In the traditional sense, a falsetto is a vocal register occupying the frequency range just above the modal voice, characterized by a lighter, breathier timbre and a specific physiological vibration of the vocal ligament. However, in the rapidly evolving landscape of technology, the term “falsetto” has transcended music theory to become a critical benchmark in digital signal processing (DSP), artificial intelligence, and synthetic voice modeling. As we push the boundaries of how machines communicate, understanding and replicating the complexities of the human falsetto has become a frontier for software engineers and AI researchers alike.

This article explores the technical architecture of the falsetto register, the challenges of digital synthesis, and how modern AI tools are redefining the “upper register” of human-computer interaction.
The Bio-Acoustics of Falsetto in the Digital Age
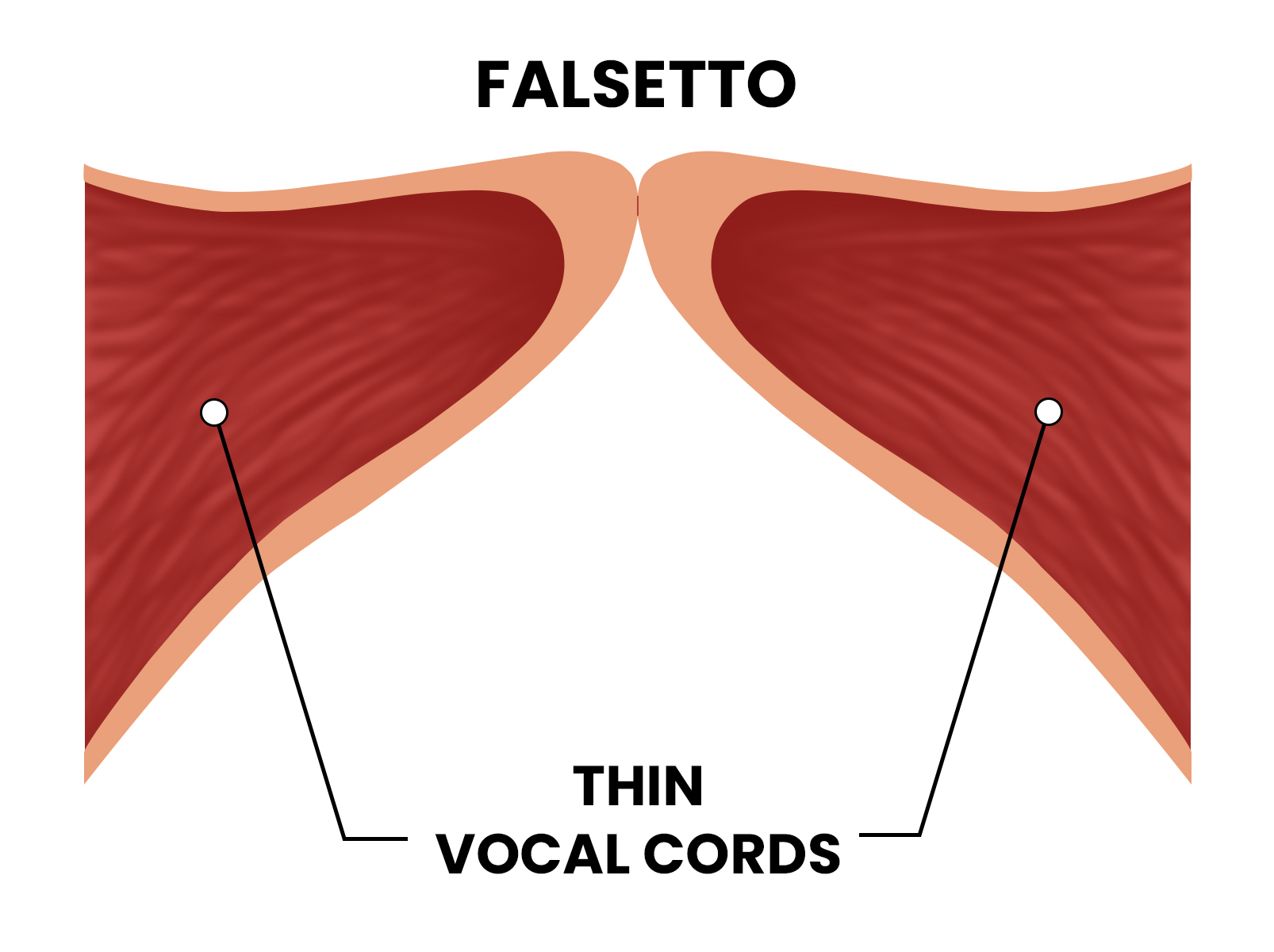
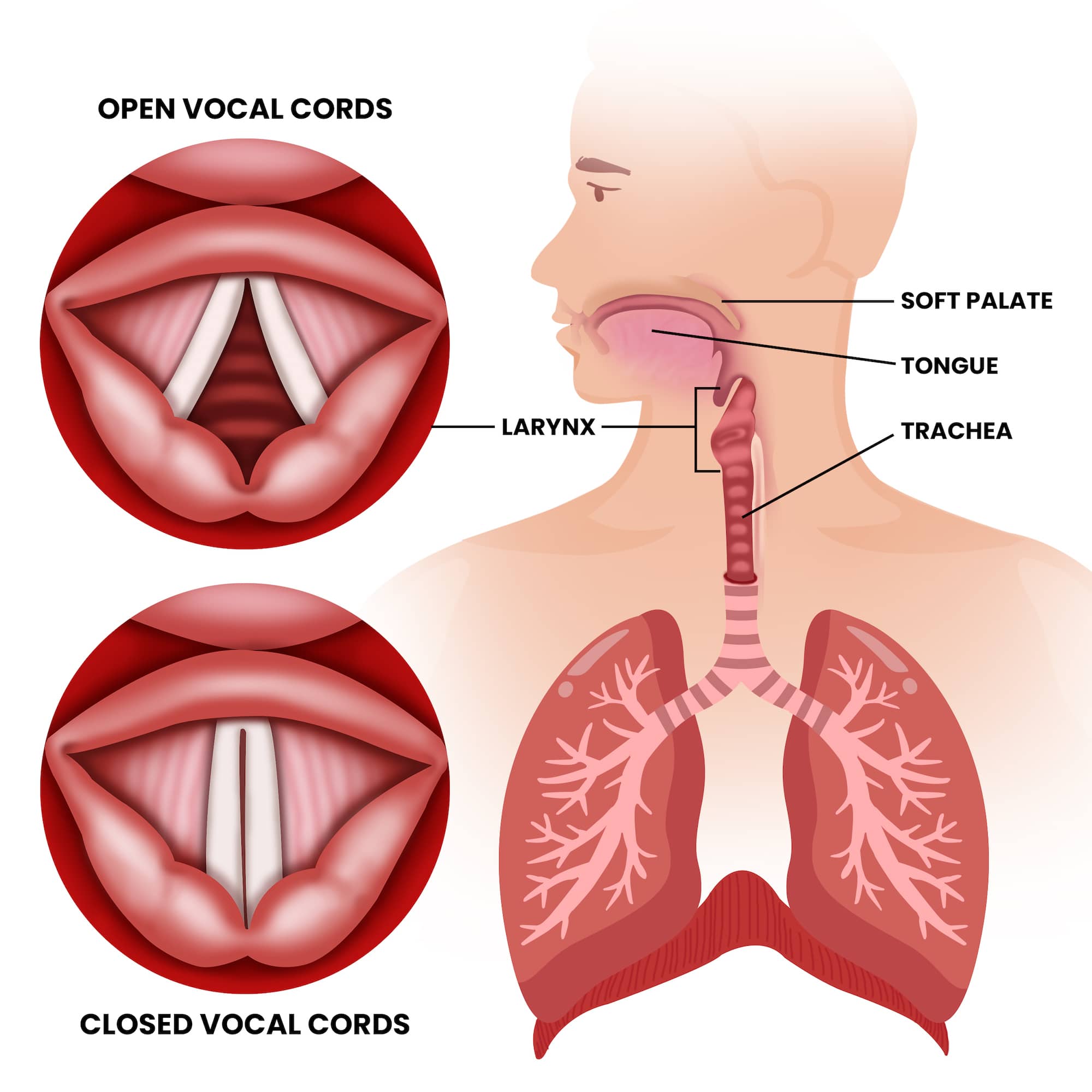
To understand how technology replicates the falsetto, one must first understand the data points that define it. Unlike the chest voice, where the vocal folds vibrate in their entirety, the falsetto occurs when only the ligamentous edges of the vocal folds vibrate. From a technical perspective, this creates a specific waveform pattern that is significantly different from standard speech.
