In the rapidly evolving landscape of modern technology, progress is rarely the result of mere coincidence or sudden strokes of genius. Instead, the most groundbreaking advancements—from generative artificial intelligence to decentralized blockchain architectures—are built upon the bedrock of systematic inquiry. The scientific process, a structured methodology for gathering knowledge and testing theories, has transitioned from the physical laboratory to the digital ecosystem. For software engineers, data scientists, and hardware developers, these five steps serve as a roadmap for turning abstract ideas into reliable, scalable, and secure technological solutions.
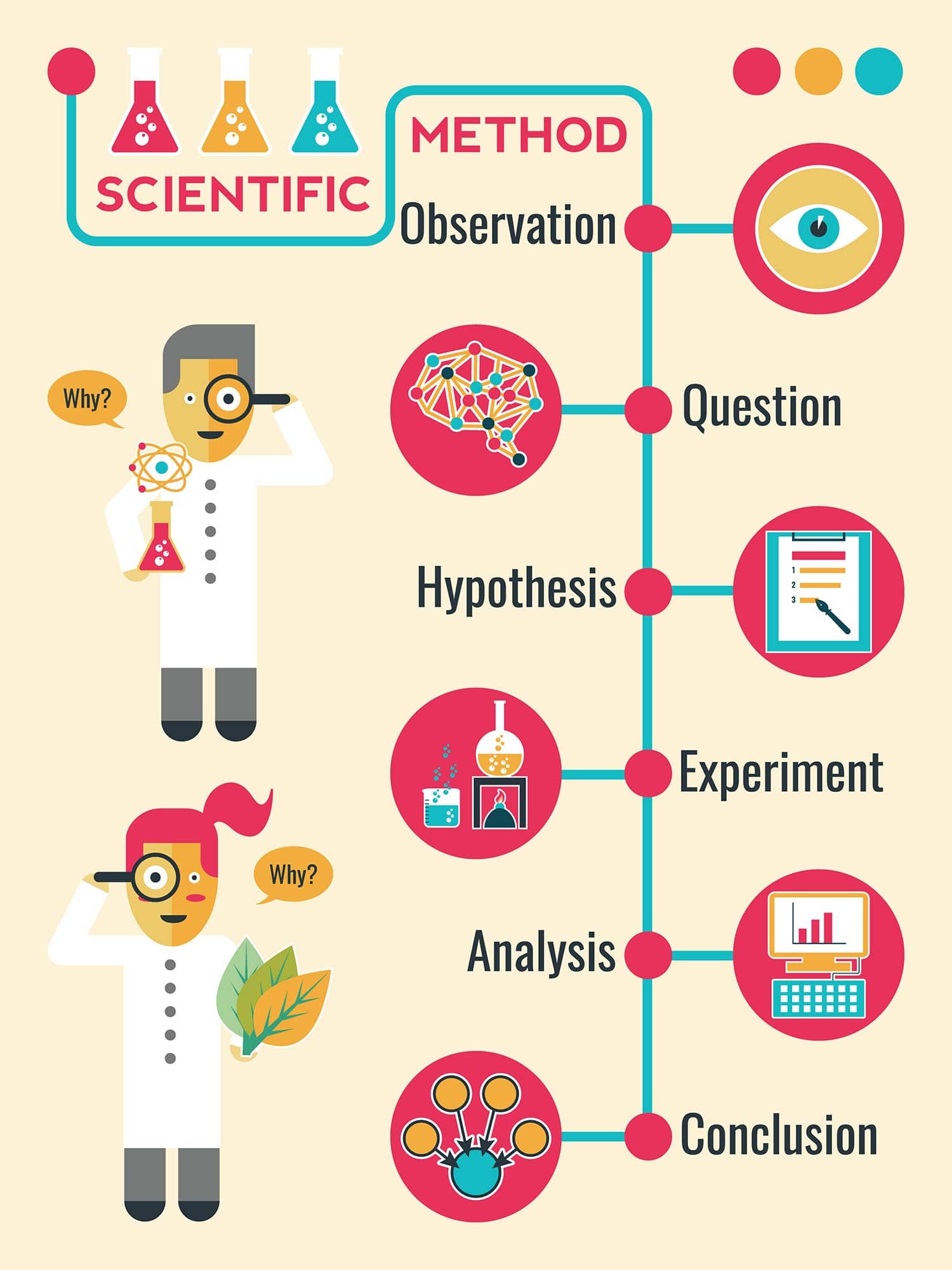
By applying the rigor of the scientific method to tech development, organizations can move beyond “trial and error” and toward a culture of evidence-based innovation. This approach minimizes technical debt, optimizes user experience, and ensures that the tools we build are capable of solving the complex problems of the 21st century.
1. Observation: Identifying the “Why” Behind Tech Development
The first step of the scientific process is observation. In the world of technology, this involves a deep dive into data, user behavior, and existing system limitations. It is the phase where developers and engineers identify a problem that needs solving or a gap in the current technological market.
Identifying Pain Points in User Experience and System Performance
Technological observation often begins with telemetry and analytics. Whether a developer is looking at high bounce rates on a web application or a system architect is noticing latency issues in a cloud infrastructure, observation provides the raw material for innovation. By monitoring how users interact with software or how hardware performs under stress, tech professionals can pinpoint exactly where a system fails to meet its objectives. This data-driven observation ensures that the subsequent steps are focused on real-world problems rather than theoretical non-issues.
