Entropy, a concept initially rooted in thermodynamics and information theory, serves as a cornerstone in various machine learning algorithms, primarily as a measure of uncertainty, disorder, or impurity within a set of data. Its application spans from guiding decision tree splits to quantifying prediction errors in complex neural networks, making it a fundamental idea for anyone delving into the mechanics of artificial intelligence and data science. Understanding entropy in this context illuminates how algorithms make decisions, learn from data, and optimize their performance, transforming an abstract concept into a practical tool for building intelligent systems.
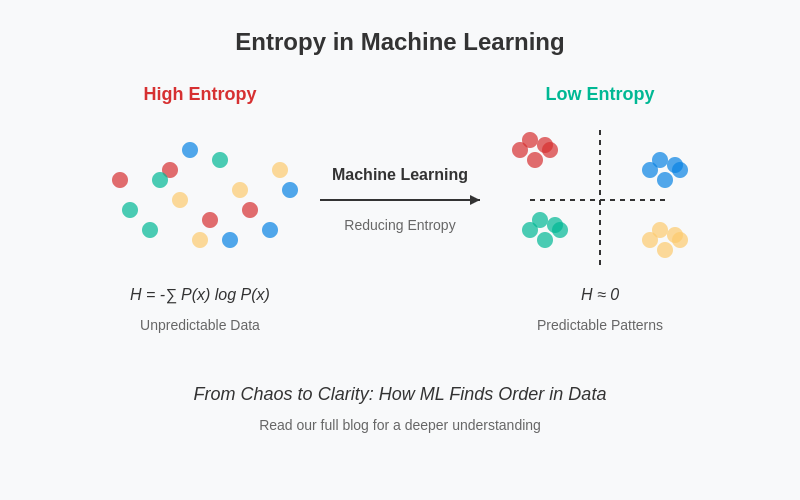
The Foundational Concept of Entropy
At its core, entropy quantifies the predictability or randomness of a system. When applied to data, it measures the inherent uncertainty associated with a collection of outcomes or classes. A dataset with high entropy is highly unpredictable, with observations evenly distributed across multiple categories. Conversely, a dataset with low entropy is more predictable, with most observations concentrated in one or a few categories.
Entropy in Information Theory
The most common formulation of entropy in machine learning draws directly from Claude Shannon’s information theory. Shannon entropy, often simply referred to as entropy, measures the average amount of information produced by a stochastic source of data. Mathematically, for a discrete random variable $X$ with possible outcomes $x1, x2, ldots, x_n$ and probability mass function $P(X)$, the entropy $H(X)$ is defined as:
$H(X) = -sum{i=1}^{n} P(xi) logb P(xi)$
Here, $P(xi)$ is the probability of outcome $xi$, and $b$ is the base of the logarithm. When $b=2$, the entropy is measured in “bits.” This formula implies that events with lower probability (more surprising events) contribute more to the overall entropy, as they carry more “information.” For instance, a fair coin flip has higher entropy than a heavily biased coin, because the outcome of a fair coin is more uncertain.
Measuring Uncertainty
In the context of machine learning, this translates directly to measuring the uncertainty of class distributions within a dataset. Consider a binary classification problem: if a group of samples contains an equal number of positive and negative examples, its entropy is at its maximum, indicating peak uncertainty about the class of any randomly selected sample. If all samples belong to the same class, the entropy is zero, signifying complete certainty and no uncertainty. Machine learning models often strive to reduce this uncertainty progressively as they process and learn from data.
Entropy’s Role in Decision Trees
One of the most intuitive and widespread applications of entropy in machine learning is found within decision tree algorithms. Algorithms like ID3, C4.5, and CART (though CART often uses Gini impurity, a similar concept) leverage entropy to determine the optimal way to split nodes and build an effective tree structure.
Information Gain as a Splitting Criterion
Decision trees work by recursively partitioning the dataset into subsets based on feature values. The central challenge is deciding which feature to split on at each node and what threshold to use for that feature. This is where entropy, specifically through the concept of Information Gain, becomes crucial.