Understanding the Vocal Fold Dynamics and Data Modeling
In the realm of vocal synthesis and software engineering, the falsetto is modeled as a “high-tension” state. When a developer builds a voice model, they must account for the reduction in harmonic complexity that occurs in this register. The falsetto produces fewer overtones than the modal voice, resulting in a purer sine-wave-like appearance on a spectrograph. Mapping these dynamics requires high-resolution sampling and an understanding of glottal flow—the air that passes through the vocal folds.
Digital models utilize “Source-Filter Theory,” where the glottal source (the vibration) is filtered by the vocal tract. To simulate a falsetto, software must adjust the “source” to reflect a higher fundamental frequency ($F0$) while simultaneously dampening certain resonant frequencies ($F1$ and $F_2$) to achieve that signature “hollow” digital timbre.
The Digital Challenge of High-Frequency Modeling
One of the primary hurdles in audio technology is “aliasing”—the distortion that occurs when a signal is sampled at an insufficient rate. Because the falsetto occupies a higher frequency spectrum, capturing its nuances requires a higher Nyquist frequency. For professional-grade AI voice tools, this means processing audio at 48kHz or even 96kHz to ensure that the subtle airiness (noise component) of the falsetto isn’t lost or compressed into digital artifacts.
Engineers focus on “spectral tilt,” which describes how the energy of a voice drops off at higher frequencies. A falsetto has a much steeper spectral tilt than a speaking voice. In the tech world, mastering this tilt is the difference between a voice that sounds like a human singing and a voice that sounds like a synthesized beep.
AI and the Replication of the Human Upper Register
The rise of Generative AI has shifted the conversation from simple “pitch shifting” to “neural synthesis.” In the past, creating a falsetto in software involved merely stretching a waveform, which often resulted in a “chipmunk effect.” Today, Neural Networks are trained on thousands of hours of human vocal data to understand the biological transitions between registers.
Neural Networks and Pitch Modulation
Modern Large Language Models (LLMs) and Diffusion Models for audio, such as those used by ElevenLabs or OpenAI’s Voice Engine, treat the falsetto as a specific “latent state.” By using Variational Autoencoders (VAEs), these systems can identify the exact point where a speaking voice should transition into a falsetto.
This transition is technically known as the “passaggio.” For an AI to sound natural, it must simulate the slight instability and change in air pressure that occurs during this shift. Developers use “pitch-invariant features” to ensure that as the frequency rises into the falsetto range, the identity of the speaker remains recognizable. This is a massive leap in digital security and biometric tech, as it allows for more robust voice-ID systems that can recognize a user even if they are whispering or using their upper register.
Overcoming the “Uncanny Valley” in High-Pitch Synthesis
The “Uncanny Valley” refers to the point where a digital creation is almost—but not quite—human, causing a sense of unease in the user. In audio tech, the falsetto is often where the Uncanny Valley is most prominent. Because the falsetto is so breathy, it requires a sophisticated “stochastic” (random) noise generator to be layered over the pitch.
