In the world of high-performance software engineering and enterprise architecture, we often use biological metaphors to describe the health of a system. We talk about “heartbeats” for server availability, “digesting” large datasets, and “purging” cache. When a system is functioning at peak efficiency, its output—the data it produces for end-users or downstream applications—is clean, fast, and structured. However, many organizations eventually encounter a phenomenon that mimics a biological ailment: “mucous” in the data stream.
In a technical context, “mucous” refers to the unwanted, semi-structured friction, latency, and redundant overhead that begins to coat your system’s output. It is the “sludge” that slows down API responses, the “bloat” in JSON payloads, and the “noise” in log files that makes debugging a nightmare. Just as in the human body, a small amount of “mucous” (meta-data or necessary overhead) is normal, but an excess indicates systemic inflammation or infection.
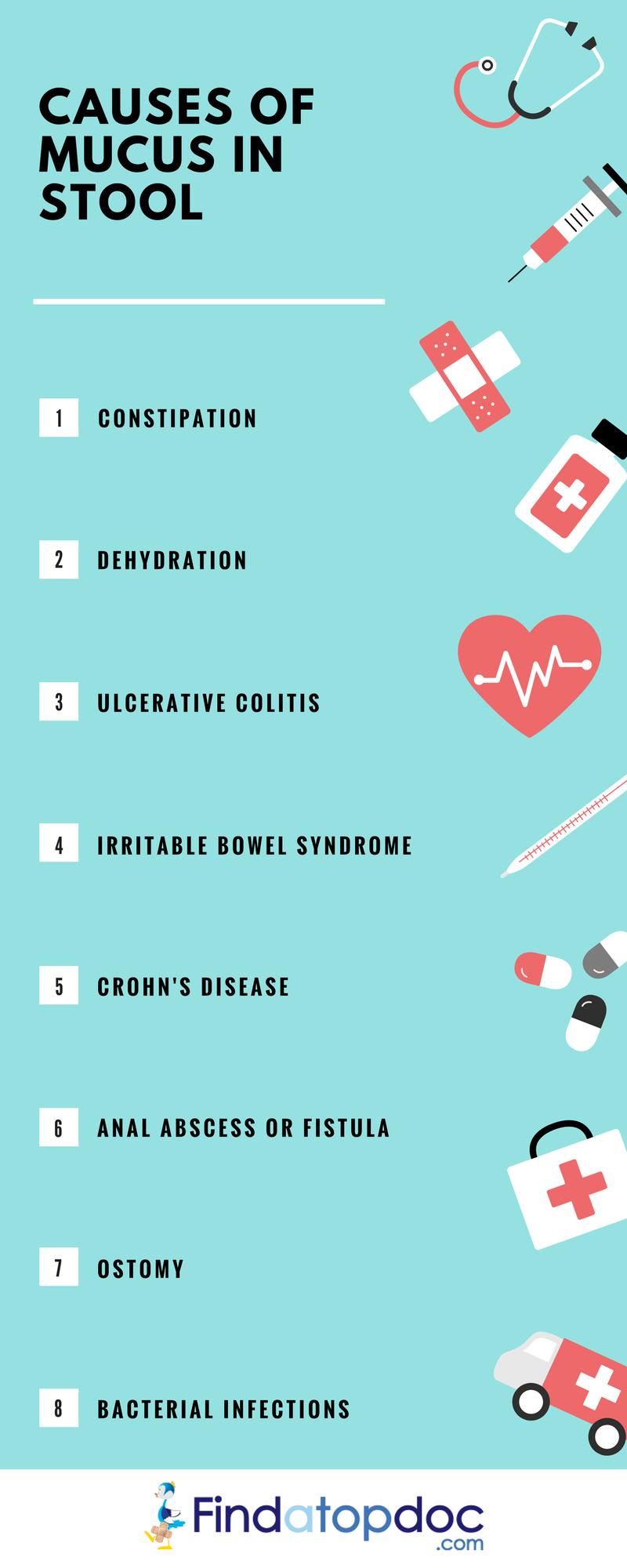
Understanding what causes this digital mucous is essential for CTOs, DevOps engineers, and software architects who are tasked with maintaining the “digestive health” of complex, multi-layered tech stacks.
Defining the Digital Pathology of Output Inefficiency
Before we can treat the symptoms, we must define what we mean by “mucous” in a professional technology environment. In a healthy system, data flows from the database through the logic layer to the user interface with minimal resistance. When the system becomes “ill,” the output starts to carry extra weight that doesn’t belong there.
The Concept of Data “Sludge”
Data sludge, or “mucous,” is most often seen in the form of bloated payloads. Imagine an API designed to return a user’s name and email address. Over years of legacy updates, that same API starts returning 50 lines of redundant metadata, deprecated fields, and unmapped objects. This extra “viscosity” increases the time it takes for data to travel across the network (latency) and increases the compute power required to parse it on the client side.
Distinguishing Normal Operation from Systemic Inflammation
Every system requires some overhead. Security headers, authentication tokens, and basic logging are the healthy “lining” of a data stream. The transition to a pathological state occurs when this overhead begins to outpace the actual value of the data being delivered. Systemic inflammation in tech usually occurs during rapid scaling or after a series of “quick-fix” patches that were never properly integrated into the core architecture. When your monitoring tools show that 70% of your bandwidth is being consumed by “header noise” rather than “body content,” your system has a mucous problem.