Market Gaps and the Search for Disruption
Observation isn’t limited to looking at what is broken; it also involves looking at what is missing. The rise of AI tools like Large Language Models (LLMs) began with the observation that traditional natural language processing was insufficient for complex human-like reasoning. By observing the limitations of existing algorithms, researchers were able to identify the specific areas where a new approach was required. In a tech context, this step requires a blend of competitive analysis, trend tracking, and empathetic user research.
2. Hypothesis: Formulating Data-Driven Solutions
Once a problem has been observed and defined, the next step is to propose a hypothesis. In a tech niche, a hypothesis is essentially a “predicted solution” or an “informed guess” about how a specific change will impact a system. It takes the form of an “If-Then” statement: “If we implement X technology, then Y outcome will occur.”
The Logic of “If-Then” in Software and AI
A well-constructed hypothesis in technology must be testable and falsifiable. For example, a data scientist might hypothesize: “If we transition our recommendation engine from a collaborative filtering model to a neural network-based approach, then user engagement will increase by 15%.” This statement provides a clear metric for success and a specific technological path to follow. Without a clear hypothesis, tech projects often suffer from “scope creep,” where the goals of the project become blurred and the development team loses focus.
Risk Assessment and Theoretical Modeling
Before moving to the experimentation phase, tech leaders must use their hypothesis to perform a preliminary risk assessment. This involves theoretical modeling—predicting how the proposed solution will interact with existing digital security protocols, API integrations, and legacy code. In this stage, the hypothesis is refined through peer reviews and technical design documents, ensuring that the proposed tech solution is not only innovative but also architecturally sound.

3. Experimentation: The Engine of Software Engineering and Prototyping
Experimentation is where the hypothesis meets reality. In the tech industry, this is often the most resource-intensive phase, involving the creation of prototypes, Minimum Viable Products (MVPs), and rigorous testing environments. Unlike traditional science, tech experimentation often happens in “sandboxes”—isolated environments where code can be tested without affecting the live production system.
A/B Testing and Controlled Digital Environments
One of the most common forms of experimentation in the tech sector is A/B testing (or split testing). By presenting two different versions of a software feature to two different user groups, companies can gather empirical evidence on which version performs better. This controlled experimentation allows developers to isolate variables—such as button placement, algorithm speed, or encryption methods—to determine their specific impact on the overall system. This phase is crucial for validating the hypothesis before a full-scale rollout.
Prototyping and Agile Iteration
For hardware gadgets or complex AI tools, experimentation often involves building a prototype. This allows engineers to test the physical or computational limits of their hypothesis. In the Agile development framework, this step is iterative; an experiment is run, the results are observed, and the prototype is adjusted in real-time. This “fail fast, learn faster” mentality is a direct application of the scientific method, where the goal of experimentation is as much about discovering what doesn’t work as it is about discovering what does.
4. Analysis: Deciphering Patterns in Big Data and Technical Performance
After the experiment has been conducted, the resulting data must be meticulously analyzed. In the tech world, this involves processing vast amounts of information—logs, user metrics, heatmaps, and performance benchmarks—to see if the results support or refute the initial hypothesis.
Leveraging AI and Analytics Tools for Deep Insight
Modern tech analysis often requires the use of specialized software like Tableau, PowerBI, or custom-built Python scripts to visualize and interpret data. Engineers look for statistical significance to ensure that the results of an experiment weren’t just a fluke. For example, if a new security patch appears to slow down a network, analysis will determine if that slowdown is a consistent trend across all servers or an isolated incident related to specific hardware configurations. This step transforms raw numbers into actionable intelligence.
Identifying Unintended Consequences and Edge Cases
Analysis also involves looking for “edge cases”—scenarios that occur only under specific, often extreme, conditions. A new app might work perfectly for 99% of users but crash for the 1% using an older operating system. Thorough analysis uncovers these vulnerabilities, allowing the tech team to refine the solution. It is at this stage that the “scientific” nature of the process is most evident, as it requires an objective, unbiased look at the data, even if the data proves the original hypothesis wrong.
5. Conclusion and Iteration: Validating Scalability and Security
The final step of the scientific process is reaching a conclusion. In a tech context, this means deciding whether the proposed solution is ready for deployment, needs further refinement, or should be scrapped entirely. However, in the fast-paced world of technology, a conclusion is rarely the “end.” Instead, it is a transition into the next cycle of innovation.
Documentation and Knowledge Sharing
A successful conclusion involves documenting the entire process. In software development, this means updating the codebase, writing technical manuals, and sharing findings with the broader engineering community. This transparency is vital for digital security; by documenting how a specific vulnerability was found and fixed, tech companies contribute to a more secure global ecosystem. The conclusion serves as the “source of truth” for future developers who will build upon this work.

The Feedback Loop: Continuous Improvement and DevOps
In the modern tech niche, the conclusion of one scientific cycle often feeds directly into the observation phase of the next. This is the essence of the DevOps (Development and Operations) loop. Once a new feature or tool is released to the public, the process of observation begins again. How do users react to the new tool? Does the new AI model maintain its accuracy over time? By treating tech development as a continuous scientific journey, companies can stay ahead of the curve, ensuring that their tools remain relevant, efficient, and transformative in an ever-changing digital world.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.