If the noise is too rhythmic, it sounds like static; if it is too random, it sounds like white noise. Modern AI audio workstations use “Generative Adversarial Networks” (GANs) where one part of the AI creates the falsetto sound and the other part critiques it, forcing the system to produce a result that is indistinguishable from a human recording.
Applications in Modern Music Production Software
Beyond the theory of AI, the “what is a falsetto” question is answered daily through the tools used by music producers and sound designers. The integration of falsetto-specific algorithms has revolutionized the way we consume and create digital media.
Real-time Pitch Shifting and Formant Correction
Tools like Antares Auto-Tune and Celemony Melodyne have evolved to include “Formant Preservation.” When a singer’s voice is pushed into a falsetto range via software, the “formant” (the physical size of the virtual throat) must stay the same to avoid sounding artificial.
In a tech context, this involves complex Fast Fourier Transform (FFT) algorithms that separate the pitch from the timbre. This allows producers to take a baritone vocal track and digitally re-synthesize it into a flawless falsetto. This technology is now being integrated into real-time communication tools, allowing for “voice skins” in gaming and virtual reality where a user’s voice can be transposed into any register instantly.
Virtual Vocalists: From Vocaloid to Generative AI
The evolution of virtual vocalists like Hatsune Miku (Vocaloid) showcased the early attempts at digital falsetto. These systems used “concatenative synthesis,” stringing together tiny snippets of recorded audio. However, the result was often robotic.
The current tech trend has moved toward “End-to-End” (E2E) speech synthesis. Software like Suno or Udio can now generate entire songs, including complex falsetto riffs, from a text prompt. This is achieved through “Transformer” architectures—the same technology behind ChatGPT—which predict the next “audio token” based on the emotional context of the lyrics. If the prompt implies vulnerability or height, the AI selects tokens that correspond to the falsetto frequency range.
The Future of Synthetic Falsetto in Interface Design
As we move toward a future dominated by Ambient Intelligence and Voice-First interfaces, the technical mastery of vocal registers like the falsetto will play a pivotal role in User Experience (UX).
Enhancing User Experience through Vocal Nuance
Why does a tech company care about falsetto? Because humans use register shifts to communicate emotion. A voice assistant that can subtly shift its tone—perhaps using a lighter, falsetto-adjacent register to indicate a soft notification—feels more empathetic and less intrusive.
This is known as “Prosody Modeling.” In the next generation of smart home devices, the “falsetto” won’t just be for singing; it will be a tool for nuance. Engineers are working on “Emotional Text-to-Speech” (ETTS) that can use the upper register to convey excitement, surprise, or gentleness, making the digital interaction feel more personal and less transactional.
Ethical Considerations in AI Voice Mimicry
The ability to perfectly replicate a human’s falsetto brings significant technical and ethical challenges. Deepfake technology has reached a point where the “breathiness” and “soul” of a falsetto can be mimicked to commit fraud or spread misinformation.
In response, the tech industry is developing “Audio Watermarking.” This involves embedding high-frequency data—often hidden within the falsetto range where the human ear is less sensitive to digital artifacts—that identifies a voice as AI-generated. Digital security firms are now using these “spectral signatures” to verify the authenticity of audio in an era where the line between biological falsetto and digital synthesis has completely blurred.
In conclusion, “falsetto” in the modern world is no longer just a term for choir directors. It is a complex data set, a challenge for neural network training, and a vital component of the next wave of human-centric technology. Whether it is being used to create a virtual pop star or to make a voice assistant sound more human, the digital falsetto represents the peak of our ability to map the intricacies of human expression onto a silicon canvas.
aViewFromTheCave is a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to Amazon.com. Amazon, the Amazon logo, AmazonSupply, and the AmazonSupply logo are trademarks of Amazon.com, Inc. or its affiliates. As an Amazon Associate we earn affiliate commissions from qualifying purchases.