Architectural Causes of Data Redundancy and “Mucous”
The root causes of system inefficiency are rarely found in a single line of code. Instead, they are usually found in the architecture—the “anatomy” of the system. If the architecture is poorly designed or has become cluttered over time, it will naturally produce “mucous” as a byproduct of its internal friction.
Legacy Middleware Congestion
One of the primary causes of “mucous” in enterprise output is the presence of outdated middleware. Many organizations rely on “ESB” (Enterprise Service Bus) models or aging API gateways that were built for a different era of traffic. As data passes through these layers, each layer adds its own wrappers, conversion protocols, and “translation logic.”
By the time the data reaches the final endpoint, it is covered in layers of technical debt. This middleware congestion creates a “chokepoint” where data sits and stagnates, leading to increased response times and a high risk of data corruption. Removing this “mucous” often requires a move toward modern, lightweight service meshes or direct microservice communication.
Database Indexing Failures and Bloat
The “gut” of any tech stack is its database. When a database is not properly maintained, it begins to suffer from fragmentation and poor indexing. This causes the database engine to work harder to “digest” queries. Instead of a clean, indexed search, the engine performs a full table scan, pulling in massive amounts of unnecessary data into the buffer pool.
This “internal mucous” manifests externally as slow-loading pages and timed-out requests. Furthermore, if the database schema has “bloat”—hundreds of unused columns or orphaned records—every query carries the risk of returning “noisy” data that the application layer then has to spend CPU cycles filtering out.
The Role of External “Pathogens” in Technical Performance
Sometimes, the cause of “mucous” in your stool—or rather, your system output—is not internal architecture, but external factors that have “infected” the environment. These pathogens interfere with the clean flow of information and force the system to produce defensive artifacts.
DDoS Artifacts and Traffic Anomalies
When a system is under a low-level Distributed Denial of Service (DDoS) attack or being scraped by aggressive bots, the output logs often fill up with “mucous.” This manifests as a surge in 4xx and 5xx error codes, malformed request headers, and “garbage” data packets. These artifacts are the system’s way of reacting to an irritant. While the system might stay online, the “quality” of its performance drops significantly as it redirects resources to handle the “phlegm” of malicious traffic.
Third-Party API Degradation
Modern software is rarely a closed loop; it relies on a web of third-party integrations (Stripe for payments, AWS for storage, Twilio for SMS). When one of these external organs becomes “inflamed” or sluggish, it introduces “mucous” into your own system.
For instance, if a third-party authentication provider takes 2 seconds to respond, your entire user-facing output is delayed. The “mucous” here is the waiting state—the blocked threads and idle connections that clog your server’s memory. Identifying these external causes requires robust distributed tracing to see exactly where the “obstruction” is occurring.
Diagnostic Tools for Monitoring System Health
To cure the problem, you must first be able to see it. In the tech niche, “seeing” the problem means implementing a level of observability that goes beyond simple “up/down” monitoring. You need to perform a “microscopic” analysis of your data flow.
Real-Time Observability and Telemetry
Tools like Prometheus, Grafana, and Datadog act as the “endoscopy” of the tech world. They allow engineers to visualize the flow of data in real-time. By looking at “P99” latency spikes, developers can identify exactly when and where the “mucous” is building up. If the latency is high but the CPU usage is low, it’s a sign of a “blockage” (I/O wait or network congestion). If both are high, the system is struggling to “digest” a heavy workload.
Log Analysis: Sifting Through the Waste
Analyzing logs is the most direct way to diagnose “mucous” in the system. Log aggregation platforms like ELK (Elasticsearch, Logstash, Kibana) or Splunk allow you to sift through the “waste” produced by your applications. By using pattern recognition, these tools can identify “noisy” logs—repetitive error messages or warnings that serve no purpose but to consume disk space. Cleaning up these logs is the first step in “detoxing” the system, allowing the meaningful data to stand out.
Future-Proofing the Tech Stack: Prevention and Treatment
Once the “mucous” has been identified and the immediate causes treated, the focus must shift to long-term prevention. A healthy tech stack requires constant “exercise” (load testing) and a “clean diet” (optimized code).
Decoupling Microservices for Smoother Flow
One of the most effective treatments for “systemic mucous” is decoupling. In a monolithic architecture, a failure in one part of the system can cause a “backup” that affects the entire platform. By moving to a microservices architecture, you ensure that each function has its own “digestive tract.” If the “Email Service” becomes clogged, it doesn’t prevent the “Payment Service” from functioning. This isolation prevents the spread of “inflammation” and ensures that the overall output of the platform remains fluid.
The Culture of Continuous Optimization
Ultimately, the best way to prevent “mucous” in your tech stack is to foster a culture of performance engineering. This involves:
- Payload Audits: Regularly reviewing API responses to ensure only necessary data is being sent.
- Compression: Using modern protocols like gRPC or Brotli compression to thin out the “viscosity” of the data.
- Automated Testing: Implementing “performance budgets” in the CI/CD pipeline. If a new code commit increases the “mucous” (latency or payload size) beyond a certain threshold, the build is automatically rejected.
Conclusion
In the enterprise technology landscape, “mucous in the stool” is a metaphor for the friction, waste, and inefficiency that inevitably builds up in complex systems. Whether caused by legacy architecture, database bloat, or external “infections,” these issues can slow down your business and degrade the user experience. By applying a rigorous diagnostic approach—utilizing observability tools, decoupling services, and maintaining a lean data diet—organizations can ensure their technical output remains clean, fast, and healthy. In a world where speed is a competitive advantage, keeping your system free of “digital mucous” is not just a maintenance task; it is a strategic necessity.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.