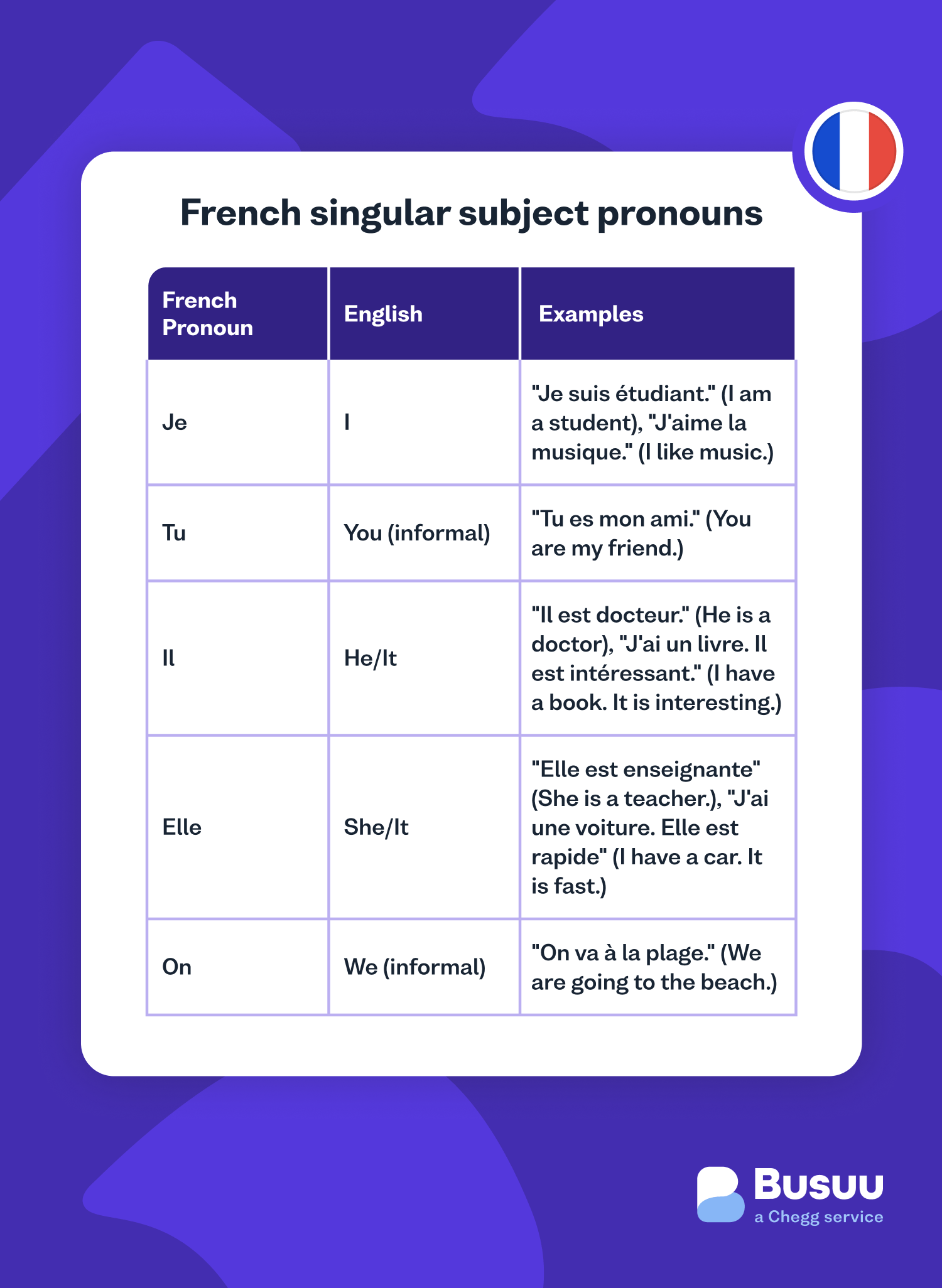
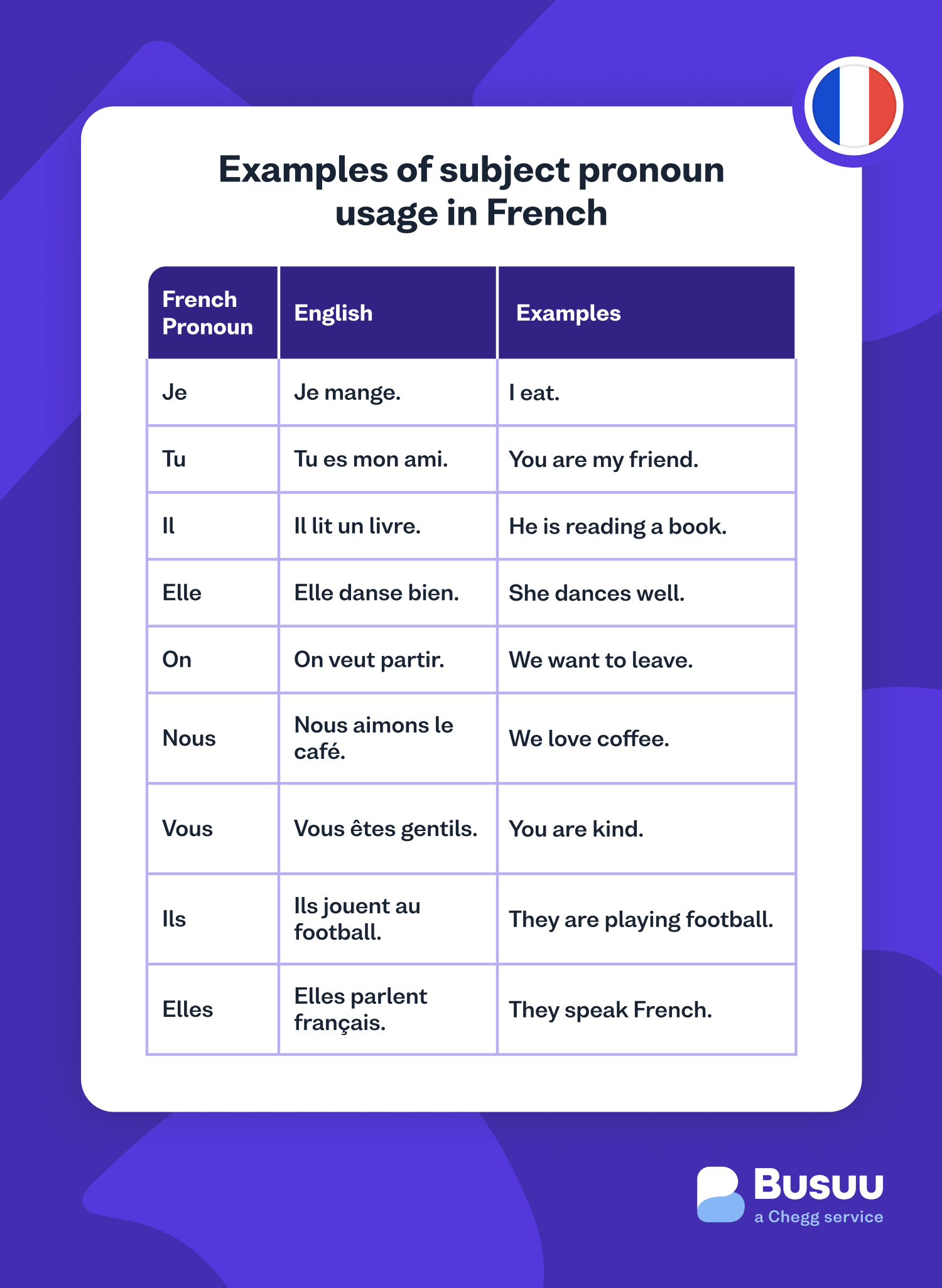
In the realm of global software development and artificial intelligence, translation is often misunderstood as a simple 1:1 swap of vocabulary. However, for developers, data scientists, and localization experts, the query “what does ‘we’ mean in French” represents a sophisticated challenge in Natural Language Processing (NLP). In English, the word “we” is a versatile, stable first-person plural pronoun. In French, “we” is a shifting target, split primarily between the formal nous and the ubiquitous, informal on.
