facilitate the movement of specific molecules across these barriers. Their structures are designed to recognize and bind to particular substances, controlling their passage.
Signaling Molecules: Communication Networks
Hormones like insulin and receptors on cell surfaces are proteins that play crucial roles in intercellular communication. Their shapes allow them to bind to specific signaling molecules, triggering cellular responses.
Antibodies: The Immune System’s Defense
Antibodies, a type of protein, are responsible for recognizing and neutralizing foreign invaders like bacteria and viruses. Their highly variable amino acid sequences in specific regions allow them to bind with exquisite specificity to diverse antigens.
In conclusion, proteins are indeed polymers, built from amino acid monomers linked by peptide bonds. This fundamental polymeric structure, however, undergoes a remarkable hierarchy of folding, resulting in diverse three-dimensional shapes that underpin their extraordinary range of biological functions. Understanding the journey from simple amino acids to complex, functional protein polymers is essential for comprehending the intricate mechanisms of life itself.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.