In the landscape of modern technology, data serves as the foundational currency upon which every application, algorithm, and enterprise system is built. To manage this data effectively, software engineers and database architects rely on discrete mathematics and relational logic. One of the most fundamental concepts in this realm is the “domain of a relation.” While the term originates in set theory, its practical application is what allows our modern digital world—from global banking systems to social media platforms—to maintain data integrity, security, and efficiency.
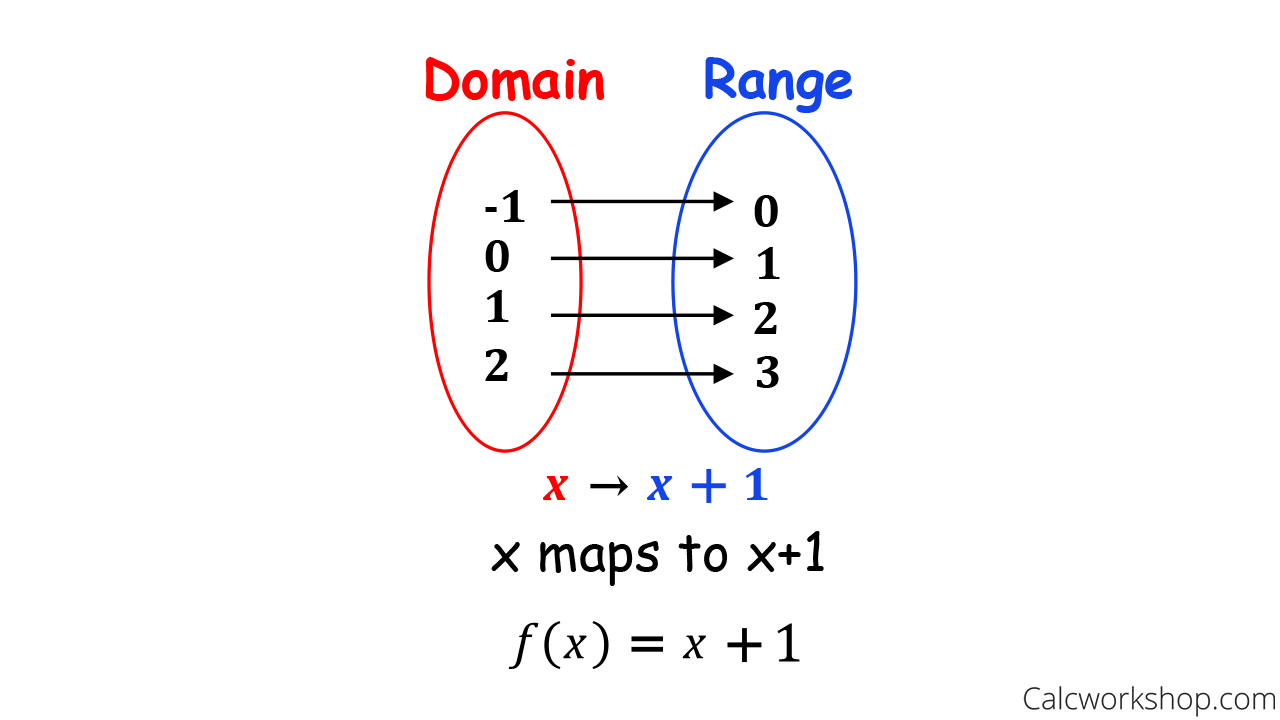
Understanding what a domain of a relation is requires looking beyond simple definitions. It is a critical component of how computers interpret relationships between different data points, how schemas are designed in SQL, and how artificial intelligence models process input variables.
Understanding the Mathematical Foundation in Computer Science
At its core, a relation is a set of ordered pairs. If we have two sets, $A$ and $B$, a relation from $A$ to $B$ is a subset of the Cartesian product $A times B$. In this context, the domain is defined as the set of all “first elements” of these ordered pairs.
The Concept of Ordered Pairs and Tuples
In software engineering, we rarely deal with abstract sets; instead, we deal with “tuples.” A tuple represents a single record in a dataset. For example, if a relation represents a “User Profile,” an ordered pair might consist of a User ID and an Email Address. The domain, in this specific instance, would be the collection of all possible or existing User IDs.
In technical terms, if $R$ is a relation, the domain is denoted as $dom(R) = {x mid exists y, (x, y) in R}$. This mathematical rigor ensures that a computer system knows exactly which inputs are valid before any processing occurs. Without a strictly defined domain, software would be prone to “type errors” and logical crashes.
Mapping Inputs to Outputs
The domain is intrinsically linked to the concept of a “codomain” or “range.” In any computational function or relation, the domain represents the input space. For developers working in functional programming languages like Haskell or Scala, the domain of a relation determines the “type” of the input. If a function expects a domain of integers but receives a string, the system identifies a mismatch. This logic forms the basis of static typing and compile-time error checking in high-level programming.
Relational Databases: From Theory to Technical Implementation
The most common practical application of “domain of a relation” in technology is found within Relational Database Management Systems (RDBMS) like PostgreSQL, MySQL, and Oracle. Here, the theory of E.F. Codd (the father of relational databases) comes to life.
