In the lexicon of modern technology, we often use biological metaphors to describe the complex systems we build. We speak of “neural networks,” “computer viruses,” and “system health.” However, one of the most pressing challenges facing high-speed computing, big data architecture, and artificial intelligence today is a phenomenon that can best be described as a “clot.”
In a technical context, a clot is not a biological mass but a digital one—a severe bottleneck where the flow of data, instructions, or processing power becomes obstructed, leading to system latency, application failure, or complete architectural stagnation. As we move deeper into the era of real-time analytics and hyper-scale cloud environments, understanding what these clots are, why they form, and how to “dissolve” them is essential for any developer, system architect, or IT strategist.

The Anatomy of a Digital Clot: Where Data Flow Stops
To understand a clot in a technical sense, one must first view a computing system as a series of interconnected pipelines. Whether it is a local area network (LAN), a global cloud infrastructure, or the internal bus of a high-end server, the goal is always “flow.” When this flow is interrupted by an inefficiency that causes data to pile up faster than it can be processed, a clot is formed.
Network Latency and Packet Congestion
The most common form of a digital clot occurs within networking. In a distributed system, data travels in packets. When a specific node or switch becomes overwhelmed—often due to a sudden “burst” of traffic or a hardware malfunction—packets begin to queue. This queuing creates a clot that doesn’t just slow down that specific node; it ripples backward, causing “backpressure” throughout the entire network. This is the digital equivalent of a deep vein thrombosis: the blockage is in one area, but the lack of circulation affects the entire organism.
Database Indexing and Read/Write Contention
At the software level, clots frequently manifest within database management systems (DBMS). If a database is not properly indexed, the “search” function becomes a massive drain on resources. Similarly, “write contention”—where multiple processes attempt to update the same piece of data simultaneously—creates a lock. These locks are essentially clots in the transactional flow, preventing the application from moving forward until the contention is resolved.
The I/O Barrier in Legacy Systems
Input/Output (I/O) clots are perhaps the most frustrating for enterprise tech leaders. This occurs when a high-speed processor is paired with a low-speed storage medium (like traditional spinning hard drives or slow-speed SATA SSDs). The CPU is ready to process millions of instructions per second, but it is “starved” because the storage cannot feed it data fast enough. This starvation creates a clot at the interface level, rendering expensive computing power useless.
AI and Machine Learning: When Neural Networks Clog
As we integrate Artificial Intelligence into every layer of software, a new breed of “AI clots” has emerged. These bottlenecks are unique to the way machine learning (ML) models are trained and deployed, and they represent a significant hurdle for companies trying to scale their AI initiatives.
Training Data Bottlenecks
The process of training a Large Language Model (LLM) or a complex computer vision system requires massive amounts of data to be fed into GPUs (Graphics Processing Units). A clot often forms in the “data preprocessing” stage. If the raw data cannot be cleaned, shuffled, and augmented fast enough to keep the GPUs at 100% utilization, the training process stalls. In the world of high-performance computing (HPC), an underutilized GPU is a massive financial and technical waste.
Inference Latency and Model Weight Bloat
Once a model is trained, it must perform “inference”—the act of providing an answer to a user’s query. A clot occurs here when the model is too “heavy” for the hardware it is running on. Large model weights can clog the system memory (VRAM), leading to high latency. For the user, this feels like an application that is “thinking” for too long. In reality, the system is struggling to move massive mathematical tensors through a limited hardware pipe.
The “Deadlock” in Distributed AI
Modern AI is rarely housed on a single machine; it is distributed across clusters. A “clot” in this environment often stems from synchronization issues. If one node in a 1,000-node cluster finishes its task slightly later than the others (a “straggler”), the entire system may wait, creating a synchronized clot that halts progress across the entire grid.
The Ripple Effect: Why Technical Clots Threaten Ecosystems
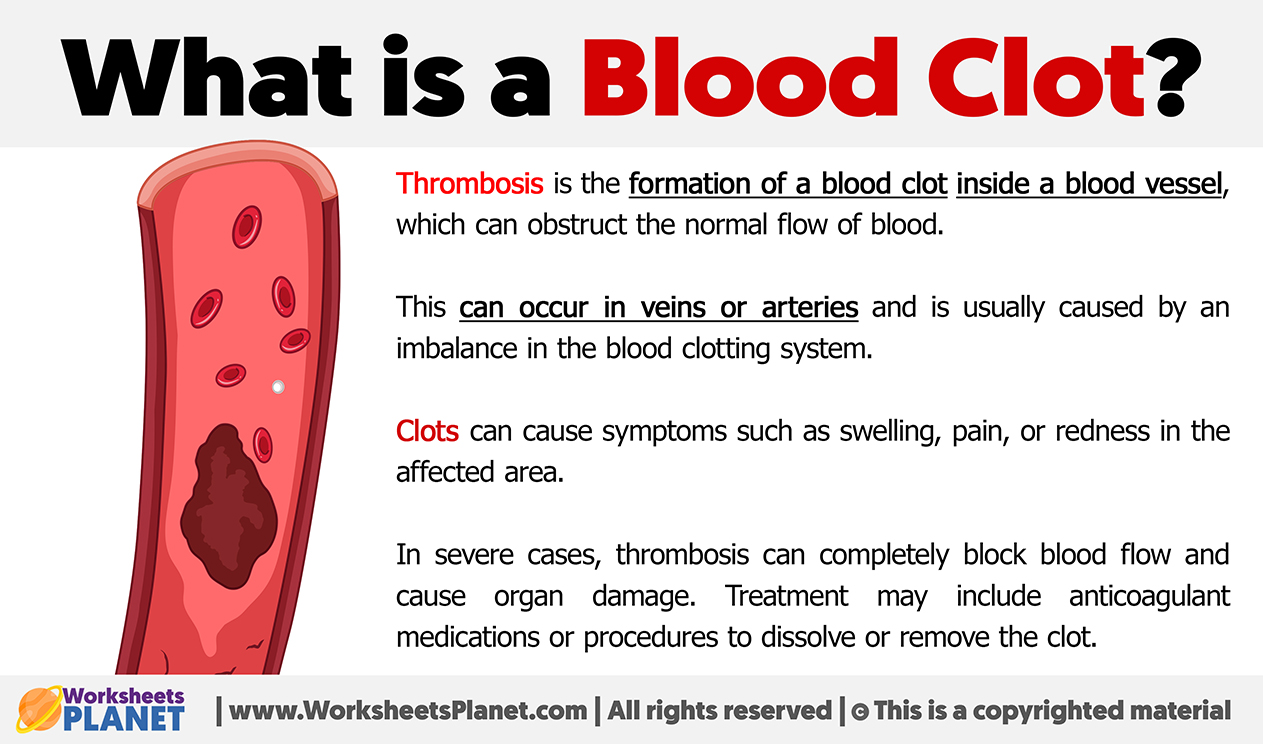
A clot in a technical system is rarely a localized event. Because modern software is increasingly modular and interdependent—thanks to the rise of APIs and microservices—a blockage in one area can lead to a catastrophic failure across a global ecosystem.
