In the realm of technology, data is king. Businesses, researchers, and developers are constantly collecting vast amounts of information, hoping to extract valuable insights that can drive innovation, improve products, and inform strategic decisions. However, simply observing correlations between different data points is often insufficient. To truly understand why things happen, and to predict the impact of interventions, we need to move beyond mere association and delve into the world of causal inference. Causal inference is the process of determining whether a cause-and-effect relationship exists between variables, and quantifying the magnitude of that effect. It’s the bedrock upon which robust technological advancements and data-driven strategies are built.

While often discussed in academic circles, the principles of causal inference are increasingly vital for anyone working with data in the tech industry. From optimizing user experience in a software application to understanding the effectiveness of a new AI algorithm, the ability to make sound causal judgments can be the differentiator between a mediocre outcome and a game-changing success. This article will explore what causal inferences are, why they are crucial in technology, and the fundamental approaches used to achieve them.
The Fundamental Difference: Correlation vs. Causation
The most common pitfall in data analysis is confusing correlation with causation. Correlation simply means that two variables tend to move together. For example, as ice cream sales increase, so does the number of drownings. This is a strong correlation, but clearly, eating ice cream does not cause drowning, nor does drowning cause ice cream sales. The underlying factor driving both is likely a third variable: hot weather. When temperatures rise, people buy more ice cream and more people swim (and unfortunately, some drown).
Causal inference, on the other hand, aims to establish a direct link: if we change variable A, will variable B change as a direct consequence? In our ice cream example, a causal inference question would be: if we were to ban ice cream sales on a hot day, would the number of drownings decrease?
Understanding Confounding Variables
The ice cream and drowning example highlights the critical concept of confounding variables. A confounder is a variable that influences both the independent variable (the presumed cause) and the dependent variable (the presumed effect), creating a spurious association. In technological contexts, confounding variables can be subtle and pervasive. For instance, a new feature implemented in a mobile app might coincide with an increase in user engagement. However, if the launch of this feature also coincided with a significant marketing campaign, it becomes difficult to attribute the increased engagement solely to the new feature. The marketing campaign is a confounder.
The Importance of Establishing Causality
In the tech industry, mistaking correlation for causation can lead to disastrous decisions. Imagine a scenario where a product team observes that users who spend more time on a particular onboarding screen have higher retention rates. They might conclude that extending the time spent on this screen causes better retention and proceed to lengthen it. However, it’s possible that users who are already more engaged and invested in the product naturally spend more time on onboarding, and their higher retention is due to their pre-existing engagement, not the duration of the onboarding itself. This could lead to a product change that frustrates engaged users without actually improving retention.
Causal inference allows us to move beyond such superficial observations. It enables us to:
- Understand the true drivers of behavior: Why do users churn? Why does a particular marketing campaign succeed? Why does a specific algorithm perform better than another?
- Make effective interventions: If we want to increase user engagement, what specific changes will actually lead to that outcome? If we want to improve system performance, what is the root cause of the bottleneck?
- Build reliable models: Predictive models built on spurious correlations are fragile and can fail spectacularly when conditions change. Models grounded in causal understanding are more robust and interpretable.
- Develop ethical AI: Understanding causal relationships is paramount for building AI systems that are fair, unbiased, and do not perpetuate harmful societal dynamics. For example, an AI system trained on biased historical data might incorrectly infer a causal link between certain demographic attributes and creditworthiness, leading to discriminatory outcomes.
Methods for Drawing Causal Inferences
Establishing causality is inherently more challenging than identifying correlations. It often requires designing experiments or employing sophisticated statistical techniques to isolate the effect of the variable of interest.
Randomized Controlled Trials (RCTs) – The Gold Standard
The most robust method for establishing causal inference is the Randomized Controlled Trial (RCT), often referred to as A/B testing in the tech world. In an RCT, participants are randomly assigned to one of two or more groups: a treatment group that receives the intervention (e.g., a new feature, a different UI design) and a control group that does not. Because participants are randomly assigned, any differences in outcomes between the groups are, in theory, attributable to the intervention, as randomization helps to balance out any potential confounding variables across the groups.
In Practice for Tech:
- A/B Testing: This is the ubiquitous application of RCTs in tech. Websites and apps are split into different versions (A and B), and users are randomly shown one version. Metrics like click-through rates, conversion rates, or time spent are compared to determine which version is causally superior.
- Multivariate Testing: An extension of A/B testing where multiple elements on a page are varied simultaneously, allowing for the testing of complex interactions.
- Personalization Engines: These systems often use randomized assignments to test different personalization strategies and determine which ones causally lead to increased user engagement or conversion.