Attributes and Domains in SQL
In a database table, each column represents an “attribute,” and the domain is the set of allowable values for that attribute. When an architect defines a column as VARCHAR(255) or INTEGER, they are essentially defining the domain of that relation.
However, a domain in tech is often more specific than just a data type. For instance, if you have a column for “Employee Age,” the data type is an integer, but the domain might be restricted to values between 18 and 65. Modern SQL allows for the explicit creation of domains using the CREATE DOMAIN command. This creates a user-defined data type with specific constraints, ensuring that the domain remains consistent across multiple tables in a complex schema.
Constraint Management and Data Integrity
The domain of a relation acts as the first line of defense for data integrity. By defining a domain strictly, tech professionals implement “Domain Integrity.” This ensures that every entry in a column follows a specific set of rules.
- Check Constraints: These allow developers to limit the domain based on logic (e.g.,
Price > 0). - Not Null Constraints: These ensure that the “null” value is excluded from the domain of the relation.
- Unique Constraints: These ensure that every element in the domain maps to a specific, non-repeating identifier.
By enforcing these boundaries at the database level, backend developers prevent “garbage in, garbage out” scenarios, which are the leading cause of bugs in enterprise software.
The Role of Domains in Software Engineering and AI

As we move away from static storage and toward active processing, the concept of a domain evolves into something more dynamic. In software engineering and Artificial Intelligence (AI), the domain defines the scope of operation for an application or a model.
Static Typing and Set Limits in Modern Languages
In modern software development, particularly in systems programming (C++, Rust), the domain of a relation is expressed through the type system. If a developer defines a relation between a “Sensor Reading” and a “Timestamp,” the domain of the sensor reading must be handled with precision.
Rust, for example, uses “enums” and “pattern matching” to ensure that every possible value in a domain is accounted for. If a programmer writes a function that only handles a portion of the domain, the compiler will flag an “exhaustive search” error. This technical safeguard is a direct application of relational domain theory, preventing the software from entering an “undefined state.”
Feature Domains in Machine Learning Models
In the field of AI and Machine Learning, the domain of a relation is often referred to as the “Input Space” or “Feature Domain.” When training a neural network, the domain consists of all possible vectors of input data.
- Normalization: To ensure an AI model processes data efficiently, engineers often “normalize” the domain, scaling all input values to a range between 0 and 1.
- Out-of-Distribution (OOD) Detection: This is a cutting-edge AI security concern. If a model receives an input that falls outside its trained domain of relation, it may produce “hallucinations” or confident but incorrect predictions. Identifying the boundaries of the domain is therefore essential for building reliable and safe AI tools.
Best Practices for Defining Domains in System Architecture
For CTOs and Lead Architects, defining domains is not just a mathematical exercise; it is a strategic one. Poorly defined domains lead to “technical debt” and system fragility.
Normalization and Domain Consistency
Database normalization is the process of organizing data to reduce redundancy. At the heart of normalization is the requirement that every attribute in a table must belong to a single, atomic domain. In “First Normal Form” (1NF), we ensure that domains do not contain sets of values, but rather single values. This simplifies the relation and makes the data more accessible for high-speed queries.
Domain-Driven Design (DDD)
In complex software ecosystems, “Domain-Driven Design” (DDD) is a methodology where the structure of the code matches the business domain. Here, the “relation” is between business logic and technical implementation. By clearly defining the “Bounded Context” (the limit of where a specific domain is valid), architects can build microservices that interact seamlessly without data overlap or conflicting definitions.
For example, a “Product ID” in a Shipping Service might have a different domain (including weight and dimensions) than a “Product ID” in an Accounting Service (including tax codes and price). Keeping these domains distinct yet related is the hallmark of professional system design.
The Future of Relational Logic in Cloud Computing and Big Data
As we transition into the era of Big Data and distributed systems, the “domain of a relation” is being challenged by high-velocity, unstructured data. However, rather than becoming obsolete, the concept is becoming more sophisticated.
In NoSQL databases (like MongoDB or Cassandra), domains are often “fluid” or “schema-less.” While this offers flexibility, it often leads to “data swamps” where the relation between data points becomes unclear. As a result, many tech organizations are moving toward “Schema-on-Read” or “Data Contracts.”
A Data Contract is essentially a modern, API-driven way of defining the domain of a relation between two microservices. It specifies that “Service A” will only send data to “Service B” if it falls within a strictly defined domain. If the data violates this contract, the system automatically rejects it, preventing the propagation of errors across a cloud network.
Furthermore, in the world of Quantum Computing, the domain of a relation may expand from binary states (0 or 1) to a superposition of states. This will require an entirely new mathematical framework for understanding how data points relate to one another, but the fundamental principle will remain the same: to process information, we must first define the boundaries of what that information can be.

Conclusion
The domain of a relation is more than just a chapter in a discrete mathematics textbook; it is the skeletal structure of the digital age. By defining the set of all possible inputs for a given relationship, it provides the predictability and stability required for complex software to function. Whether you are an SQL developer defining a column constraint, a data scientist normalizing features for an AI model, or a systems architect designing a microservice mesh, you are working within the constraints and powers of the domain. In a world increasingly driven by data, the precision with which we define these domains determines the reliability, security, and success of our technological endeavors.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.