Solving this ambiguity is not just a linguistic curiosity; it is a core hurdle in creating seamless AI-driven user interfaces, chatbot interactions, and automated content generation. As we delve into the technology behind French localization, we see how modern tech stacks are moving beyond simple dictionaries toward context-aware semantic engines.
The Computational Complexity of the French “We”: Nous vs. On
From a software engineering perspective, a pronoun is a variable. In English, the variable we remains constant regardless of the social context. In French, the application must choose between two distinct outputs based on metadata that isn’t always present in the source text. This is the first layer of the “French We” problem in tech.
Contextual Neural Mapping
Traditional rule-based translation systems struggled with the “we” dilemma because they lacked the ability to “see” the broader context. Modern NLP models utilize Neural Machine Translation (NMT) to perform contextual mapping. When an AI encounters “we,” it doesn’t just look at the word; it analyzes the surrounding “context window”—the words before and after.
If the software detects a formal register—such as words like “agreement,” “shareholders,” or “formalize”—the algorithm assigns a higher probability weight to nous. If the data set includes slang, contractions, or casual syntax, the model pivots to on. This real-time probabilistic calculation is what allows modern apps to feel “native” to a French user.
Machine Learning and the Formal-Informal Divide
Machine Learning (ML) models are trained on massive corpora of text. The difficulty in translating “we” into French stems from the disparity between written and spoken data. Nous is the standard in written literature and formal documentation, while on is used in roughly 90% of casual French conversation.
For developers building Voice User Interfaces (VUIs) like Alexa or Siri, the tech must be tuned to favor on to avoid sounding robotic. Conversely, a FinTech app generating a PDF statement must default to nous to maintain professional credibility. Managing these “style tokens” within a machine learning model is a primary focus for engineers working on French-language localization.
Architectures of Accuracy: How Modern NMT Models Process French Nuance
To understand how a machine answers “what does ‘we’ mean in French,” we must look under the hood at the architectures driving the translation. The transition from Statistical Machine Translation (SMT) to Neural Machine Translation (NMT) has been the most significant leap in this field.
Transformer Models and the Attention Mechanism
The “Transformer” architecture, which powers models like GPT-4 and Google’s T5, uses an “attention mechanism.” This allows the model to give different levels of importance to different parts of the input text. When translating a sentence starting with “We are excited to announce,” the attention mechanism looks at the verb and the overall tone of the sentence.
Because French verbs must be conjugated differently for nous (e.g., nous sommes) and on (e.g., on est), the “we” translation is a foundational decision that dictates the entire grammatical structure of the output string. The attention mechanism ensures that if the model chooses on, it doesn’t accidentally use a nous verb ending, a common “hallucination” in older tech.
Corpus Data and Training Biases
The “we” problem is also a data problem. If an AI is trained primarily on European Union parliamentary transcripts (a common source for open-source translation data), it will almost always translate “we” as nous. This creates a “formal bias.”
Tech companies are now diversifying their training sets to include “low-resource” conversational data. By scraping web forums, movie subtitles, and social media, developers can train models to understand that “we” in a gaming app chat should almost certainly be on, whereas “we” in a legal disclaimer must be nous. This balance is achieved through “fine-tuning,” where a pre-trained model is further educated on a specific niche dataset.
The Developer’s Toolkit: Implementing AI Translation in Software
For those building the next generation of global apps, handling the French “we” requires more than just calling an API. It requires a robust localization (L10n) and internationalization (i18n) strategy.