Observational Studies and Quasi-Experimental Methods
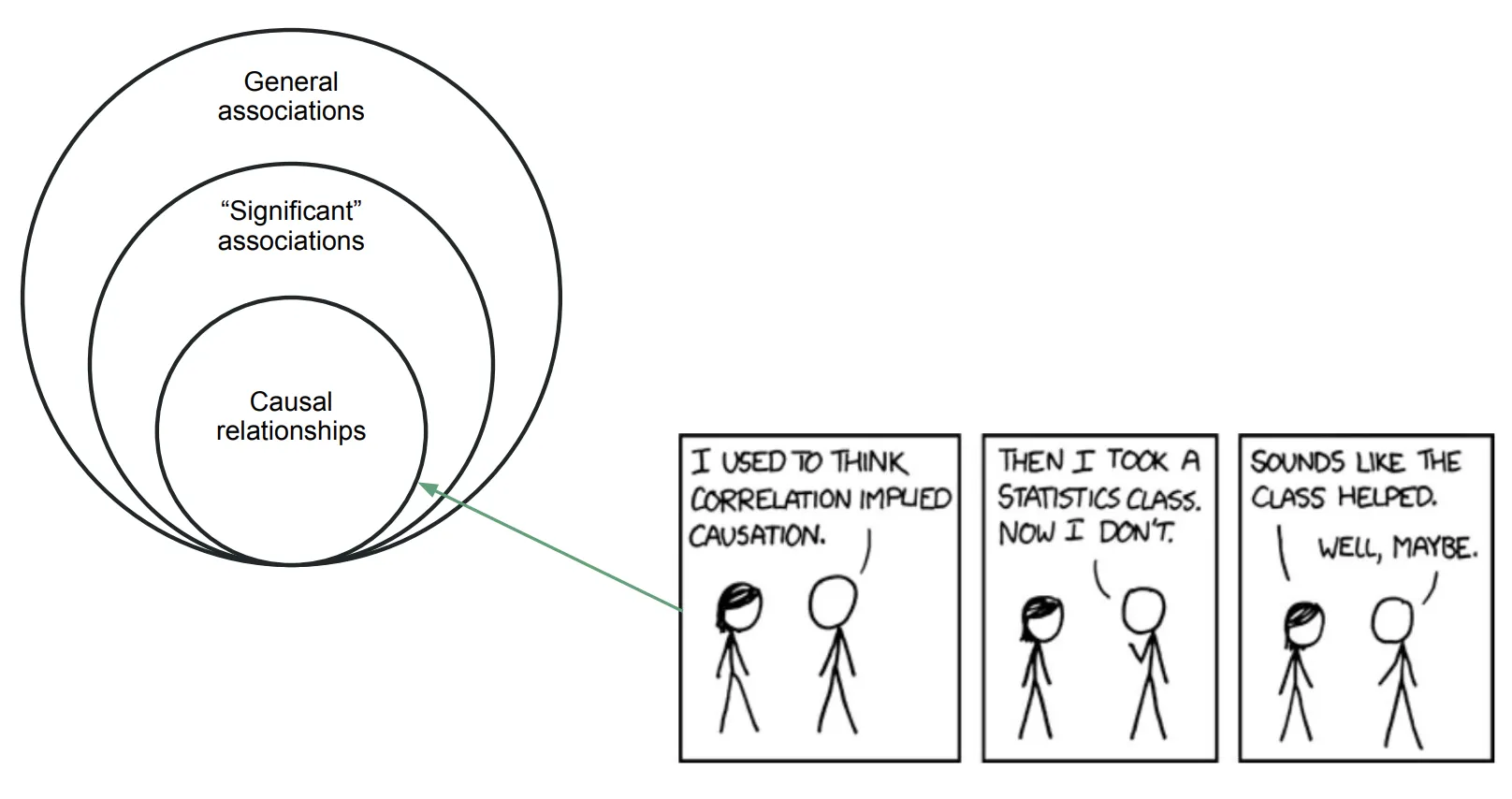
While RCTs are ideal, they are not always feasible due to ethical, logistical, or cost constraints. In such cases, researchers and data scientists rely on observational studies, where data is collected without direct intervention. Here, the challenge is to control for confounding variables statistically. Quasi-experimental methods are used when randomization is not possible but the researcher can still find or create situations that mimic an experiment.
Key Observational and Quasi-Experimental Techniques:
- Regression Discontinuity Design (RDD): This method is used when a treatment or intervention is assigned based on a cutoff score or threshold. For example, if a software update is rolled out to users whose account creation date is after a certain point, RDD can be used to estimate the causal effect of the update by comparing users just above and just below the cutoff.