Information Gain (IG) measures the reduction in entropy achieved by splitting a dataset based on a particular feature. The goal of a decision tree algorithm is to choose the split that maximizes information gain, meaning it selects the feature and split point that best separates the data into purer (lower entropy) subsets. The formula for Information Gain is:
$IG(S, A) = H(S) – sum{v in Values(A)} frac{|Sv|}{|S|} H(S_v)$
Where:
- $IG(S, A)$ is the information gain of splitting dataset $S$ on attribute $A$.
- $H(S)$ is the entropy of the original dataset $S$.
- $Values(A)$ is the set of all possible values for attribute $A$.
- $S_v$ is the subset of $S$ where attribute $A$ has value $v$.
- $|Sv|$ is the number of samples in $Sv$.
- $|S|$ is the total number of samples in $S$.
A high information gain implies that the split has effectively reduced the randomness or mixture of classes within the resulting child nodes, moving closer to a state where each node contains samples predominantly from a single class.
Reducing Impurity
In essence, entropy serves as a metric for “impurity” within a node. A node where all samples belong to the same class is perfectly pure and has an entropy of zero. Conversely, a node with an even mix of classes is highly impure and exhibits maximum entropy. Decision tree algorithms iteratively search for splits that transform impure parent nodes into purer child nodes, guided by the principle of maximizing information gain. This recursive process continues until the nodes become sufficiently pure, or other stopping criteria are met, resulting in a tree that can effectively classify new, unseen data points. The final leaf nodes of a well-trained decision tree will ideally have very low or zero entropy, indicating a high degree of certainty about the class of samples reaching that node.
Cross-Entropy for Classification
While standard entropy quantifies the uncertainty of a single probability distribution, cross-entropy extends this concept to measure the difference between two probability distributions. This makes it an invaluable tool as a loss function in machine learning models, particularly in tasks involving classification, such as logistic regression and neural networks.
Quantifying Prediction Error
In classification problems, models typically output a probability distribution over the possible classes for a given input. For instance, a model might predict a 70% chance of an image being a “cat” and a 30% chance of it being a “dog.” The true label, however, is a one-hot encoded vector representing the actual class (e.g., [1, 0] for cat, [0, 1] for dog). Cross-entropy measures how well the predicted probability distribution aligns with the true distribution.
For binary classification, the binary cross-entropy (BCE) loss for a single example is:

$L_{BCE} = -(y log(hat{y}) + (1 – y) log(1 – hat{y}))$
Where:
- $y$ is the true label (0 or 1).
- $hat{y}$ is the predicted probability that the label is 1.
For multi-class classification, categorical cross-entropy (CCE) loss is used:
$L{CCE} = -sum{c=1}^{M} y{o,c} log(hat{y}{o,c})$
Where:
- $M$ is the number of classes.
- $y_{o,c}$ is a binary indicator (0 or 1) if class $c$ is the correct classification for observation $o$.
- $hat{y}_{o,c}$ is the predicted probability that observation $o$ is of class $c$.
In essence, cross-entropy loss penalizes predictions that are confident but wrong more heavily than predictions that are confident and correct. If a model predicts a high probability for the correct class, the cross-entropy loss will be low. If it predicts a high probability for an incorrect class, the loss will be high.
Loss Functions and Model Training
Cross-entropy serves as a crucial loss function during the training phase of classification models. The objective of model training is to minimize this loss. By minimizing cross-entropy, the model learns to adjust its internal parameters (weights and biases) such that its predicted probability distributions become as close as possible to the true distributions of the training data. Gradient descent and its variants are typically employed to iteratively update these parameters, guiding the model towards a state where it can make accurate classifications on unseen data. This process is fundamental to the successful training of deep learning models and many other probabilistic classifiers.
Beyond Classification: Entropy in Other ML Contexts
While decision trees and classification loss functions are primary areas where entropy shines, its utility in machine learning extends to more advanced and specialized applications, highlighting its versatility as a concept for understanding and manipulating information.