Erosion of User Experience (UX)
From a consumer perspective, a technical clot translates to one thing: friction. Whether it is a loading spinner that never disappears or a checkout button that doesn’t respond, clots kill user engagement. In the digital economy, latency is the primary driver of “churn.” A 100-millisecond delay can result in a measurable drop in conversion rates, proving that the health of the system’s “circulation” is directly tied to business success.
Security Vulnerabilities During Stagnation
Clots are not just performance issues; they are security risks. When a system is bogged down by a data clot, monitoring tools often fail or experience “blind spots.” High-traffic congestion can be used as a smokescreen for Distributed Denial of Service (DDoS) attacks. Furthermore, when systems are “clotted,” they are slower to apply patches or update security protocols, leaving them vulnerable to exploitation during the period of stagnation.
Cost Escalation in Cloud Computing
In a cloud-native environment (AWS, Azure, Google Cloud), you pay for what you use—and sometimes for what you waste. If a technical clot causes a process to hang or a virtual machine to run at 100% CPU without completing a task, the “meter” continues to run. Unoptimized code and clotted data pipelines can lead to “cloud sprawl” and astronomical monthly bills, as the system scales up more resources to push through a blockage that should have been solved at the architectural level.
Strategies for Clearing the Pipes: Solving Technical Clots
Modern DevOps and Site Reliability Engineering (SRE) focus heavily on “thoroughfare optimization”—the science of identifying and clearing these digital clots before they cause a system-wide stroke.
Implementation of Edge Computing
One of the most effective ways to prevent clots is to stop the data from traveling so far in the first place. Edge computing pushes the processing power closer to the data source (the user’s device, an IoT sensor, etc.). By processing data at the “edge,” we reduce the volume of traffic that needs to return to the central cloud, effectively thinning the data stream and preventing clots in the core network.
Microservices and Load Balancing
Rather than having one giant “monolithic” application where a single clot can bring down the entire system, modern tech uses microservices. This architecture breaks the application into smaller, independent parts. If a clot forms in the “payment service,” the “search service” and “user profile service” can continue to function. Load balancers then act as traffic cops, rerouting data around congested nodes to ensure no single point becomes a bottleneck.
Asynchronous Processing and Message Queues
To prevent “write contention” and system locks, engineers use asynchronous processing. Instead of forcing the system to wait for a task to finish, the task is placed in a “message queue” (like RabbitMQ or Apache Kafka). This allows the main system to keep moving while the “clot” is processed in the background at a manageable pace. It is the digital equivalent of an overflow valve.
The Future of Fluid Computing: Toward Self-Healing Architectures
As we look toward the next decade of technology, the goal is to move beyond manual intervention and toward systems that can detect and dissolve their own clots autonomously.
AI-Driven Observability
The next generation of monitoring tools will use AI to predict where clots are likely to form. By analyzing patterns in traffic and CPU usage, these “AIOps” tools can proactively reallocate resources or spin up new instances before a bottleneck even occurs. This shift from reactive to predictive maintenance is the key to maintaining “fluid” computing.
Quantum Computing and Overcoming Linear Bottlenecks
While still in its infancy, quantum computing promises to solve certain types of clots that are inherent to classical binary logic. Problems involving massive optimization (like logistics or complex chemical simulations) often “clot” classical computers because of the sheer number of variables. Quantum bits (qubits) can process these possibilities simultaneously, theoretically bypassing the linear bottlenecks that plague our current hardware.

The Rise of “Liquid” Software
We are seeing the emergence of “liquid” software architectures—code that is designed to be highly portable and elastic. This approach treats computing resources not as fixed pipes, but as a fluid pool. If one area of the system experiences a clot, the software dynamically reshapes itself to bypass the obstruction, ensuring that the flow of information remains constant, regardless of the underlying hardware limitations.
In conclusion, “clots” in the technological landscape are the silent killers of efficiency. Whether they occur in the training of an AI model, the transmission of data across a 5G network, or the execution of a database query, these bottlenecks represent the primary obstacle to the next phase of digital evolution. By understanding the mechanics of these digital obstructions and implementing sophisticated architectural solutions, we can ensure that the “bloodstream” of our global digital economy remains healthy, fast, and resilient.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.