- Difference-in-Differences (DiD): This technique is employed when there’s a treatment and a control group, and data is collected before and after the treatment is applied. DiD compares the change in outcomes in the treatment group to the change in outcomes in the control group over the same period. This helps to account for general trends that might affect both groups. For instance, if a new pricing model is introduced for a subset of users, DiD can assess its causal impact on spending by comparing the change in spending for this subset versus a similar subset not affected by the new pricing.
- Propensity Score Matching (PSM): In PSM, individuals in the treatment group are matched with individuals in the control group who have a similar probability (propensity score) of receiving the treatment, based on a set of observed covariates. This creates a pseudo-randomized sample, allowing for a more valid causal inference from observational data. This is useful when we observe that users who opt into a new beta program (treatment) have higher engagement than those who don’t (control), but we need to account for factors like their prior usage patterns.
- Instrumental Variables (IV): This method is used when there is an unobserved confounder affecting both the treatment and the outcome. An instrumental variable is a variable that influences the treatment but does not directly affect the outcome, and is not affected by the unobserved confounder. Finding a valid instrumental variable can be challenging but powerful.
- Causal Graphs (Directed Acyclic Graphs – DAGs): DAGs provide a visual representation of assumed causal relationships between variables. They help researchers identify potential confounders and determine the appropriate statistical methods to use for causal inference. In complex tech systems with many interacting components, DAGs can be invaluable for mapping out potential causal pathways and understanding the systemic impact of changes.
The Role of Machine Learning in Causal Inference
While traditional statistical methods are foundational, machine learning is increasingly being integrated into causal inference frameworks. ML algorithms can excel at identifying complex non-linear relationships and can be used to model treatment effects, estimate propensity scores more effectively, and even discover potential causal relationships from large datasets.
ML-Powered Causal Inference Approaches:
- Meta-Learners (e.g., T-learner, S-learner, X-learner): These are frameworks that leverage base machine learning models to estimate heterogeneous treatment effects – how the effect of an intervention varies across different individuals or subgroups.
- Causal Discovery Algorithms: These algorithms aim to infer causal structures from observational data without prior assumptions. While still an active area of research, they hold promise for uncovering novel causal relationships in complex systems.
- Counterfactual Reasoning with Deep Learning: Advanced deep learning models are being developed to estimate counterfactual outcomes – what would have happened if a different decision had been made. This is crucial for causal inference, as it directly addresses the “what if” nature of causality.
Challenges and Considerations in Causal Inference
Despite the power of these methods, drawing accurate causal inferences is fraught with challenges.
Data Quality and Availability
The accuracy of any causal inference heavily relies on the quality and completeness of the data. Missing data, measurement errors, and biases in data collection can all lead to flawed conclusions. In tech, data often comes from disparate sources (logs, user databases, analytics platforms), and integrating and cleaning it for causal analysis is a significant undertaking.
Assumptions and Validity
All causal inference methods, especially those relying on observational data, are built upon a set of assumptions. The validity of the inference depends critically on these assumptions holding true. For example, RDD assumes that individuals just above and below the cutoff are otherwise comparable. DiD assumes that the trends in the control group would have mirrored the trends in the treatment group in the absence of the treatment (the parallel trends assumption). Violations of these assumptions can lead to biased estimates.
Generalizability (External Validity)
Findings from a specific experiment or observational study might not generalize to other contexts, populations, or time periods. A causal relationship observed in one user segment or on one platform might not hold true elsewhere. It’s crucial to consider the scope and limitations of the causal claims being made.
Interpretation and Communication
Causal inferences are often complex and require careful interpretation. Communicating these findings effectively to stakeholders who may not have a deep statistical background is vital for ensuring that the insights lead to actionable, data-driven decisions. Overstating causal claims or misrepresenting the strength of evidence can be as damaging as drawing no causal inference at all.

Conclusion: The Future is Causal
In the dynamic landscape of technology, the ability to move beyond mere correlation and establish robust causal inferences is no longer a niche skill but a fundamental requirement for success. Whether optimizing a user interface, developing a groundbreaking AI model, or understanding the intricate dynamics of a complex system, causal inference provides the clarity and confidence needed to make informed decisions.
By embracing methods ranging from the rigor of randomized controlled trials to the sophisticated statistical techniques for observational data, and by leveraging the power of machine learning, tech professionals can unlock deeper insights and drive more meaningful innovation. As data becomes even more pervasive and systems more complex, the importance of mastering causal inference will only continue to grow, shaping the future of technology in profound ways.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.