API Integration for Multi-lingual Apps
Modern developers rarely build translation engines from scratch. Instead, they integrate high-level APIs like DeepL, Google Cloud Translation, or AWS Translate. These services have become increasingly “smart” about the French on/nous distinction.
When using these APIs, developers can often pass “formality” parameters. For example, the DeepL API allows a formality flag in its JSON request. By setting this to less, the developer programmatically instructs the engine to favor on for “we,” ensuring that a mobile app feels friendly and accessible to a younger French demographic.
Dynamic Localization Frameworks
Static translation files (like .json or .po files) are becoming obsolete for dynamic content. Modern frameworks like i18next or Phrase allow for “dynamic keys.” In these systems, a single English string for “We are here” can be mapped to different French outputs depending on the user’s profile settings.
If a user selects “Casual Mode” in an app’s settings, the software logic can swap the translation key from a nous-based string to an on-based string. This level of granular control is how tech companies maintain brand voice across different cultures without losing the nuances of the local language.
Beyond Text: AI Voice Synthesis and the Auditory “We”
The challenge of “what does ‘we’ mean in French” extends into the auditory realm. Text-to-Speech (TTS) and Speech-to-Text (STT) technologies must handle the phonetic shifts that occur when “we” changes from nous to on.
Prosody and Intonation in French Speech AI
The word on is phonetically simpler than nous, but it often leads to “liaisons”—where the silent end of one word links to the start of the next. AI voice synthesis must be sophisticated enough to know that if “we” is translated as on, the following verb’s pronunciation might change.
Sophisticated synthesis models use WaveNet or Tacotron architectures to generate human-like speech. These models are trained to recognize that the “we” represented by on usually implies a faster, more fluid speech pattern, whereas nous implies a more deliberate, rhythmic cadence. Software that ignores this distinction sounds “uncanny” to native French speakers.
Decentralized Translation APIs for Developers
We are seeing a move toward “Edge AI,” where translation happens on the device rather than the cloud. For mobile developers, this means utilizing CoreML (Apple) or TensorFlow Lite (Google) to run translation models locally. This reduces latency but requires highly optimized, “shrunken” models that can still understand the nuances of French pronouns without the brute-force processing power of a massive server farm.
The goal for these on-device models is “semantic parity”—ensuring that the meaning of “we” remains intact even when the computational resources are limited.
The Future of Linguistic Tech: From Translation to Transcreation
As we look toward the future, the question “what does ‘we’ mean in French” will be answered by “transcreation” engines. Transcreation goes beyond literal translation; it re-imagines the content for the target culture.
AI-Driven Cultural Adaptation
Future AI models will not just ask “which pronoun is correct?” They will ask “which pronoun will achieve the desired user behavior?” In a marketing tech (MarTech) context, an AI might A/B test whether nous or on leads to higher conversion rates on a “Join We” (Rejoignez-nous) button.
The tech is moving toward a reality where “we” is treated as a cultural concept rather than a grammatical one. Large Language Models (LLMs) are already capable of rewriting entire paragraphs to better suit the collective spirit of the French on, which often functions as an “everyone” or “one” rather than just a plural “I.”

The Role of Human-in-the-Loop (HITL)
Despite the power of AI, the “Human-in-the-Loop” (HITL) remains essential in high-stakes tech environments. Professional localization workflows use “Translation Management Systems” (TMS) that flag ambiguous pronouns for human review. If an AI is unsure whether a “we” should be formal or informal, it generates a “low confidence” score, triggering a notification for a human editor. This hybrid approach ensures that the technology remains accurate while scaling at the speed of the digital economy.
In conclusion, “what does ‘we’ mean in French” is a gateway into the complex world of linguistic technology. It highlights the shift from rigid code to fluid, context-aware AI. For the tech industry, mastering these nuances is the key to building software that doesn’t just speak French but truly understands it.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.