Regularization and Maximizing Entropy
In some machine learning paradigms, entropy is not just minimized but sometimes maximized. Maximum Entropy (MaxEnt) models, for instance, are based on the principle of choosing the probability distribution that best represents the current state of knowledge, subject to certain constraints, while simultaneously maximizing entropy. This means preferring distributions that are as uniform as possible given the available information, effectively introducing a form of regularization. By seeking the “flattest” or least opinionated distribution, MaxEnt models can prevent overfitting by avoiding unwarranted assumptions about the data beyond what is explicitly provided by the features. This approach encourages a model to be generalizable by not assigning excessively high probabilities to specific outcomes unless strongly supported by the data, making it useful in areas like natural language processing for tasks such as part-of-speech tagging and sentiment analysis.
Reinforcement Learning and Exploration
Entropy also plays a subtle yet significant role in reinforcement learning (RL). In RL, an agent learns to make decisions in an environment to maximize a cumulative reward. One common challenge is the exploration-exploitation dilemma: should the agent stick to actions it knows yield good rewards (exploitation), or try new actions to discover potentially better rewards (exploration)?
Entropy can be incorporated into the reward function or the policy itself to encourage exploration. By adding an entropy bonus to the reward, RL algorithms can incentivize the agent to maintain a more stochastic (higher entropy) policy. A high-entropy policy means the agent is more likely to try a wider range of actions, even those not currently deemed optimal, thus exploring the environment more thoroughly. This helps prevent the agent from getting stuck in local optima and discovering more robust and efficient strategies over time. Techniques like Maximum Entropy Reinforcement Learning explicitly optimize for policies that are not only high-reward but also high-entropy, balancing performance with exploratory behavior.
Practical Implications and Advanced Concepts
The understanding of entropy forms the basis for several other critical concepts and metrics in machine learning, further expanding its practical implications for model evaluation and comparison.
KL Divergence
Kullback-Leibler (KL) Divergence, also known as relative entropy, is a measure of how one probability distribution $P$ diverges from a second, expected probability distribution $Q$. It quantifies the “information lost” when $Q$ is used to approximate $P$. The formula for KL Divergence for discrete distributions is:
$D{KL}(P || Q) = sum{i} P(i) log frac{P(i)}{Q(i)}$
While not a true distance metric (it’s not symmetric and doesn’t satisfy the triangle inequality), KL Divergence is widely used in various machine learning contexts. Notably, cross-entropy is closely related to KL Divergence: $H(P, Q) = H(P) + D_{KL}(P || Q)$, where $H(P, Q)$ is the cross-entropy of $P$ with respect to $Q$, and $H(P)$ is the entropy of $P$. This relationship highlights that minimizing cross-entropy loss during model training is equivalent to minimizing the KL Divergence between the true distribution and the predicted distribution, effectively making the model’s predictions as close as possible to the ground truth. KL Divergence is particularly important in variational autoencoders (VAEs) and other generative models for measuring the difference between learned and target distributions.
Perplexity
Perplexity is a measure of how well a probability distribution or probability model predicts a sample. It is commonly used in natural language processing (NLP) to evaluate language models. A lower perplexity score indicates a better model, as it suggests the model assigns higher probabilities to the actual sequence of words observed. Perplexity is mathematically defined as:
$Perplexity = 2^{H(P)}$
where $H(P)$ is the cross-entropy of a test set with the probability distribution estimated by the language model, typically base-2 logarithm is used. Essentially, perplexity can be thought of as the weighted average number of choices a model has when predicting the next item in a sequence. If a model has high perplexity, it means it is relatively uncertain about which word will come next, indicating a poorer fit to the data. Conversely, low perplexity signifies a model that is more confident and accurate in its predictions. Thus, perplexity provides an intuitive way to assess the predictive power of models in tasks like text generation, machine translation, and speech recognition.
In summary, entropy, in its various forms, is far more than a theoretical construct; it is a vital operational metric that underpins many core functionalities in machine learning. From guiding the splits in decision trees to serving as a critical loss function in neural networks, and even encouraging exploration in reinforcement learning, its pervasive influence demonstrates its fundamental importance in the ongoing advancement of AI technologies.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.