The digital landscape has fundamentally transformed how we perceive, interact with, and translate the world’s languages. For developers, software architects, and AI researchers, understanding the classification of a language like Mongolian is not merely an academic exercise; it is a critical component of globalization (G11n), localization (L10n), and the development of robust natural language processing (NLP) models. As we push toward a more interconnected digital ecosystem, understanding what Mongolian is—and why its architecture poses unique challenges for modern tech stacks—becomes a priority for those building the next generation of global software.
The Linguistic Architecture of Mongolian: A Computational Challenge
At its core, Mongolian belongs to the Mongolic language family. Linguistically, it is classified as an agglutinative language, characterized by a complex system of vowel harmony and a sophisticated suffixation process. From a computational perspective, this is where the primary technical hurdles emerge.
Syntactic Structure and Algorithmic Parsing
Unlike English, which relies heavily on word order and prepositions, Mongolian utilizes a Subject-Object-Verb (SOV) structure. In the realm of NLP, this presents a distinct challenge for machine translation algorithms. Standard transformers and large language models (LLMs) trained primarily on Indo-European syntax often struggle with the recursive nature of Mongolian suffixes. When building software localization tools or AI-driven chatbots, developers must account for the fact that a single Mongolian word can encapsulate the grammatical information of an entire English phrase.
Script Diversity: The Technical Divide
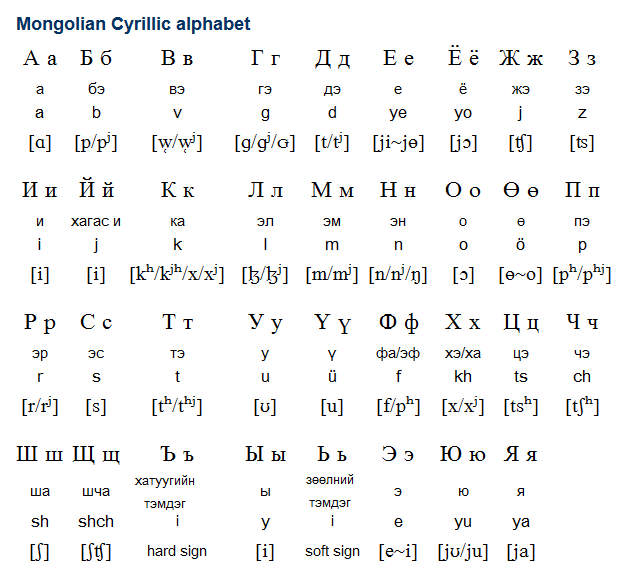
The Mongolian language presents a unique challenge in digital formatting due to its dual-script history. The traditional Mongolian script—written vertically—is a masterpiece of calligraphy but poses significant hurdles for modern text rendering engines. Conversely, Khalkha Mongolian, the official language of Mongolia, is written in a modified Cyrillic script. For tech teams, this requires a dual-track strategy in character encoding (UTF-8) and font support to ensure that both the historical script and the modern Cyrillic iteration are displayed correctly across mobile applications and web interfaces.
Localization Strategies for the Mongolian Market
Expanding software into new geographic territories requires more than simple translation; it requires cultural and structural localization. Because Mongolian is a language of suffixes, UI design must be adaptive.
Dynamic String Expansion and UI Layouts
One of the most common pitfalls in software localization is the fixed-width UI element. In English, a button labeled “Submit” is concise. In Mongolian, the translation of technical terms often requires significantly more characters due to the suffix-heavy morphology. Developers must implement dynamic, responsive containers that can handle the variable length of Mongolian strings without breaking the layout or truncation. This is where “Internationalization as Code” becomes essential—designing systems that expect strings to fluctuate in size and complexity depending on the target locale.
Handling Vowel Harmony in Spell-Check and Predictive Text
Vowel harmony is a phonological feature where all vowels in a word must belong to the same class (front, back, or rounded). For AI tools and predictive text engines, this is a vital rule-set. If a machine learning model is not “aware” of these constraints, the autocorrect functionality will produce non-sensical, grammatically incorrect suggestions. Developers working on Mongolian-language keyboards or input method editors (IMEs) must integrate phonetic-aware logic into their predictive algorithms. This is not just a language feature; it is an optimization problem that defines the quality of the user experience.

The Future of Mongolian in AI and Machine Learning
As we enter an era of generative AI, the preservation and digital integration of lesser-represented languages like Mongolian are accelerating. The focus has shifted from simple statistical machine translation to deep learning architectures that can grasp the nuances of the Mongolian morphology.
Building Corpora for Low-Resource Languages
The primary barrier to high-quality AI in Mongolian is the scarcity of large, high-quality digital corpora. For machine learning, a “low-resource” language is one that lacks the massive datasets required to train GPT-style models to human-level fluency. To bridge this gap, tech companies and open-source communities are increasingly looking toward synthetic data generation and cross-lingual transfer learning. By training models on linguistically similar languages and fine-tuning them on existing Mongolian datasets, researchers are narrowing the performance gap.
Semantic Mapping and Cross-Lingual Embeddings
Technological progress in Mongolian also relies on semantic vector mapping. By aligning the vector space of Mongolian words with more heavily supported languages, developers can leverage existing knowledge bases to improve translation accuracy. This “transfer of knowledge” approach allows for smarter sentiment analysis, keyword extraction, and summarization tools. As these models evolve, we see a move toward “multilingual LLMs” that treat Mongolian not as an outlier, but as a fully integrated node in a global semantic graph.
Best Practices for Developers and Product Managers
For technical teams tasked with supporting Mongolian within their software ecosystem, the path forward involves a blend of linguistic research and robust engineering standards.
Infrastructure Readiness
- Encoding Standards: Ensure that your backend databases and frontend rendering engines fully support Unicode, specifically the Mongolian blocks (U+1800–U+18AF) for the traditional script and Cyrillic blocks for the modern script.
- Modular Translation: Adopt a key-value pair translation system that separates the UI framework from the content. This prevents hardcoded strings from becoming technical debt when the language undergoes morphological changes.
- Continuous Integration (CI): Implement automated UI testing that includes “pseudo-localization.” By padding your current strings with extra characters, you can quickly identify which parts of your application will fail when populated with longer Mongolian text.
User Experience (UX) Considerations
The Mongolian user experience is moving rapidly toward mobile-first consumption. Because the language is distinct, the reliance on voice-to-text and voice-activated AI is higher than in markets with mature typing interfaces. Consequently, building high-accuracy speech-to-text (STT) models that understand the specific phonetics of Mongolian dialects is a significant growth area for tech startups focusing on the Central Asian region.
Conclusion: Bridging the Digital Divide
“What language is Mongolian?” is a question that leads directly into the heart of modern software engineering. It is an agglutinative, high-context, script-diverse language that challenges our existing frameworks for digital communication. As technology continues to lower the barrier for global entry, the importance of treating Mongolian with the same technical rigor as English or Mandarin cannot be overstated.
By investing in proper localization, embracing the challenges of morphological processing, and contributing to the open-source corpus of Mongolian data, the tech industry does more than just translate a language—it unlocks a market. It creates a digital environment where the complexity of the Mongolian language is met not with limitations, but with sophisticated engineering solutions that empower users to interact with technology in their native tongue. Whether it is through improved predictive text, more responsive UI designs, or more accurate machine learning models, the future of the Mongolian digital experience is being built line-by-line in the code of today. As developers continue to refine these systems, they ensure that the next frontier of global connectivity includes the vibrant, historical, and linguistically rich world of the Mongolian language.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.